Slides 📊
8.2. Experimental Design Principles
To produce valid and meaningful results, an experiment must be designed according to a set of fundamental principles. These principles guide how to control variability, reduce bias, and ensure the integrity of the conclusions.
Road Map 🧭
Recognize the different building blocks of an experiment: experimental units, factors, levels, treatment, and response.
Understand that a well-designed experiment must follow the three key principles: Control, Replication, and Randomization.
8.2.1. The Language of Experimental Design
Before exploring the principles themselves, let us establish the vocabulary for the different components of an experiment.
Experimental Units and Subjects
Experimental units are the objects or entities being studied in an experiment—the things to which treatments are applied and from which responses are measured. When these units happen to be human beings, we call them experimental subjects or simply subjects.
Factors, Levels, and Treatments
Factors are the variables that are hypothesized to be associated with the response variable. They are also called the independent or explanatory variables. Each factor can take on different values called levels. Think of factors as categorical variables where each category represents a different setting or condition we want to test.
A treatment represents a specific combination of factor levels that is applied to an experimental unit.
Response Variables
The response variable (also called the dependent variable) is what we measure to assess the effect of our treatments. This is the outcome we believe might be influenced by the factors.
Statistical Significance
If the response has a more pronounced structure than you would expect from only random chance, we call the result statistically significant.
Example 💡: Crop Yield Study 🌾
Consider a study investigating how different agricultural practices affect crop yield. The study examines the following conditions:
Fertilizer: Type 1, Type 2
Water quantity: 0.2, 0.4, 0.6, 0.8, 1.0 gallons per square foot
Vitamins: Brand A, Brand B, Brand C
Pesticides: Combo 1, Combo 2, Combo 3
Describe the experimental units, factors, levels, treatments, and the response variable in this experiment. What would be an example of a statistically significant result from this experiment?
Experimental Units
The experimental units are the individual crop plots. Each plot receives a treatment then produces a crop yield as a response.
Factors, levels, and treatments
There are four factors in this experiment: fertilizer, water quantity, vitamins, and pesticides.
The different levels of the factor fertilizer is Type 1 and Type 2. (The listing of the levels of other factors are omitted for conciseness).
There are \(2 \times 5 \times 3 \times 3 = 90\) possible treatments. An example of a specific treatment is “Fertilizer Type 2, 0.8 gallons per sq ft of water, Vitamins from Brand A, and Pesticides Combo 1.”
Response
The response variable is the crop yield, measured in bushels per acre, for example.
Statistical Significance
If the crop yield is much higher for a single type of pesticide than others, then this would be considered a statistically significant result.
8.2.2. The Three Principles of Well-Designed Experiments
Principle 1: Control
Imagine testing a new fertilizer and observing that plants grow to an average height of 24 inches. Is this good or bad? Without a baseline for comparison, it is impossible to say. The first principle requires establishing conditions that allow for an objective comparison of results.
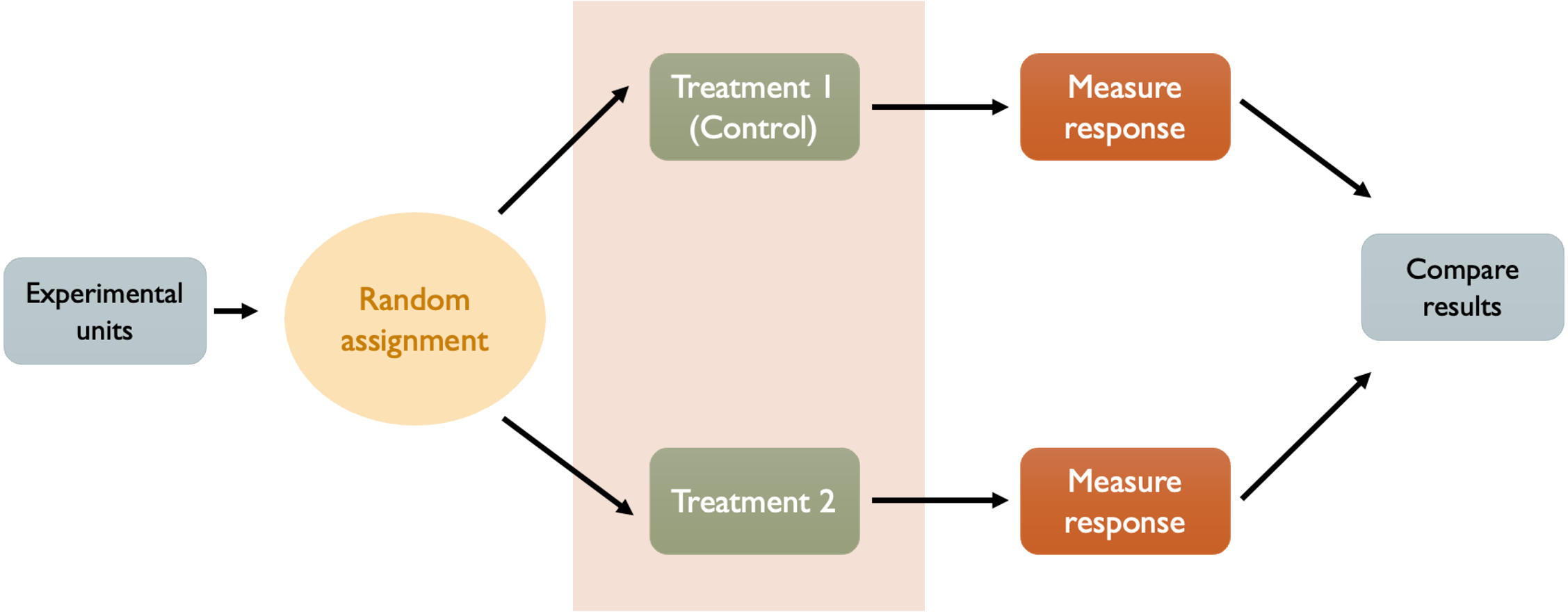
Fig. 8.1 Principle 1: Control
