Slides 📊
9.8. Confidence Intervals and Bounds When σ is Unknown
So far, we developed confidence regions under the simplifying but unrealistic assumption that the population standard deviation \(\sigma\) is known. In practice, we rarely know \(\sigma\) and must estimate it.
This creates a fundamental challenge. Using a sample standard deviation \(S\) in place of the unknown \(\sigma\) introduces additional uncertainty that must be accounted for. The standard normal distribution is no longer appropriate because it does not capture this extra layer of uncertainty.
The solution to this problem comes from a distribution developed by William Sealy Gosset in the early 1900s: the Student’s t distribution.
Road Map 🧭
Recognize that in most practical scenarios, \(\sigma\) is unknown and must be estimated by \(S\).
Understand that when \(S\) replaces \(\sigma\), the new pivotal quantity follows a t-distribution.
Derive confidence intervals and bounds based on the new t-distribution.
Understand the basic properties of t-distributions.
Learn what it means for a statistical procedure to be robust. Recognize the requirements for t-based procedures to be robust.
9.8.1. William Gosset and the Birth of Student’s t-Distribution

Fig. 9.8 William S. Gosset (1876-1937)
In 1908, William Sealy Gosset, a chemist and statistician employed by the Guinness brewery in Dublin, Ireland, published a paper titled “The Probable Error of a Mean” in the journal Biometrika. Due to Guinness company policy that prohibited employees from publishing their research, Gosset published under the pseudonym “Student”—leading to the now-famous Student’s t-distribution.
Gosset’s work at Guinness involved quality control for beer production. He needed statistical methods that worked reliably with small samples, as testing large quantities of beer would have been wasteful. Specifically, he faced the challenge of making inferences about a population mean when the population standard deviation was unknown and had to be estimated from the same limited sample.
His mathematical solution—the t-distribution—accounts for the added uncertainty of estimating \(\sigma\) with \(S\). This breakthrough has become one of the most widely used statistical tools across virtually all fields of scientific inquiry.
9.8.2. The t-Statistic and Its Distribution
To construct confidence regions, we have so far relied on the fact that the pivotal quantity \(\frac{\bar{X}-\mu}{\sigma/\sqrt{n}}\) follows a standard normal distribution under certain assumptions. When the unknown \(\sigma\) is replaced by its estimator \(S\), however, the resulting statistic
no longer follows a standard normal distribution. Instead, it follows a t-distribution.
The t-distribution is a family of continuous distributions parameterized by \(\nu\) (Greek letter “nu”; also called the degrees of freedom or df). A t-statistic constructed using a sample of size \(n\) has \(\nu = n-1\). The subscript in \(T_{n-1}\) reflects this fact, although it is often omitted when the context makes it clear or when the detail is unnecessary.
Standardization, Studentization, and Pivotal Quantity
So far, we have called the transformation of a general random variable \(X\) into \(\frac{X-\mu_X}{\sigma_X}\) the standardization of \(X\). When the sample standard deviation \(S_X\) is used instead of \(\sigma_X\), giving
we call this the studentization of \(X\).
Both transformations are variants of pivotal quantities, which are functions of \(X\) constructed so that their distributions do not depend on the unknown parameters of \(X\).
Properties of t-Distributions
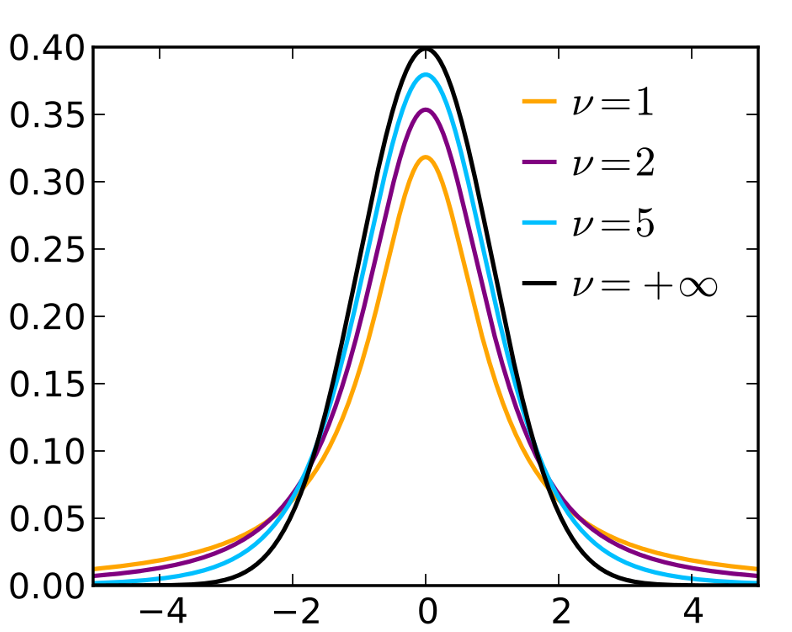
Fig. 9.9 t-densities with various degrees of freedom; the curve corresponding to \(+\infty\) is the standard normal PDF.
