Slides 📊
8.3. Basic Types of Experimental Design
Experimental designs provide structured templates for arranging experimental units, assigning treatments, and collecting data in ways that uphold the three principles of experimental design while addressing specific research challenges.
The three designs we will examine are among the most fundamental. Although more complex designs exist for specialized situations, these basic frameworks can address a wide range of research questions and form the foundation for understanding more advanced approaches.
Road Map 🧭
Understand the structure of the three most fundamental types experimental design: Completely Randomized Design, Randomized Block Design, and Matched Pairs Design.
Identify the advantages and limitations of each design, and select the most appropriate type for a given research setting.
8.3.1. Completely Randomized Design (CRD)
The Completely Randomized Design (CRD) represents the most straightforward application of experimental principles. In a completely randomized design, each unit has an equal chance of being randomly assigned to a treatment group.
Implementation
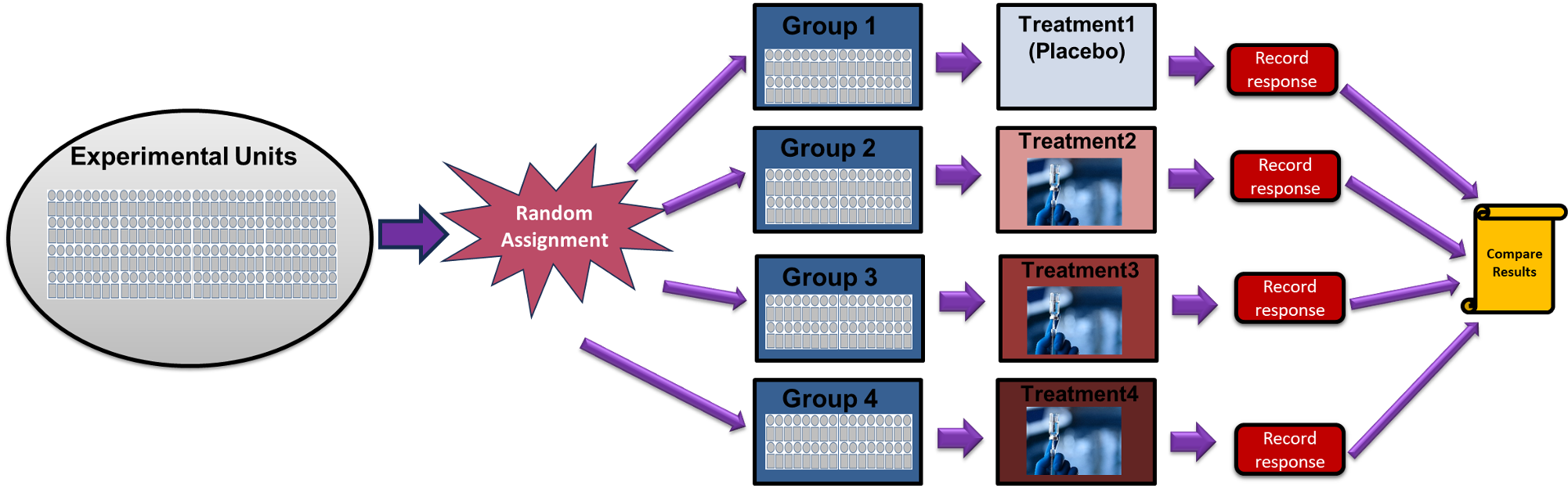
Fig. 8.4 Completely Randomized Design
Let’s walk through implementing a CRD with a concrete example. Suppose we want to test the effects of four different medications on the blood pressure of 40 healthy adults.
Step 1: Identify experimental units and determine the treatment groups. The experimental units would be the 40 human participants. The treatment groups are:
Group 1: Control (placebo)
Group 2: Low dose medication
Group 3: Medium dose medication
Group 4: High dose medication
Step 2: Randomly assign each participant to one of the four groups. We can use a simple procedure like rolling a four-sided die or use computer-generated random numbers.
Step 3: Apply Treatments.
Step 4: Measure Responses. Record blood pressure measurements according to a consistent protocol.
Step 5: Compare Results.
Advantages and Limitations of CRD
Advantages |
Limitations |
|---|---|
|
|
8.3.2. Randomized Block Design (RBD): Controlling Known Variability
When we know that certain extraneous characteristics of our experimental units strongly influence the response variable, Randomized Block Design (RBD) provides a method for controlling this variability while still maintaining the benefits of randomization.
Recall that blocking is a technique of grouping experimental units into subgroups (blocks) based on shared characteristics. By blocking, we remove the effect of the extraneous variable from our comparison of treatments.