The term “control” is used for two different purposes:
First, a well-designed experiment should include a control group whenever applicable.
Second, the experiment should maintain control over the environment so that all treatment groups experience comparable conditions, differing only in the treatment they receive.
Let us examine what these statements mean in further detail.
A. Control Group as Baseline
A control group serves as the standard against which we measure treatment effects. This group receives either no treatment at all or a standard “status quo” treatment that represents current practice.
It is possible that a control group is not a feasible option in certain experiments. In such cases, the experiment must include at least two distinct treatment groups.
The Placebo Effect and Blinding
The placebo effect is a medical phenomenon in which people experience real physiological or psychological changes simply because they believe they’re receiving treatment, even when the “treatment” is inert.
In medical experiments, the control group is designed to account for this. A placebo is a dummy treatment designed to be indistinguishable from the real treatment but lacking the key ingredient. Sugar pills that look identical to medication, saline injections that feel like real injections, or sham procedures that mimic real surgeries all serve as placebos.
To prevent further confounding of the placebo effect or any other subjective belief, a technique called blinding is also used.
In single-blind experiments, either subjects or researchers are kept unaware of group assignments, but not both. This might be used when it is impossible to hide the treatment from researchers (such as surgical procedures) but subjects can remain unaware of which specific treatment they received.
In double-blind experiments, both subjects and researchers are kept unaware of group assignments. This represents the gold standard for eliminating bias, as it prevents both subject expectations and researcher expectations from influencing results.
Double-blinding is particularly important when:
Outcomes are subjective or require researcher judgment.
Researchers have strong expectations about which treatment should work.
Subjects’ knowledge of their treatment could affect their behavior or reporting.
B. Maintaining Control Over Experimental Environment for Comparable Conditions
For different treatment groups to provide valid comparisons, they must be treated identically in every way except for the specific treatment being tested. Any systematic difference in how groups are treated (other than the treatment itself) can confound the results.
Blocking: Advanced Control for Known Confounders
Sometimes we know that certain characteristics of the experimental units will strongly influence the response, even though these characteristics aren’t what we want to study. These extraneous variables are sometimes controlled by grouping experimental units into blocks based on similar extraneous characteristics, then performing the experiment within each block. By comparing experimental results in a block of shared characteristics, we remove the possibility that any patterns in the results are due to the extraneous variable.
Blocking is explored in more detail in Section 8.3.
Principle 2: Randomization
Many variables can influence experimental outcomes—some we know about, others we don’t, and still others we can’t easily measure or control. If experimental units with certain characteristics systematically end up in certain treatment groups, we can’t tell whether observed differences are due to treatments or due to these underlying characteristics.