A t-distribution is symmetric around zero, similar to the standard normal distribution.
It has heavier tails than the standard normal distribution, reflecting the additional uncertainty from estimating \(\sigma\). This means that a t-distribution is always more spread out than the standard normal distribution for any finite degrees of freedom.
The smaller the sample size, the heavier the tails. The distribution approaches the standard normal distribution as the degrees of freedom increase.
The PDF of a t-distribution
The probability density function of a t-distribution is given by:
Where \(\Gamma\), the gamma function, is a generalization of the factorial function. Just like normal distributions, we rely on tables or software to compute probabilities and percentiles involving t-distributions.
9.8.3. Deriving t-Based Confidence Regions
Preliminaries and Assumptions
The derivation of t-based confidence intervals requires a similar set of assumptions as before. The only difference is that \(\sigma\) is now unknown.
The data \(X_1, X_2, \cdots, X_n\) must be an iid sample from a population with mean \(\mu\) and variance \(\sigma^2.\)
Either the population is normally distributed, or we have sufficiently large \(n\) for the CLT to hold.
Both \(\mu\) and \(\sigma\) are unknown.
We also need to define the t-critical values. A t-critical value, denoted \(t_{\alpha/2, \nu}\), is the point on the t-distribution with \(\nu\) degrees of freedom such that its upper-tail area equals \(\alpha/2\). The notation includes an additional subscript for the degrees of freedom, since its location also depends on the specific t-distribution on which it is defined.
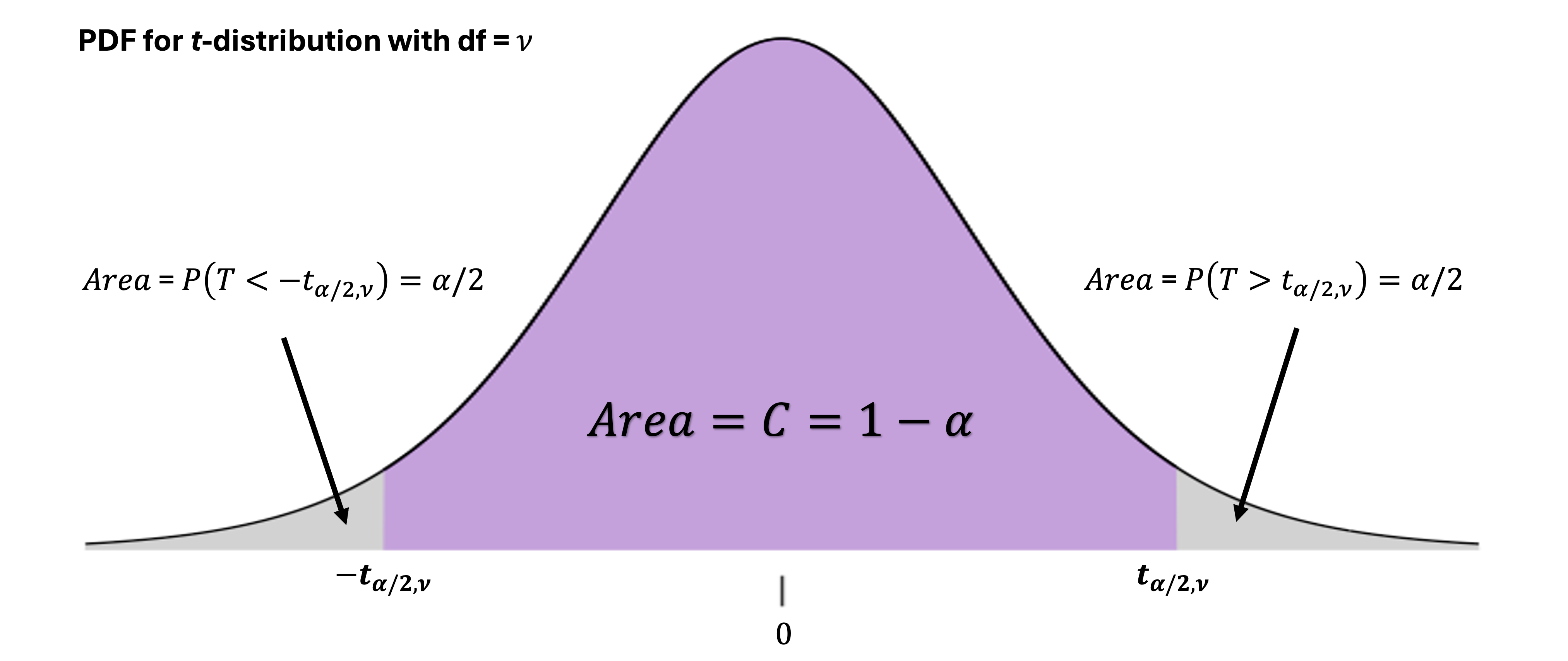
Derivation of the Confidence Interval
Similar to the case with known \(\sigma\), we derive a confidence interval for \(\mu\) using the pivotal method. For the degrees of freedom \(n-1\), the following statement is true by the definition of \(t_{\alpha/2, n-1}\):
Replace \(T_{n-1}\) with the new pivotal quantity:
Through algebraic pivoting, we isolate \(\mu\) to obtain:
Therefore, the \(C\cdot100\%\) confidence interval is:
Summary of t-Based Confidence Intervals and Bounds
We leave it to the reader to work out the details of deriving the upper and lower confidence bounds under a t-distribution. The results follow the same pattern as their \(z\) equivalents; the margin of error will be computed with a smaller critical value \(t_{\alpha, n-1}\) instead of \(t_{\alpha/2, n-1}\).