Implementation
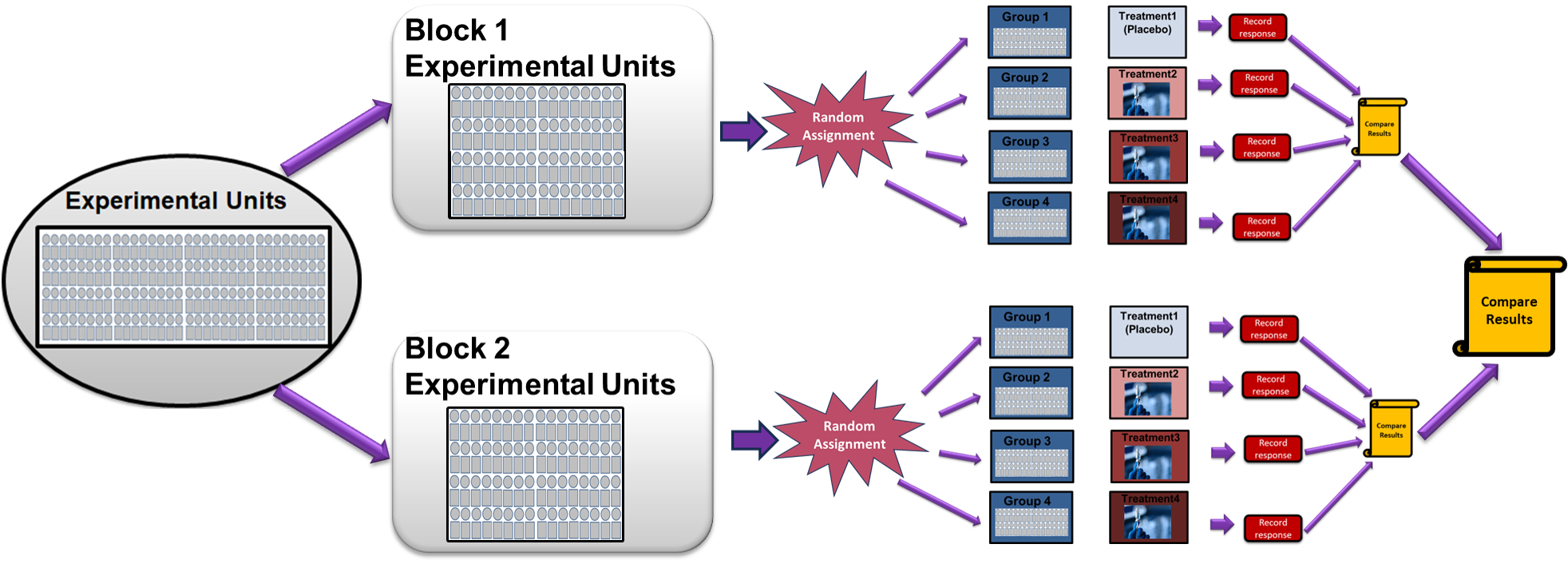
Fig. 8.5 Randomized Block Design
Step 1: Identify the blocking variable. Choose a characteristic that is not the primary focus of the study but strongly influences the response variable.
Step 2: Form blocks. Group experimental units into blocks based on the blocking variable. Each block should contain units that are similar with respect to this characteristic.
Step 3: Randomize within blocks. This is equivalent to conducting a separate completely randomized design within each block.
Step 4: Apply treatments and measure responses.
Step 5: Analyze results. Compare treatments while accounting for block effects.
Example 💡: Testing Pain Medications 💊
Consider testing a new pain medication. If it is known that age significantly affects both baseline pain levels and response to medication, we can choose to create blocks based on age groups.
Block 1: Ages 18-30 (young adults)
Block 2: Ages 31-50 (middle-aged adults)
Block 3: Ages 51-70 (older adults)
Within each age block, randomly assign participants to receive either the new medication or a placebo. This ensures that each treatment is tested across all age groups, while controlling for the known effect of age on pain response.
Advantages and Limitations of RBD
Advantages |
Limitations |
|---|---|
|
|
8.3.3. Matched Pairs Design: Maximum Control
Matched Pairs Design represents the extreme end of the blocking spectrum, where we create the smallest possible blocks—typically containing just two experimental units that are nearly identical with respect to important characteristics.
Type 1: Separate Units in Pairs
In this approach, we identify pairs of experimental units that are extremely similar and randomly assign different treatments to the units in each pair.