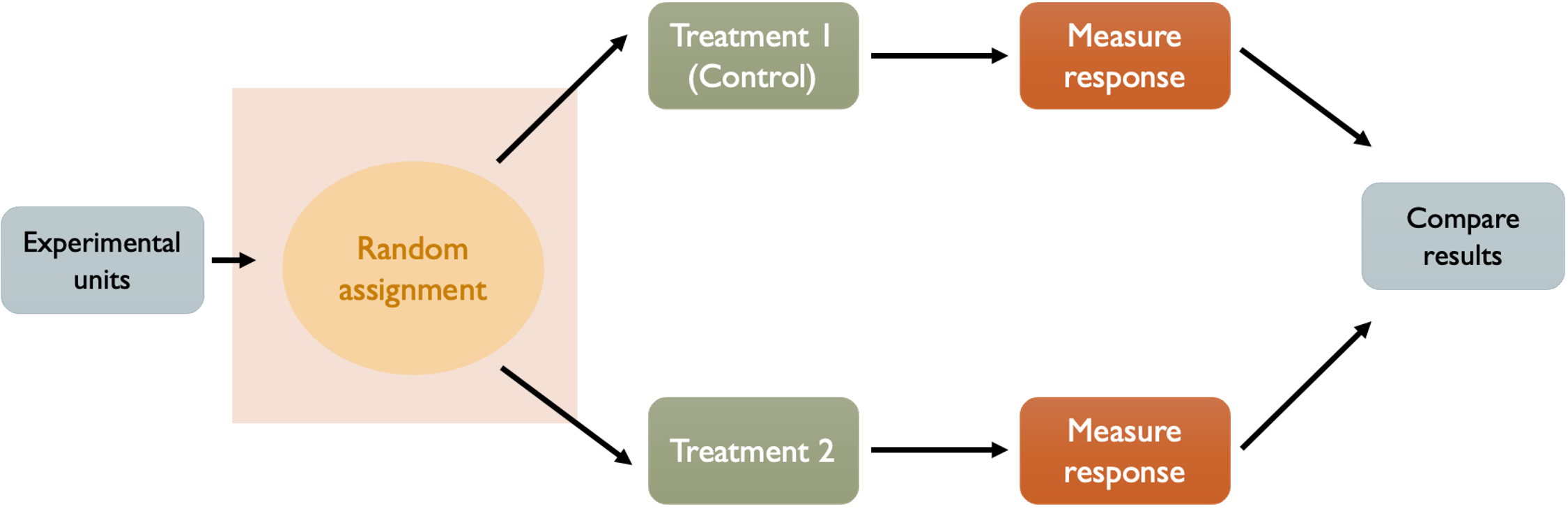
Fig. 8.2 Principle 2: Randomization
To prevent this, we must randomly assign experimental units to a treatment group. Randomization means using chance—not human judgment, convenience, or any other systematic method—to assign experimental units to treatment groups. When done properly, across many possible randomizations, each treatment group will have the same distribution of relevant characteristics. While any single randomization might produce some imbalance, there’s no systematic bias toward any particular pattern.
Example 💡: Random Assignment of Units to Treatment Groups
Suppose we have 125 participants to randomize into one control group and three treatment groups (four groups total). A simple randomization procedure might work as follows:
Create a master list of all 125 participants.
Use a randomization device (like a four-sided die) to assign each participant:
Roll 1 = Control group
Roll 2 = Treatment 1
Roll 3 = Treatment 2
Roll 4 = Treatment 3
Continue until all participants are assigned.
This procedure gives each participant an equal probability of ending up in any group, regardless of their characteristics.
Principle 3: Replication
Statistical variation is inevitable in experimental data. Even when treatments have real effects, individual responses will vary due to natural differences between experimental units, measurement error, and random environmental factors. With small samples, this variation can easily mask true treatment effects or create the appearance of effects where none exist.