In summary, when we have \(\bar{x}\) and \(s\) from an observed sample, we use the following formulas to compute confidence regions.
Confidence Regions When \(\sigma\) Is Unknown |
|
|---|---|
Confidence Interval |
\[\bar{x} \pm t_{\alpha/2, n-1} \frac{s}{\sqrt{n}}\]
|
Lower Confidence Bound |
\[\bar{x} - t_{\alpha, n-1} \frac{s}{\sqrt{n}}\]
|
Upper Confidence Bound |
\[\bar{x} + t_{\alpha, n-1} \frac{s}{\sqrt{n}}\]
|
Example 💡: Cholesterol Reduction Study
A pharmaceutical company is testing a new drug designed to lower LDL cholesterol levels. In a clinical trial, 15 patients with high cholesterol received the drug for eight weeks, and the reduction in their LDL cholesterol (in mg/dL) was measured.
The sample mean reduction was \(\bar{x} = 23.4\) mg/dL with a sample standard deviation of \(s = 6.8\) mg/dL. Construct a 95% confidence interval for the true mean reduction \(\mu\).
Step 1: Identify the key information
Sample size: \(n = 15\)
Sample mean: \(\bar{x} = 23.4\) mg/dL
Sample standard deviation: \(s = 6.8\) mg/dL
Confidence level: \(95\%\) (\(\alpha = 0.05\))
Degrees of freedom: \(\nu = n - 1 = 14\)
Step 2: Find the critical value
qt(0.025, df = 14, lower.tail=FALSE) # Returns 2.145
Step 3: Calculate the margin of error
Step 4: Construct the confidence interval
Interpretation: We are 95% confident that the true mean reduction in LDL cholesterol with this drug is captured by the region between 19.64 and 27.16 mg/dL.
9.8.4. The Effect of Sample Size on t-Confidence Regions
As with \(z\)-confidence regions, a large \(n\) makes \(t\)-confidence regions more precise in general. However, the ways in which \(n\) influences this phenomenon are more multifaceted for t-based methods:
A larger \(n\) reduces the true standard error, \(\sigma/\sqrt{n}\).
Although the true standard error is unknown, its estimator \(S/\sqrt{n}\) targets it more accurately with larger \(n\).
The critical value itself decreases as \(n\) increases, which further narrows the confidence region.
To see how the third point holds, see Fig. 9.10 below:
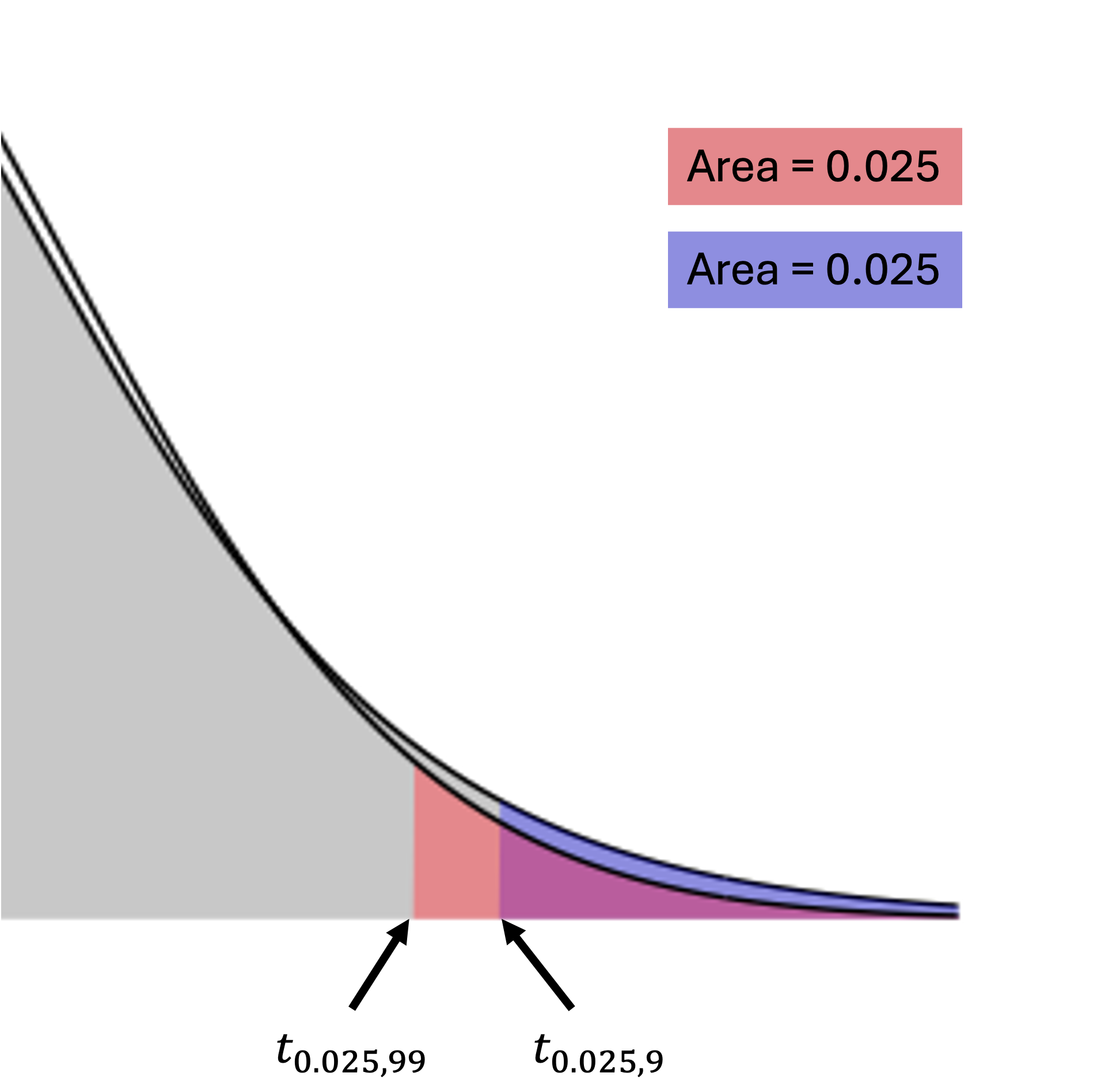
Fig. 9.10 Two-sided t-critical values for \(\alpha = 0.05\) with different degrees of freedom
In Fig. 9.10, the upper tails of two t-distributions are compared: one with \(df=n-1=99\) and the other with \(df=n-1=9\). Recall that higher degrees of freedom (and larger sample size) are associated with a lighter tail on a t-distribution. As \(n\) grows from 10 to 100, the difference in tail weight causes the critical value to move closer to the center (zero) in order to maintain an area of \(\alpha/2\) on its right.