Example 💡: Examples of Natural Pairs
Identical twins in medical or behavioral research
Litter mates in animal studies
Adjacent plots in agricultural research
Matched patients with very similar demographic and clinical characteristics
Paired manufacturing units from the same production batch
Implementation of Type 1 Matched Pairs Design
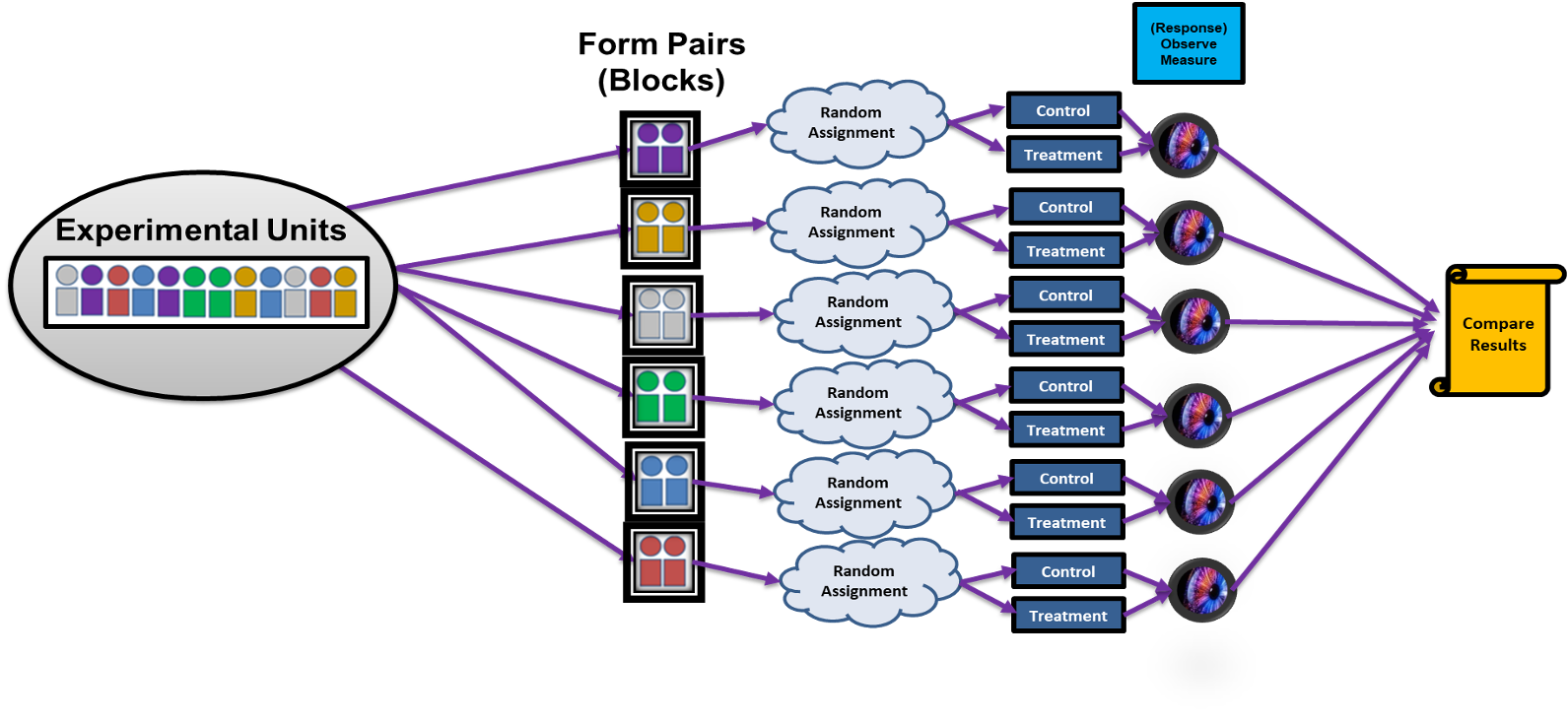
Fig. 8.6 Type 1 Matched Pairs Design
Step 1: Identify matching criteria based on variables that strongly affect the response.
Step 2: Form pairs of units that are nearly identical on these criteria.
Step 3: Randomly assign one member of each pair to one treatment, the other to another.
Step 4: Apply treatments and measure responses.
Step 5: Analyze pair differences.
Advantages and Limitations of Type 1 Matched Pairs Design
Advantages |
Limitations |
|---|---|
|
|
Type 2: Self-Pairing
In self-pairing designs, each experimental unit serves as its own comparison by receiving two treatments in a randomized order, typically separated by a washout period.