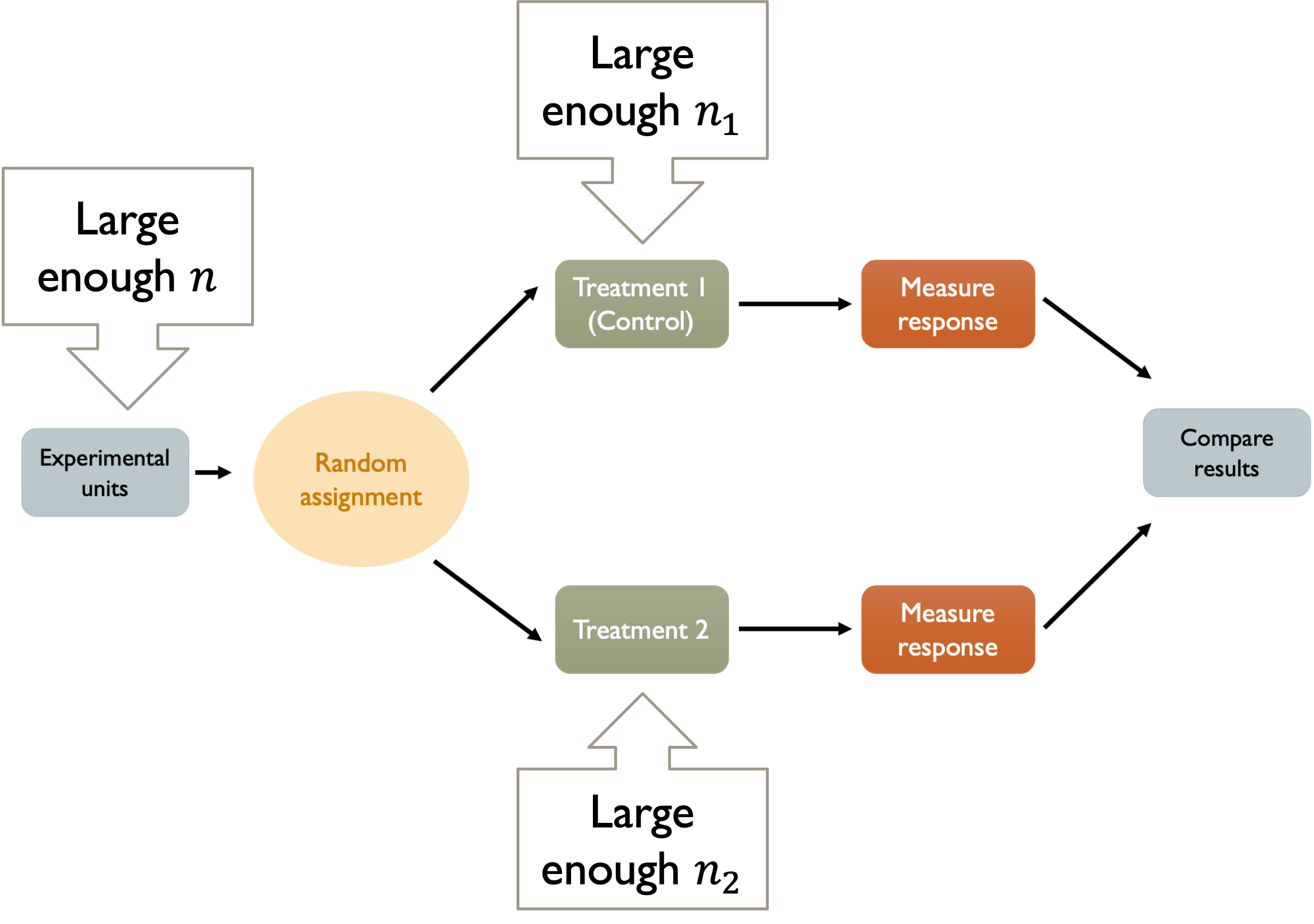
Fig. 8.3 Principle 3: Replication
Replication means using enough experimental units within each treatment group so that individual variation averages out, revealing the underlying treatment effects. Independence between measurements is crucial here. Ten measurements from the same experimental unit (like taking a patient’s blood pressure ten times) don’t provide the same information as one measurement each from ten different experimental units.
With adequate replication,
Individual outliers have less influence on group averages.
Treatment effects become distinguishable from random fluctuations.
Statistical power increases, making it easier to detect real effects when they exist.
8.2.3. Bringing It All Together
Key Takeaways 📝
Three principles are essential: Control, Randomization, and Replication should be sufficiently satisfied for validity of an experimental study.
Control provides the basis for comparison through control groups and standardized conditions.
Randomization creates comparable groups by using chance to assign treatments, eliminating systematic bias and enabling statistical inference.
Replication ensures reliable conclusions by providing enough observations to distinguish genuine effects from random variation.