In general, for the same confidence level and any two sample sizes \(n_1 < n_2\), it always holds that
A smaller critical value leads to a smaller margin of error if \(s\) is held constant, which in turn results in a more precise (narrower) confidence region. This relationship does not hold strictly in practice since \(S\) fluctuates with data, but the overall tendency remains.
Comparison with \(z\)-Confidence Regions
The above result implies that the \(z\)-confidence regions— which can loosely be considered t-confidence regions with an “infinite” dataset for sample variance computation—are more precise on average than their t-based parallels.
When is a \(t\)-Confidence Region Appropriate?
In practice, the true variance \(\sigma^2\) is rarely known, leaving t-procedures as our only option. On the rare occasions when \(\sigma^2\) is known, it is always preferable to use this true information.
9.8.5. Sample Size Planning When σ Is Unknown
Sample size planning is more challenging when \(\sigma\) is unknown. Suppose we want \(n\) such that
for some given maximum margin of error, \(ME_{max}\). By taking similar steps as in Chapter 9.3.2, we have
We now see that the problem is circular. To determine \(n\), we need the \(t\)-critical value, which depends on \(n\). Additionally, we need a value for \(s\), which we don’t have before collecting data. To address this issue, we use an iterative approach involving the following steps:
Obtain a planning value \(s_*\). This can be done by
Using \(s\) from a pilot study or previous research,
Making an educated guess based on the expected range, or
Using a conservative upper bound when uncertainty is high.
Update \(n\) iteratively.
Start with an initial guess using the \(z\)-critical value: \(n_0 = \left(\frac{z_{\alpha/2} s_*}{ME_{max}}\right)^2\).
Calculate the t-critical value using \(df = n_0 - 1\).
Recalculate \(n\) using the t-critical value.
Repeat until convergence.
This process typically converges quickly, often in just a few iterations.
9.8.6. Robustness of the \(t\)-Procedures
A statistical procedure is considered robust if it performs reasonably well even when its assumptions are somewhat violated. The \(t\)-procedures show good robustness against moderate departures from normality, especially as sample size increases.