Implementation of Type 2 Matched Pairs Design
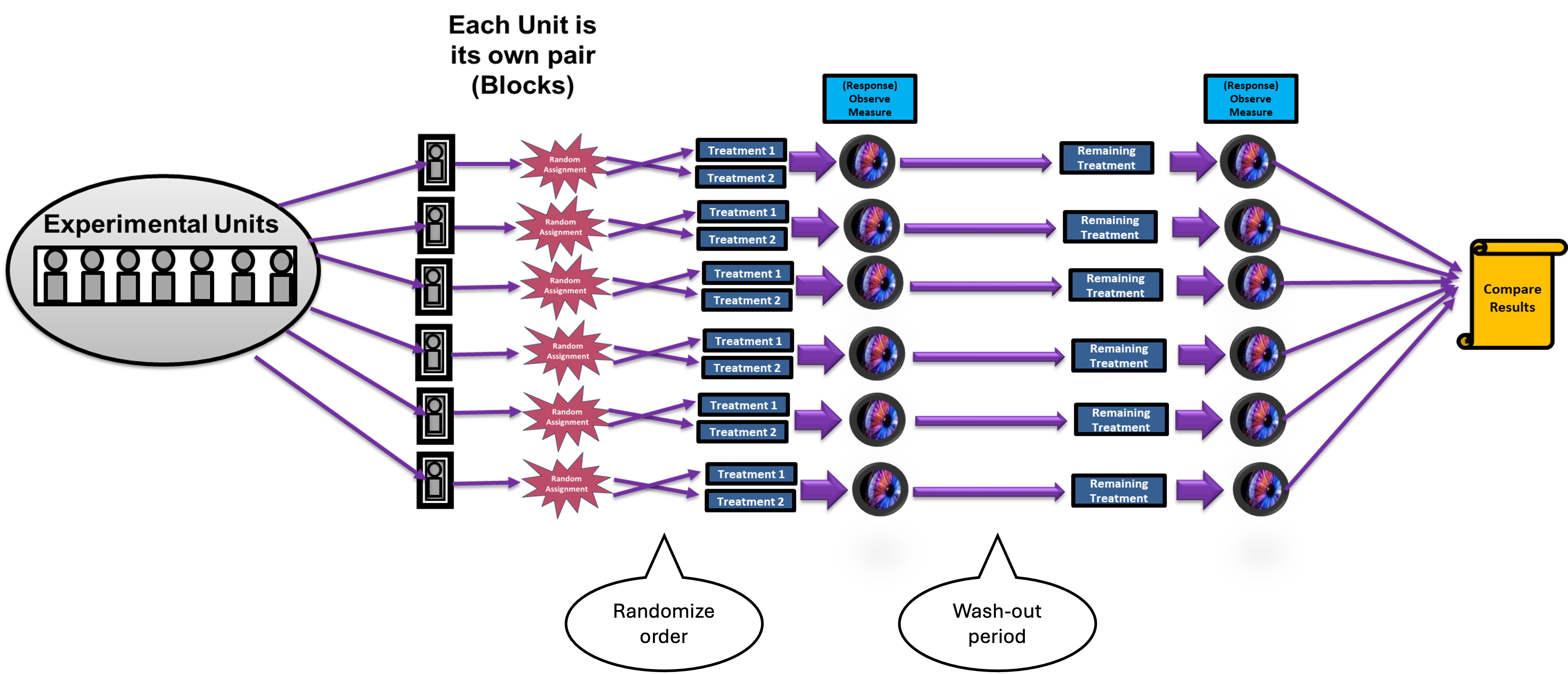
Fig. 8.7 Type 2 Matched Pairs Design
Suppose a researcher wants to compare two pain medications.
Step 1: Randomly assign either Medication A or B to each subject.
Step 2: Each unit takes the first medication for two weeks with daily pain ratings.
Step 3: Each unit enters a washout period of one week with no medication.
Step 4: The second medication is taken for two weeks with daily pain ratings.
Step 5: Compare results within each person.
Preventing the Carry-Over Effect
When the first treatment’s effects persist and influence the results of a subsequent treatment, this is called the carry-over effect. To minimize it:
Allow a washout period—enough time for the first treatment’s effects to fully dissipate before the next treatment.
Randomize treatment order so that not all units experience the same type of carry-over effects.
Some treatments have permanent or very long-lasting effects that make self-pairing inappropriate. For example,
Surgical procedures cannot be “undone”.
Educational interventions create lasting learning.
Some medications have effects that persist long after discontinuation.
Behavioral interventions might create permanent attitude or skill changes.
In these cases, Type 1 matched pairs is the only viable option.
Advantages and Limitations of Type 2 Matched Pairs Design
Advantages |
Limitations |
|---|---|
|
|
8.3.4. Choosing the Right Approach
Selecting the appropriate experimental design requires balancing statistical considerations, practical constraints, and research objectives. Each design offers different advantages and faces different limitations.