It’s important to recognize that no study is ever perfect. Real-world constraints always require compromises. The goal is not perfection but rather ensuring that all three principles are satisfied well enough to support reliable conclusions.
As we continue through this chapter, we’ll explore specific experimental designs that implement these principles in different research contexts, common problems that arise when principles are violated, and practical strategies for designing studies that produce reliable, actionable results.
8.2.4. Exercises
These exercises develop your understanding of experimental design vocabulary and the three fundamental principles: control, randomization, and replication.
Key Concepts
Experimental Design Vocabulary
Experimental units: Objects/entities to which treatments are applied (called subjects when human)
Factors: Variables hypothesized to affect the response (explanatory variables)
Levels: Different values or settings a factor can take
Treatment: A specific combination of factor levels applied to a unit
Response variable: The outcome measured to assess treatment effects
Statistical significance: Evidence against a “no effect” model; does NOT guarantee practical importance
The Three Principles
Control: Establish comparison baseline (control group) and maintain consistent conditions
Randomization: Use chance to assign units to treatments, eliminating systematic bias
Replication: Include enough units per treatment to distinguish real effects from random variation
Control Techniques
Control group: Receives no treatment or standard treatment for baseline comparison
Placebo: Inert treatment that mimics the real treatment (addresses placebo effect)
Single-blind: Either subjects OR researchers unaware of assignments
Double-blind: Both subjects AND researchers unaware of assignments
Blocking: Grouping units by characteristics to control known confounders (detailed in 8.3)
Important Distinction
Random assignment (to treatments): Supports causal inference within the study
Random sampling (from population): Supports generalization to the population (covered in 8.6)
Exercise 1: Identifying Experimental Components
A software company wants to test whether different user interface (UI) designs affect task completion time. They recruit 120 users and randomly assign them to one of four groups:
Group 1: Original UI (current design)
Group 2: Simplified menu structure
Group 3: Enhanced visual feedback
Group 4: Both simplified menus and enhanced feedback
Each user completes 10 standardized tasks, and researchers record the total completion time.
Identify each component of this experiment:
Experimental units
Factors and their levels
Treatments (list all four)
Response variable
Control group (if any)
Solution
Part (a): Experimental units
The 120 users are the experimental units (specifically, subjects, since they are human).
Part (b): Factors and levels
There are two factors:
Menu structure: 2 levels (Original, Simplified)
Visual feedback: 2 levels (Standard, Enhanced)
Part (c): Treatments
The four treatments are all combinations of factor levels:
Original menu + Standard feedback (Group 1)
Simplified menu + Standard feedback (Group 2)
Original menu + Enhanced feedback (Group 3)
Simplified menu + Enhanced feedback (Group 4)
Part (d): Response variable
Total task completion time (measured in seconds or minutes) for the 10 standardized tasks.
Part (e): Control group
Group 1 (Original UI) serves as the control group — it represents the current standard against which the new designs are compared.
Exercise 2: Calculating Number of Treatments
For each experiment, determine the total number of possible treatments.
A manufacturing study examines the effect of temperature (3 levels: low, medium, high) and pressure (2 levels: standard, elevated) on product strength.
An agricultural study tests fertilizer type (4 brands), irrigation frequency (3 levels: daily, every other day, weekly), and soil amendment (2 types: with compost, without).
A clinical trial compares drug dosage (5 levels: 10mg, 20mg, 50mg, 100mg, 200mg) against a placebo for migraine relief.
A user experience study tests font size (3 levels), color scheme (4 options), layout (2 designs), and animation speed (3 settings).
Solution
Part (a): 3 × 2 = 6 treatments
Each combination of temperature and pressure is a distinct treatment.
Part (b): 4 × 3 × 2 = 24 treatments
All combinations of fertilizer type, irrigation frequency, and soil amendment.
Part (c): Interpretation matters
If placebo is a separate treatment (not receiving any drug): 5 drug doses + 1 placebo = 6 treatments
If “placebo” is considered a level of dosage (0mg): 6 treatments
Note: In typical clinical trials, placebo is treated as a separate control condition.
Part (d): 3 × 4 × 2 × 3 = 72 treatments
This many treatments would require a very large sample size for adequate replication, suggesting the researchers might consider a fractional factorial design (beyond STAT 350 scope).