Guidelines for Using t-Procedures When Normality May Not Hold |
|
|---|---|
\(n < 15\) |
The population distribution should be approximately normal. Check the sample data with normal probability plots. |
\(15 ≤ n < 40\) |
A \(t\)-procedure works well with some mild skewness. Avoid using with strongly skewed data or data containing outliers. |
\(n ≥ 40\) |
A \(t\)-procedure is generally reliable even with moderately skewed distributions, thanks to the Central Limit Theorem. |
Regardless of sample size, the procedure is sensitive to outliers, which can strongly influence both \(\bar{x}\) and \(s\). Always inspect your data for outliers before applying a \(t\)-procedure.
9.8.7. Bringing It All Together
Key Takeaways 📝
The Student’s t-distribution provides the appropriate framework for quantifying uncertainty about a population mean when the population standard deviation is unknown.
The pivotal quantity \(T_{n-1}= \frac{\bar{X}-\mu}{S/\sqrt{n}}\) now follows a t-distribution with \(n-1\) degrees of freedom.
The resulting confidence regions account for the additional uncertainty in estimating \(\sigma\), and are wider than their \(z\) parallels on average.
The t-procedures are robust to moderate violations of the normality assumption. The robustness grows with the sample size.
Exercises
A quality control engineer wants to estimate the mean tensile strength of steel cables. A sample of 25 cables yields a mean strength of 3450 N with a standard deviation of 120 N. Construct a 99% confidence interval for the mean strength.
A pilot study with 8 observations yielded a sample standard deviation of \(s = 15\). If a researcher wants to estimate the population mean with a margin of error of no more than 5 units at 95% confidence, how many observations should be planned for the full study?
Exercises: CI and Confidence Bounds (σ Unknown)
Learning Objectives 🎯
These exercises will help you:
Recognize when to use the t-distribution instead of the z-distribution
Find t-critical values for various confidence levels and degrees of freedom
Construct confidence intervals for μ when σ is unknown
Construct confidence bounds (UCB/LCB) when σ is unknown
Understand the relationship between t and z as df increases
Assess robustness of t-procedures to non-normality
Key Formulas 📐
Confidence Interval for μ (σ unknown):
Confidence Bounds (σ unknown):
Degrees of freedom: \(df = n - 1\)
R Functions:
# t-critical values
qt(alpha/2, df, lower.tail = FALSE) # For CI
qt(alpha, df, lower.tail = FALSE) # For bounds
# One-sample t-test with CI
t.test(x, conf.level = 0.95)
9.8.8. Exercises
Exercise 1: t-Distribution Properties
When do we use the t-distribution instead of the z-distribution for inference about μ?
What are the degrees of freedom for a one-sample t-procedure with sample size n?
How does the shape of the t-distribution compare to the standard normal? What causes this difference?
As degrees of freedom increase, what happens to the t-distribution?
Find \(t_{0.025, 15}\) and \(z_{0.025}\). Which is larger? Why?
Solution
Part (a): When to use t-distribution
Use the t-distribution when:
Making inference about the population mean μ
The population standard deviation σ is unknown and must be estimated by s
The underlying population is approximately normal (or n is large enough for CLT)
Part (b): Degrees of freedom
For a one-sample t-procedure: \(df = n - 1\)
Part (c): Shape comparison
The t-distribution is:
Symmetric and bell-shaped like the normal
Heavier tails than the standard normal (more probability in the extremes)
This occurs because using s instead of σ introduces additional uncertainty
Part (d): As df increases
As df → ∞, the t-distribution approaches the standard normal distribution.
Rule of thumb: By df ≈ 30, t-critical values are close to z-critical values for most practical purposes. By df ≈ 100, the difference is negligible.
Part (e): Comparing critical values
qt(0.025, 15, lower.tail = FALSE) # 2.131
qnorm(0.025, lower.tail = FALSE) # 1.960
\(t_{0.025, 15} = 2.131 > z_{0.025} = 1.960\)
The t-critical value is larger because the heavier tails of the t-distribution require going further from the center to capture 97.5% of the probability.
Exercise 2: Finding t-Critical Values
Find the t-critical value for each scenario using R or a t-table.
95% CI, n = 10
95% CI, n = 25
99% CI, n = 20
90% UCB, n = 15
95% LCB, n = 30
95% CI, n = 200 (compare to z-critical value)
Solution
Part (a): 95% CI, n = 10 (df = 9)
\(t_{0.025, 9} = 2.262\)
Part (b): 95% CI, n = 25 (df = 24)
\(t_{0.025, 24} = 2.064\)
Part (c): 99% CI, n = 20 (df = 19)
\(t_{0.005, 19} = 2.861\)
Part (d): 90% UCB, n = 15 (df = 14)
\(t_{0.10, 14} = 1.345\)
Part (e): 95% LCB, n = 30 (df = 29)
\(t_{0.05, 29} = 1.699\)
Part (f): 95% CI, n = 200 (df = 199)
\(t_{0.025, 199} = 1.972\) vs \(z_{0.025} = 1.960\)
Difference is only 0.012—practically identical.