Guidelines for Design Choice |
|
|---|---|
Choose CRD when: |
|
Choose RBD when: |
|
Choose Matched Pairs Design when: |
|
8.3.5. Bringing It All Together
Key Takeaways 📝
The three basic designs—Completely Randomized Design, Randomized Block Design, and Matched Pairs Design—serve as building blocks for most experimental approaches.
Design choice depends on the homogeneity of experimental units, known sources of variability, sample size constraints, and research objectives.
CRD provides simplicity and flexibility but works best with homogeneous units and adequate sample sizes.
RBD controls known variability through blocking, increasing precision and efficiency when strong blocking variables exist.
Matched pairs design maximizes control but requires either natural pairs or reversible treatments with adequate washout periods.
8.3.6. Exercises
These exercises develop your understanding of the three basic experimental designs: Completely Randomized Design (CRD), Randomized Block Design (RBD), and Matched Pairs Design.
Key Concepts
Completely Randomized Design (CRD)
Each unit is randomly assigned to exactly one treatment
Simplest design; works best with homogeneous units or large samples
Limitation: May not balance important characteristics across groups
Randomized Block Design (RBD)
Units grouped into blocks based on a characteristic that affects the response
Random assignment occurs within each block
Controls for known sources of variability (the blocking variable)
Advantage: More precise comparisons; removes block-to-block variation
Limitation: Requires advance knowledge of important blocking variables
Note: Blocking controls known nuisance variables but does NOT fix unknown confounding — randomization is still required within blocks
Matched Pairs Design
Extreme form of blocking with blocks of size 2
Type 1 (Separate units): Two similar units matched, one receives each treatment
Type 2 (Self-pairing): Same unit receives both treatments in random order
For Type 2: washout period needed to prevent carry-over effects
Advantage: Maximum control over individual differences
Limitation: Requires natural pairs or reversible treatments
Exercise 1: Design Identification
Identify which design is used in each scenario: CRD, RBD, or Matched Pairs (specify Type 1 or Type 2 if matched pairs).
Thirty patients are randomly assigned to receive either Drug A or Drug B. Each patient receives only one drug, and recovery times are compared.
A taste test compares two cola brands. Each participant tastes both colas (in random order) and indicates which they prefer.
Researchers test three keyboard layouts on 60 programmers. Programmers are first grouped by experience level (novice, intermediate, expert), then within each group, they’re randomly assigned to a keyboard.
Identical twins are recruited for a study on exercise. One twin in each pair is randomly assigned to a new workout program, while the other continues their normal routine.
An agricultural study tests four fertilizers on 80 plots. Plots are first grouped by soil type (sandy, clay, loam, silt), then within each soil type, plots are randomly assigned to fertilizers.
A crossover study tests two migraine medications. Each patient takes Medication A for 4 weeks, has a 2-week washout, then takes Medication B for 4 weeks (order randomized).
Solution
Part (a): Completely Randomized Design (CRD)
Patients are simply randomly assigned to one of two treatments with no grouping or blocking.
Part (b): Matched Pairs Design — Type 2 (Self-pairing)
Each participant serves as their own control by tasting both colas. The random order prevents order effects.
Part (c): Randomized Block Design (RBD)
Experience level is the blocking variable. Within each experience block, random assignment to keyboards occurs. This controls for the effect of experience on typing performance.
Part (d): Matched Pairs Design — Type 1 (Separate units)
Identical twins form natural pairs that are extremely similar genetically. One member of each pair is randomly assigned to each treatment.
Part (e): Randomized Block Design (RBD)
Soil type is the blocking variable. Within each soil type, random assignment to fertilizers occurs. This controls for soil-related variation in crop response.
Part (f): Matched Pairs Design — Type 2 (Self-pairing)
Each patient receives both medications with a washout period between. The crossover design with randomized order is the hallmark of Type 2 matched pairs.
Exercise 2: Choosing the Appropriate Design
For each research scenario, recommend the most appropriate design (CRD, RBD, or Matched Pairs) and justify your choice.
Testing whether a new algorithm runs faster than the current algorithm using 200 identical test cases on the same computer.
Comparing the effectiveness of three teaching methods for calculus using 120 students who vary substantially in math background.
Evaluating two different surgical techniques for ACL repair.
Testing whether noise-canceling headphones improve concentration using 30 office workers.
Comparing four different paint formulations for durability using 40 test panels from 10 different wood species.