Exercise 3: Principle Violations
For each scenario, identify which principle(s) of experimental design are violated (Control, Randomization, or Replication) and explain the potential consequences.
A pharmaceutical company tests a new pain reliever by giving it to patients at Clinic A and comparing their outcomes to patients at Clinic B who receive a placebo.
A teacher evaluates a new teaching method by using it with her morning class and comparing test scores to her afternoon class, which receives traditional instruction.
An engineer tests whether a new manufacturing process reduces defects by running 3 batches with the new process and 3 batches with the old process.
A researcher studying the effect of sleep on memory lets participants choose whether to be in the “8 hours sleep” or “4 hours sleep” group.
A tech company tests two website layouts by showing Layout A to all users on Monday and Layout B to all users on Tuesday, then comparing click-through rates.
Solution
Part (a): Randomization violated
Problem: Patients are not randomly assigned; instead, entire clinics receive different treatments. Clinics may differ in patient demographics, standard of care, or physician expertise.
Consequence: Any difference in outcomes could be due to clinic differences rather than the treatment effect.
Part (b): Randomization violated (and potentially Control)
Problem: Treatment is confounded with time of day. Morning and afternoon students may differ systematically (alertness, motivation, course load).
Consequence: Cannot determine whether differences are due to teaching method or time-of-day effects.
Part (c): Replication is limited
Problem: Only 3 batches per treatment provides very few observations. This limited replication means batch-to-batch variation can easily mask true treatment effects or create the appearance of effects that don’t exist.
Consequence: Low statistical power — may miss real effects or produce unstable estimates that are sensitive to individual batch outcomes. Results unlikely to replicate.
Part (d): Randomization violated
Problem: Self-selection bias. Participants who choose less sleep may differ from those who choose more sleep (e.g., busier schedules, different health status, attitudes toward sleep).
Consequence: Observed memory differences may be due to pre-existing characteristics, not sleep duration.
Part (e): Randomization violated + temporal confounding
Problem: Treatment is confounded with day of week. Monday and Tuesday traffic may differ systematically (user types, moods, browsing patterns).
Consequence: Cannot separate layout effects from day-of-week effects.
Exercise 4: The Importance of Control Groups
A software company claims their new coding bootcamp is effective because 85% of graduates found programming jobs within 6 months.
Explain why this claim cannot be validated without a control group.
What would be an appropriate control group for this study?
Identify at least three confounding factors that could explain the high job placement rate without the bootcamp being effective.
If you found that 70% of a comparable control group also found jobs, what would this suggest about the bootcamp’s effectiveness?
Solution
Part (a): Why a control group is needed
Without knowing what would have happened to similar people who didn’t attend the bootcamp, we can’t attribute the job outcomes to the program. The 85% rate has no baseline for comparison — it might be typical for motivated individuals seeking programming careers, regardless of training.
Part (b): Appropriate control group
An appropriate control group would be people who: - Were interested in programming careers - Had similar educational backgrounds and prior experience - Applied to or considered the bootcamp but did not attend - Were tracked over the same 6-month period
Ideally, applicants would be randomly assigned to attend or not attend (though this raises practical and ethical issues).
Part (c): Confounding factors
Self-selection: People who pay for and complete an intensive bootcamp may be highly motivated, organized, and committed — traits that help in job searches regardless of technical training.
Job market conditions: If the tech job market is strong, many people find programming jobs without formal training.
Networking opportunities: The bootcamp may provide connections and referrals; the value could be networking rather than skills taught.
Pre-existing skills: Bootcamp participants may already have relevant skills (math, problem-solving, prior coding exposure) that would help them find jobs anyway.
Demographics: Bootcamp attendees may disproportionately come from backgrounds (education level, geographic location, existing networks) that facilitate job placement.
Part (d): Interpretation with control comparison
If 70% of the control group found jobs compared to 85% of bootcamp graduates, the bootcamp shows a 15 percentage point improvement. This is a more meaningful measure of effectiveness than the raw 85% rate.
However, we’d still need to assess whether this difference is statistically significant and whether the control group is truly comparable.
Exercise 5: Blinding in Experimental Design
For each scenario, determine the most appropriate level of blinding (none, single-blind, or double-blind) and explain why.
Comparing two algorithms for sorting large datasets by measuring execution time on identical hardware.
Testing whether a new energy drink improves athletic performance compared to a placebo drink.
Evaluating whether a new ergonomic keyboard reduces typing errors compared to a standard keyboard.