R verification:
qt(0.025, 9, lower.tail = FALSE) # 2.262
qt(0.025, 24, lower.tail = FALSE) # 2.064
qt(0.005, 19, lower.tail = FALSE) # 2.861
qt(0.10, 14, lower.tail = FALSE) # 1.345
qt(0.05, 29, lower.tail = FALSE) # 1.699
qt(0.025, 199, lower.tail = FALSE) # 1.972
Exercise 3: Basic CI Construction (σ Unknown)
A chemical engineer measures the purity of a batch of pharmaceutical product. A random sample of n = 12 measurements yields:
Sample mean: \(\bar{x} = 98.45\%\)
Sample standard deviation: \(s = 1.23\%\)
Find the appropriate t-critical value for a 95% CI.
Calculate the estimated standard error.
Calculate the margin of error.
Construct the 95% confidence interval.
Interpret the interval in context.
Solution
Given: n = 12, \(\bar{x} = 98.45\%\), s = 1.23%
Part (a): t-critical value
df = 12 - 1 = 11
\(t_{0.025, 11} = 2.201\)
Part (b): Estimated standard error
Part (c): Margin of error
Part (d): 95% CI
Part (e): Interpretation
We are 95% confident that the true mean purity of this pharmaceutical batch is between 97.67% and 99.23%.
R verification:
xbar <- 98.45; s <- 1.23; n <- 12
df <- n - 1
t_crit <- qt(0.025, df, lower.tail = FALSE)
SE <- s / sqrt(n)
ME <- t_crit * SE
c(xbar - ME, xbar + ME) # [97.67, 99.23]
Exercise 4: CI from Raw Data
A biomedical engineer tests the glucose response time (seconds) of a new blood glucose monitor. The measured times from 8 test samples are:
4.2, 3.8, 4.5, 4.1, 3.9, 4.4, 4.0, 4.3
Calculate \(\bar{x}\) and \(s\).
Construct a 95% confidence interval for the mean response time.
The manufacturer claims the mean response time is 4.0 seconds. Is this claim consistent with your interval?
Use R’s
t.test()function to verify your results.
Solution
Part (a): Summary statistics
times <- c(4.2, 3.8, 4.5, 4.1, 3.9, 4.4, 4.0, 4.3)
mean(times) # 4.15
sd(times) # 0.2449
\(\bar{x} = 4.15\) seconds, \(s = 0.245\) seconds
Part (b): 95% CI
n = 8, df = 7
\(t_{0.025, 7} = 2.365\)
Part (c): Manufacturer’s claim
The claimed value of 4.0 seconds is within the 95% CI (3.95, 4.35). Yes, the claim is consistent with the data.
Part (d): R verification
times <- c(4.2, 3.8, 4.5, 4.1, 3.9, 4.4, 4.0, 4.3)
t.test(times, conf.level = 0.95)
# Output includes:
# 95 percent confidence interval:
# 3.945 to 4.355
# sample mean: 4.15
Exercise 5: Confidence Bounds (σ Unknown)
A quality engineer tests the breaking strength (in Newtons) of climbing rope. From n = 15 samples:
\(\bar{x} = 2850\) N
\(s = 125\) N
Construct a 95% lower confidence bound for mean breaking strength.
Safety standards require mean strength of at least 2700 N. Does the rope meet this standard?
Construct a 95% upper confidence bound.
Compare the bounds to a 95% two-sided CI. Which provides tighter information about each limit?
Solution
Given: n = 15, \(\bar{x} = 2850\) N, s = 125 N, df = 14
\(\widehat{SE} = \frac{125}{\sqrt{15}} = 32.27\) N
Part (a): 95% LCB
\(t_{0.05, 14} = 1.761\)
Part (b): Safety standard
LCB (2793.2 N) > 2700 N requirement. Yes, the rope meets the safety standard with 95% confidence.
Part (c): 95% UCB
Part (d): Comparison to CI
95% CI using \(t_{0.025, 14} = 2.145\):
Comparison:
CI lower bound: 2780.8 N; LCB: 2793.2 N (LCB is tighter/higher)
CI upper bound: 2919.2 N; UCB: 2906.8 N (UCB is tighter/lower)
One-sided bounds provide tighter limits on the side of interest because they use \(t_{\alpha}\) instead of \(t_{\alpha/2}\), and \(t_{0.05} < t_{0.025}\). The UCB is tighter than the CI’s upper bound; the LCB is tighter than the CI’s lower bound.
Exercise 6: Comparing z and t Intervals
A sensor is tested with n = 20 measurements: \(\bar{x} = 152.3\) units, \(s = 8.4\) units. Compare:
Compute a 95% CI using the t-distribution (correct method).
Compute what the CI would be if you incorrectly used the z-distribution with s.
Which interval is wider? Why is using z inappropriate here?
At what sample size would the difference become negligible?
Solution
Given: n = 20, \(\bar{x} = 152.3\), s = 8.4, df = 19
\(\widehat{SE} = \frac{8.4}{\sqrt{20}} = 1.878\)
Part (a): Correct t-interval
\(t_{0.025, 19} = 2.093\)
Part (b): Incorrect z-interval
\(z_{0.025} = 1.96\)
Part (c): Comparison
The t-interval (width = 7.86) is wider than the z-interval (width = 7.36).