Solution
Part (a): Matched Pairs Type 2 (Self-pairing)
Justification: Run both algorithms on each test case, treating each test case as its own control. Randomize the order of algorithms for each test case (to account for caching or warm-up effects). Compare paired differences in runtime.
This is superior to CRD because: - Test cases may vary in complexity, even if nominally “identical” - Pairing eliminates test-case-to-test-case variation - With 200 paired comparisons, statistical power is very high
Note: If running both algorithms on each test case is infeasible (e.g., destructive testing), CRD would be acceptable given the homogeneity of test cases.
Part (b): RBD
Justification: Math background “varies substantially” and will strongly affect learning outcomes. Block students by prior math achievement (e.g., placement test scores) before randomly assigning to teaching methods within blocks. This controls for pre-existing ability differences.
Part (c): CRD (typically) or RBD
Justification: Matched pairs is not feasible — surgical techniques are not reversible (can’t undo an ACL repair). Type 1 matched pairs requires finding patients with bilateral ACL tears who need both knees repaired (rare). CRD is most practical. RBD could be used if blocking by age, injury severity, or activity level is desired.
Part (d): Matched Pairs — Type 2 (Self-pairing)
Justification: Individual differences in baseline concentration are likely large. Each worker can serve as their own control by completing concentration tasks both with and without the headphones (randomized order, with adequate time between sessions). This eliminates individual variation.
Part (e): RBD
Justification: Wood species is a known source of variability in paint durability. With 4 panels per species, block by species and randomly assign one panel to each paint formulation within each species block. This ensures each paint is tested on all wood types.
Exercise 3: Blocking Variable Selection
For each experiment, identify two appropriate blocking variables and explain why each would help control variability.
Testing three different study techniques on exam performance in a statistics course.
Comparing two fertilizers on tomato yield in a community garden.
Evaluating the effect of three website designs on purchase conversion rates.
Testing whether a new engine oil formulation improves fuel efficiency in vehicles.
Solution
Part (a): Study techniques experiment
Prior GPA or math background: Students with stronger academic backgrounds may perform better regardless of study technique. Blocking ensures each technique is tested on students of varying abilities.
Major or course load: STEM majors or students with lighter course loads may have more time/aptitude for studying. Blocking controls for these baseline differences.
Part (b): Fertilizer experiment
Plot location/sunlight exposure: Plots in different areas of the garden receive different amounts of sunlight. Blocking by location (sunny vs. shaded areas) removes this variation.
Soil quality/drainage: Some areas may have better soil or drainage. Blocking by soil characteristics ensures fertilizers are compared under similar growing conditions.
Part (c): Website design experiment
Device type (mobile vs. desktop): User experience differs substantially by device; purchase behavior may vary accordingly. Blocking ensures each design is tested on both device types.
Traffic source (organic search, social media, direct): Visitors from different sources may have different intent levels. Blocking by traffic source controls for visitor motivation.
Part (d): Engine oil experiment
Vehicle age/mileage: Older vehicles with higher mileage may respond differently to oil formulations. Blocking by mileage category ensures comparisons within similar vehicle conditions.
Vehicle type (sedan, SUV, truck): Different vehicle types have different fuel efficiency characteristics. Blocking by type ensures oil effects aren’t confounded with vehicle differences.
Exercise 4: Matched Pairs Feasibility
For each scenario, determine whether Type 1 (separate pairs), Type 2 (self-pairing), or neither matched pairs design is feasible. Explain your reasoning.
Comparing two methods for teaching piano sight-reading to beginners.
Testing whether a new moisturizer reduces skin dryness more than the current product.
Comparing two different chemotherapy protocols for cancer treatment.
Evaluating whether a standing desk improves productivity compared to a sitting desk.
Comparing two anesthesia methods for knee replacement surgery.
Solution
Part (a): Neither (or Type 1 with difficulty)
Reasoning: Learning to sight-read is not reversible — once learned using one method, the skill persists. Type 2 self-pairing is not possible. Type 1 could work with matched pairs of students (similar age, musical background), but finding good matches may be difficult.
Part (b): Type 2 (Self-pairing)
Reasoning: The same person can use one moisturizer, allow a washout period, then use the other. Each person serves as their own control. Alternatively, Type 1 could be done by applying different moisturizers to matched skin areas (left hand vs. right hand).
Part (c): Neither
Reasoning: Chemotherapy protocols typically cannot be “washed out” and restarted with a different protocol on the same patient — the disease state changes, and there are cumulative toxicity concerns. Type 1 would require finding pairs of very similar cancer patients, which is challenging given the heterogeneity of cancer presentations.
Part (d): Type 2 (Self-pairing)
Reasoning: The same person can work at a standing desk for a period, have a break, then work at a sitting desk (or vice versa, randomized). No permanent effects prevent crossover. A reasonable washout between periods controls for fatigue.