Comparing recovery times for two surgical techniques where one requires larger incisions than the other.
Testing whether a new antidepressant reduces symptoms more than a sugar pill placebo.
Solution
Part (a): No blinding needed
Reasoning: The experimental units (datasets) and measurements (execution time) are objective. Neither the algorithm nor the timing system can be influenced by knowledge of treatment assignment. Human judgment doesn’t affect the outcome.
Part (b): Double-blind
Reasoning: Athletic performance can be affected by belief (placebo effect). If athletes know they received the energy drink, they may try harder. If researchers know, they may unconsciously encourage energy drink participants. Both the drink container and the researcher administering assessments should be blinded.
Part (c): Single-blind (subjects blinded)
Reasoning: Typing errors could be affected by expectation — users might be more careful if they think the keyboard should help. However, it’s practically impossible to blind researchers to keyboard type since they’re visibly different. Best approach: blind users to the study hypothesis (tell them they’re testing “keyboard comfort” rather than “error reduction”).
Part (d): Single-blind (subjects blinded if possible)
Reasoning: Patients cannot easily be blinded to incision size (though bandaging can help temporarily). Researchers measuring recovery (nurses, physical therapists) could be blinded to which procedure was performed by having a different team conduct assessments. Full double-blinding is not feasible.
Part (e): Double-blind
Reasoning: Depression symptoms are highly susceptible to placebo effects. Patient expectations strongly influence self-reported symptoms. Researcher expectations can influence how they interpret symptom reports. Both must be blinded for valid results. This is the gold standard for psychiatric medication trials.
Exercise 6: Designing Proper Randomization
A biomedical engineer wants to test three different prosthetic limb designs (A, B, C) with 45 volunteers who have lower-limb amputations.
Describe a proper randomization procedure to assign volunteers to prosthetic designs.
A colleague suggests assigning the first 15 volunteers who enroll to Design A, the next 15 to Design B, and the last 15 to Design C. Explain why this is problematic.
After randomization, you notice that Design A’s group has an average age of 58, while Designs B and C have average ages of 42 and 45. Should you re-randomize? Explain your reasoning.
What is the probability that any specific volunteer is assigned to Design A under proper randomization?
Solution
Part (a): Proper randomization procedure
Create a master list of all 45 volunteers with unique identifiers (e.g., V01–V45).
Use a random number generator or random number table to assign each volunteer to a design: - Generate a random number 1–3 for each volunteer - 1 = Design A, 2 = Design B, 3 = Design C
If balanced group sizes are desired, use a constrained randomization: - Write “A”, “B”, “C” each 15 times on identical slips - Draw slips randomly (without replacement) for each volunteer in sequence
Part (b): Why sequential assignment is problematic
Early enrollees may differ systematically from late enrollees: - Motivation: More eager participants enroll first; they may be more compliant - Severity: Those with more urgent needs may enroll earlier - Awareness: Early enrollees hear about the study differently than later ones - Demographics: Word of mouth spreads through networks, potentially changing the demographic mix over time
This creates a confound between enrollment timing and treatment assignment.
Part (c): Should you re-randomize?
No. Random assignment doesn’t guarantee perfect balance on every characteristic — some imbalance is expected by chance. Re-randomizing until groups look “balanced” actually introduces bias (you’re no longer using random assignment).
Proper approaches: - Report the imbalance and include age as a covariate in analysis - Consider whether the imbalance is statistically significant or just chance variation - For future studies with known important covariates, use blocking or stratified randomization
Part (d): Probability of assignment to Design A
Under simple randomization with three equal groups: P(Design A) = 1/3 ≈ 33.3%
Each volunteer has an equal probability of being assigned to any of the three designs.
Exercise 7: Replication and Sample Size
Explain why each scenario represents inadequate replication and describe the consequences.
A clinical trial tests a new drug on 5 patients and compares results to 5 patients receiving a placebo.
An agricultural study tests a new fertilizer on one large field and compares it to one neighboring field with standard fertilizer.
A manufacturing study tests a new quality control procedure for one week and compares defect rates to the previous week under the old procedure.
A psychology study measures the effect of background music on concentration using a single participant who completes tasks with and without music.
Solution
Part (a): Too few patients per group (n=5)
Problem: Individual patient responses vary greatly due to genetics, disease severity, lifestyle, and other factors. With only 5 patients per group, this variation can easily mask or fabricate treatment effects.