Using z is inappropriate because:
σ is unknown and estimated by s
Using s introduces additional variability not accounted for by z
The t-distribution properly inflates the critical value to compensate
Part (d): When difference becomes negligible
For df ≈ 30, \(t_{0.025, 30} = 2.042\) vs \(z_{0.025} = 1.96\) (difference ≈ 4%)
For df ≈ 100, \(t_{0.025, 100} = 1.984\) vs \(z_{0.025} = 1.96\) (difference ≈ 1%)
For most practical purposes, the difference is negligible when n > 100 or so.
Exercise 7: Multiple Confidence Levels
Using the data from Exercise 3 (n = 12, \(\bar{x} = 98.45\%\), s = 1.23%):
Construct 90%, 95%, and 99% confidence intervals.
Create a table showing confidence level, t-critical value, ME, and interval bounds.
What pattern do you observe?
If the specification requires purity above 97.5%, at which confidence level(s) can you confidently claim compliance?
Solution
Given: n = 12, df = 11, \(\bar{x} = 98.45\%\), s = 1.23%, \(\widehat{SE} = 0.355\%\)
Parts (a) and (b): Table
Confidence |
\(t_{crit}\) |
ME |
Lower |
Upper |
|---|---|---|---|---|
90% |
1.796 |
0.638 |
97.81 |
99.09 |
95% |
2.201 |
0.781 |
97.67 |
99.23 |
99% |
3.106 |
1.103 |
97.35 |
99.55 |
Part (c): Pattern
As confidence level increases:
t-critical value increases
Margin of error increases
Interval width increases
Higher confidence requires wider intervals.
Part (d): Compliance claim
Specification: purity > 97.5%
At 90%: Lower bound (97.81) > 97.5 ✓
At 95%: Lower bound (97.67) > 97.5 ✓
At 99%: Lower bound (97.35) < 97.5 ✗
Can claim compliance at 90% and 95% confidence, but not at 99%.
R verification:
xbar <- 98.45; s <- 1.23; n <- 12
SE <- s / sqrt(n)
conf_levels <- c(0.90, 0.95, 0.99)
alpha <- 1 - conf_levels
t_crits <- qt(alpha/2, df = 11, lower.tail = FALSE)
MEs <- t_crits * SE
data.frame(
Confidence = paste0(conf_levels * 100, "%"),
t_crit = round(t_crits, 3),
ME = round(MEs, 3),
Lower = round(xbar - MEs, 2),
Upper = round(xbar + MEs, 2)
)
Exercise 8: Robustness to Non-Normality
The t-procedures assume the population is approximately normal. However, they are somewhat robust to departures from normality.
For what sample sizes are t-procedures most sensitive to non-normality?
What features of a distribution are most problematic for t-procedures?
Given a sample with n = 8 that contains one apparent outlier, what should you do before constructing a CI?
A researcher has n = 50 observations from a mildly skewed population. Is it appropriate to use t-procedures?
If you discover a problematic outlier after constructing a CI, what remedies might you consider?
Solution
Part (a): Most sensitive sample sizes
t-procedures are most sensitive to non-normality when n is small (generally n < 15). With small samples, there’s little averaging to invoke the CLT, so the normality assumption is more critical.
Guidelines:
n < 15: Population should be approximately normal with no outliers. t-procedures are sensitive to non-normality at small sample sizes.
15 ≤ n < 40: Mild departures from normality are acceptable; avoid strong skewness or outliers
n ≥ 40: t-procedures are generally reliable even with moderately skewed distributions, thanks to the CLT
Part (b): Problematic distribution features
Outliers: Most problematic—inflate s and distort \(\bar{x}\)
Strong skewness: Asymmetry can bias the sample mean
Heavy tails: Increase the chance of extreme observations
Bimodality: Violates the single-peak assumption
Part (c): Outlier in small sample (n = 8)
Before constructing a CI:
Investigate the outlier—is it a measurement error, data entry error, or legitimate observation?
Create diagnostic plots (histogram, boxplot, QQ-plot)
If error: correct or remove with justification
If legitimate: consider the impact on results; report both with and without the outlier
Consider robust alternatives if available
Part (d): n = 50, mildly skewed
Yes, appropriate. With n = 50, the CLT ensures the sampling distribution of \(\bar{x}\) is approximately normal even if the population is mildly skewed. t-procedures are robust at this sample size.
Part (e): Remedies for problematic outliers
If an outlier is discovered after constructing a CI:
Investigate: Determine if it’s an error or valid data point
Consider removal: If there’s justification (measurement error, data recording mistake), remove and recompute
Acknowledge robust alternatives: Median-based CI or bootstrap methods (not covered in this course) are less sensitive to outliers
Report with caution: If the outlier appears valid, interpret results carefully and note the limitation
Exercise 9: Sample Size Planning with Unknown σ
When planning sample size with σ unknown, we face a challenge: we need s to find the t-critical value, but we don’t have data yet.