Part (e): Neither (typically) or Type 1 with bilateral cases
Reasoning: Patients cannot receive both anesthesia methods for the same surgery (Type 2 impossible). Type 1 would require patients undergoing bilateral knee replacements (both knees at different times) — possible but limiting the sample considerably. CRD or RBD is more practical for this study.
Exercise 5: Washout Periods and Carry-Over Effects
A pharmaceutical company wants to compare two blood pressure medications using a Type 2 matched pairs design (crossover study). Each patient will take Medication A for 4 weeks, then Medication B for 4 weeks, with treatment order randomized.
Define carry-over effect in this context.
Why is a washout period necessary between medications?
What factors should determine the appropriate length of the washout period?
Even with a washout period, why is randomizing the treatment order still important?
Suppose preliminary data shows that patients who took Medication A first have different responses to Medication B than patients who took Medication B first. What does this suggest?
Solution
Part (a): Carry-over effect defined
A carry-over effect occurs when the effects of the first medication persist into the second treatment period, influencing the patient’s response to the second medication. For example, Medication A might cause lasting physiological changes that affect how the body responds to Medication B.
Part (b): Why washout is necessary
The washout period allows the first medication to be fully eliminated from the body and its effects to dissipate. Without washout, observed effects during the second period would be a mixture of the second medication’s true effect plus lingering effects from the first medication — confounding the comparison.
Part (c): Factors determining washout length
Drug half-life: Longer-acting medications require longer washout periods (typically 5+ half-lives for complete elimination)
Mechanism of action: Some drugs cause lasting physiological adaptations that persist beyond drug elimination
Patient metabolism: Individual variation in how quickly drugs are cleared
Condition stability: The underlying condition must be stable enough to allow a period without treatment
A typical guideline is 5-7 times the drug’s elimination half-life, but this varies by drug class.
Part (d): Why randomize treatment order
Even with washout, randomizing order is essential because: - Time effects: Patients may improve (or worsen) over time regardless of treatment - Practice effects: Patients learn to take readings, report symptoms more accurately - Asymmetric carry-over: If carry-over effects aren’t completely eliminated, randomizing order ensures they balance out across treatments - Seasonal effects: If the study spans seasons, weather may affect blood pressure differently in different periods
Part (e): What the preliminary data suggests
This suggests a significant carry-over effect or treatment-by-period interaction. Medication A appears to create lasting changes that affect response to Medication B. This is problematic because: - The washout period may be insufficient - The two medications may not be suitable for crossover comparison - Analysis should account for treatment order as a factor - The researchers may need to analyze only the first period data (essentially converting to a CRD)
Exercise 6: Design Comparison
A company wants to compare three different training programs for customer service representatives. They have 90 employees available for the study. The employees vary considerably in prior experience (ranging from 1 month to 15 years).
Describe how each design would be implemented and discuss its advantages and disadvantages for this scenario.
Completely Randomized Design
Randomized Block Design (blocking by experience)
Why is Matched Pairs Design not appropriate here?
Solution
Part (a): Completely Randomized Design
Implementation: Use a random number generator to assign each of the 90 employees to one of three training programs (30 per program). After training, measure customer satisfaction scores, call resolution rates, or other performance metrics.
Advantages: - Simple to implement and explain - No need to pre-classify employees - Flexible analysis
Disadvantages: - With substantial experience variation, randomization may not balance experience across groups - Differences in outcomes might be due to experience differences rather than training effects - Lower precision (higher standard errors) because experience variation adds noise
Part (b): Randomized Block Design
Implementation: 1. Classify employees into experience blocks (e.g., 0-2 years, 2-5 years, 5+ years) 2. Within each block, randomly assign employees to training programs (equal numbers per program per block) 3. Compare training programs within each experience level, then combine results
Advantages: - Controls for experience effects - More precise comparisons (lower standard errors) - Can detect whether training effects differ by experience level - Ensures each training program is tested on employees of all experience levels
Disadvantages: - Requires knowing experience levels in advance - More complex implementation and analysis - Must decide how to define experience blocks
Part (c): Why Matched Pairs is not appropriate
Matched Pairs Design is not appropriate because: - There are three treatments, and matched pairs requires exactly two treatments per pair - Type 2 (self-pairing) would require each employee to complete all three training programs, which is impractical and creates carry-over learning effects - Type 1 would require finding pairs or triplets of employees with nearly identical characteristics — with 15-year experience range, finding truly matched sets is difficult
Recommendation: RBD is the best choice here, given the substantial experience variation and the clear blocking variable.