Consequence: Low statistical power — may miss real effects or conclude effects exist when they don’t. Results are highly unstable and unlikely to replicate.
Part (b): Single experimental unit per treatment
Problem: With only one field per treatment, there is no replication at all. Any difference observed could be due to pre-existing differences between the fields (soil composition, drainage, microclimate) rather than the fertilizer.
Consequence: Impossible to separate treatment effects from field-specific characteristics. Cannot compute meaningful measures of variability.
Part (c): Temporal confounding without replication
Problem: The two time periods may differ in ways unrelated to the procedure (different workers, raw materials, equipment condition, orders). Each “treatment” is applied only once.
Consequence: Cannot distinguish procedure effects from week-to-week variation. Single time period for each treatment provides no measure of within-treatment variability.
Part (d): Single subject (n=1)
Problem: Results from one person cannot be generalized. This participant may respond atypically to music. Within-person variation across trials is confounded with treatment effects.
Consequence: No ability to assess whether effects are consistent across individuals. Conclusions limited to this specific person in these specific conditions.
8.2.5. Additional Practice Problems
True/False Questions
In an experiment with 3 factors having 2, 4, and 3 levels respectively, there are 9 possible treatments.
A placebo is used to establish a baseline comparison when no treatment would be unethical.
Random assignment guarantees that treatment groups will be perfectly balanced on all characteristics.
Replication means repeating the entire experiment multiple times.
Double-blinding is always the best choice for any experiment.
The control group in an experiment always receives no treatment at all.
Multiple Choice Questions
In an experiment testing whether fertilizer affects plant growth, the plant growth measured at the end is called the:
Ⓐ Treatment
Ⓑ Factor
Ⓒ Experimental unit
Ⓓ Response variable
Which scenario demonstrates proper randomization?
Ⓐ Assigning left-handed students to Treatment A and right-handed students to Treatment B
Ⓑ Letting students choose which treatment group they prefer
Ⓒ Using a random number generator to assign each student to a group
Ⓓ Assigning the first half of the class roster to Treatment A
A researcher tells participants they will receive either a real painkiller or a placebo, but participants don’t know which they receive. The researcher knows which is which. This is:
Ⓐ Double-blind
Ⓑ Single-blind
Ⓒ Unblinded
Ⓓ A control group design
What is the primary purpose of replication in experimental design?
Ⓐ To ensure the experiment follows ethical guidelines
Ⓑ To distinguish treatment effects from random variation
Ⓒ To make the experiment more convenient to conduct
Ⓓ To ensure all participants receive the same treatment
A factory tests a new assembly method by having Team A use the new method while Team B continues with the old method. Which principle is most clearly violated?
Ⓐ Control
Ⓑ Randomization
Ⓒ Replication
Ⓓ All three equally
In an experiment, the entities that receive treatments and from which measurements are taken are called:
Ⓐ Factors
Ⓑ Levels
Ⓒ Experimental units
Ⓓ Response variables
Answers to Practice Problems
True/False Answers:
False — Number of treatments = 2 × 4 × 3 = 24 (multiply, don’t add).
False — A placebo primarily controls for expectation effects (the placebo effect), not ethics. A “no treatment” control establishes baseline; when no treatment would be unethical, researchers use placebo or standard-of-care as the control. These serve different purposes.
False — Random assignment balances groups on average over many randomizations. Any single randomization may produce some imbalance by chance.
False — Replication means having multiple experimental units per treatment within a single experiment, not repeating the entire study.
False — Double-blinding is ideal when outcomes are subjective, but it’s unnecessary (or impossible) when measurements are objective or when treatments are visibly different.
False — A control group may receive a standard “status quo” treatment for comparison, not necessarily zero treatment.
Multiple Choice Answers:
Ⓓ — The response variable is the outcome measured to assess treatment effects.
Ⓒ — Random assignment requires using chance (not systematic rules, self-selection, or convenience) to assign units to groups.
Ⓑ — Single-blind: participants are blinded but researchers are not.
Ⓑ — Replication provides enough observations to see through random variation and detect real treatment effects.
Ⓑ — Randomization is violated because teams (not individuals) are assigned to treatments without random assignment. Team characteristics may confound results.
Ⓒ — Experimental units are the objects to which treatments are applied and from which responses are measured.