A researcher wants a 95% CI for mean reaction time with ME ≤ 5 ms. A pilot study suggests s ≈ 20 ms.
Using the z-approximation (pretending σ = 20), calculate the required sample size.
Using the result from (a), find \(t_{0.025, n-1}\) and recalculate the required n.
Iterate: with the new n, find the new t-critical value and check if n is sufficient.
What is the final recommended sample size?
Solution
Given: 95% CI, ME ≤ 5 ms, estimated s = 20 ms
Step 1 — Initial z-approximation
Step 2 — First iteration with t
With n = 62, df = 61: \(t_{0.025, 61} = 2.000\)
Step 3 — Check for convergence
With n = 64, df = 63: \(t_{0.025, 63} = 1.998\)
Converged!
Part (d): Final recommendation
n = 64 samples
Note: One or two iterations is typically sufficient because t-critical values change slowly once df is moderate (beyond about 20).
R verification:
s <- 20; ME <- 5
# Initial z-approximation
n1 <- ceiling((qnorm(0.025, lower.tail=FALSE) * s / ME)^2) # 62
# First iteration
n2 <- ceiling((qt(0.025, n1-1, lower.tail=FALSE) * s / ME)^2) # 64
# Second iteration
n3 <- ceiling((qt(0.025, n2-1, lower.tail=FALSE) * s / ME)^2) # 64
# Verify
qt(0.025, 63, lower.tail = FALSE) # 1.998
9.8.9. Additional Practice Problems
True/False Questions (1 point each)
The t-distribution has heavier tails than the standard normal distribution.
Ⓣ or Ⓕ
As degrees of freedom increase, t-critical values approach z-critical values.
Ⓣ or Ⓕ
For a one-sample t-procedure with n = 20, the degrees of freedom is 20.
Ⓣ or Ⓕ
The t-distribution is appropriate when σ is known.
Ⓣ or Ⓕ
A 95% CI using t will always be wider than one using z (same data).
Ⓣ or Ⓕ
t-procedures require the population to be exactly normal.
Ⓣ or Ⓕ
Multiple Choice Questions (2 points each)
For n = 25 and 95% confidence, the appropriate critical value is:
Ⓐ \(z_{0.025} = 1.96\)
Ⓑ \(t_{0.025, 25} = 2.060\)
Ⓒ \(t_{0.025, 24} = 2.064\)
Ⓓ \(t_{0.05, 24} = 1.711\)
If \(\bar{x} = 45\), s = 6, n = 16, the 95% CI is approximately:
Ⓐ 45 ± 2.131(1.5)
Ⓑ 45 ± 1.96(1.5)
Ⓒ 45 ± 2.131(6)
Ⓓ 45 ± 1.753(1.5)
The degrees of freedom for a one-sample t-test equals n - 1 because:
Ⓐ One observation is lost to rounding
Ⓑ We estimate one parameter (μ) from the data
Ⓒ We estimate one parameter (σ) using s, losing one degree of freedom
Ⓓ The sample size must be reduced by 1
t-procedures are most robust to non-normality when:
Ⓐ Sample size is very small (n < 10)
Ⓑ Sample size is moderate to large (n ≥ 30)
Ⓒ The population is heavily skewed
Ⓓ Outliers are present
For a 90% LCB with n = 20, the critical value is:
Ⓐ \(t_{0.10, 19}\)
Ⓑ \(t_{0.05, 19}\)
Ⓒ \(t_{0.10, 20}\)
Ⓓ \(z_{0.10}\)
Which R command gives a 95% CI for mean of vector x?
Ⓐ
t.test(x)Ⓑ
z.test(x)Ⓒ
confint(x)Ⓓ
qt(0.025, length(x))
Answers to Practice Problems
True/False Answers:
True — The t-distribution has heavier tails to account for uncertainty in estimating σ.
True — As df → ∞, t → z. By df ≈ 30, they’re close; by df ≈ 100, nearly identical.
False — df = n - 1 = 19, not 20.
False — When σ is known, use the z-distribution. t is for σ unknown.
True — t-critical values exceed z-critical values for all finite df.
False — t-procedures are robust to mild departures, especially with larger samples.
Multiple Choice Answers:
Ⓒ — df = n - 1 = 24, and for a CI use \(t_{0.025, 24}\).
Ⓐ — SE = 6/√16 = 1.5; df = 15; \(t_{0.025, 15} = 2.131\).
Ⓒ — We use one degree of freedom to estimate σ with s.
Ⓑ — Larger samples invoke CLT, making the procedure robust to non-normality.
Ⓐ — For a one-sided bound at 90% confidence, use \(t_{0.10, n-1} = t_{0.10, 19}\).
Ⓐ —
t.test(x)computes the one-sample t-test and 95% CI by default.