Exercise 7: Complete Design Specification
Design a complete experiment to test whether background music genre affects coding productivity. You have access to 48 software developers who are willing to participate. The music genres to test are: classical, electronic, and no music (silence/control).
Specify:
The experimental design type you would use and why.
The experimental units, factors, levels, treatments, and response variable.
A detailed procedure for implementing the design, including how you address each of the three principles (control, randomization, replication).
One potential threat to validity and how your design addresses it.
Solution
Part (a): Design type and justification
Recommended: Matched Pairs Type 2 (Self-pairing / Crossover Design)
Note: With 3 treatments, this is technically a within-subject design — an extension of matched pairs to more than two treatments. The same principle applies: each subject serves as their own control. “Matched pairs” terminology is traditionally for two treatments, but the logic generalizes.
Justification: Individual differences in coding ability are likely to be large. A developer who normally produces 50 lines/hour will differ from one who produces 200 lines/hour, regardless of music. Self-pairing eliminates this individual variation. Music effects are temporary (no permanent carry-over), making crossover feasible.
Alternative: If crossover is impractical (time constraints), use RBD with blocks based on programming experience or typical productivity.
Part (b): Experimental components
Experimental units: The 48 software developers (subjects)
Factor: Background music genre (1 factor)
Levels: Classical, Electronic, No music (silence) — 3 levels
Treatments: The 3 levels are the 3 treatments
Response variable: Lines of functional code written per hour (or bugs introduced, or task completion time)
Part (c): Implementation procedure
Control: - “No music” serves as the control condition - All sessions use standardized coding tasks of similar difficulty - Same environment: identical workstations, lighting, temperature - Same time of day (if practical) to control for alertness - Music played at consistent volume; headphones provided to all participants (noise-canceling without music for silence condition)
Randomization: - For each developer, randomly determine the order of the three conditions - Use a Latin Square approach or random permutation generator - Each of the 6 possible orderings should appear for approximately 8 developers
Replication: - Each of the 48 developers provides data for all 3 conditions - This yields 48 observations per treatment (high replication) - Within-person comparisons remove individual variation, increasing effective power
Procedure: 1. Day 1: Each developer completes a 2-hour coding session with their first assigned condition 2. 1-day washout (normal workday, no study activities) 3. Day 3: Second condition 4. 1-day washout 5. Day 5: Third condition 6. Compare each developer’s productivity across the three conditions
Part (d): Potential threat and mitigation
Threat: Learning/fatigue effects over the week — developers may improve (learn task format) or decline (fatigue) across sessions regardless of music.
Mitigation: Randomizing condition order across developers ensures that any time-related effects balance out across conditions. If classical always came first and electronic always came last, we couldn’t separate music effects from time effects.
8.3.7. Additional Practice Problems
True/False Questions
In a Randomized Block Design, the blocking variable is the primary focus of the study.
Type 2 Matched Pairs Design requires that treatments have reversible effects.
A Completely Randomized Design is always inferior to a Randomized Block Design.
In a crossover study, all participants receive all treatments.
The washout period in a Type 2 Matched Pairs Design should be long enough for treatment effects to dissipate.
Matched Pairs Design can only be used when comparing exactly two treatments.
Multiple Choice Questions
Which design is most appropriate when experimental units are relatively homogeneous?
Ⓐ Completely Randomized Design
Ⓑ Randomized Block Design
Ⓒ Type 1 Matched Pairs Design
Ⓓ Type 2 Matched Pairs Design
A study compares two pain relievers by having each patient try both (in random order) with a one-week break between. This is:
Ⓐ Completely Randomized Design
Ⓑ Randomized Block Design
Ⓒ Type 1 Matched Pairs Design
Ⓓ Type 2 Matched Pairs Design
In a Randomized Block Design studying three fertilizers across four soil types, how many blocks are there?
Ⓐ 3
Ⓑ 4
Ⓒ 7
Ⓓ 12
Which is NOT an advantage of blocking?
Ⓐ Reduced variability in treatment comparisons
Ⓑ Ability to detect treatment effects more easily
Ⓒ Simpler implementation than CRD
Ⓓ Control of known sources of variation
A researcher wants to compare three surgical techniques. Why is Type 2 Matched Pairs not feasible?
Ⓐ Surgery is too expensive
Ⓑ Surgical interventions are not reversible
Ⓒ There are too many techniques
Ⓓ Patients cannot consent to multiple surgeries
Carry-over effects are a concern in:
Ⓐ Completely Randomized Design
Ⓑ Randomized Block Design
Ⓒ Type 1 Matched Pairs Design
Ⓓ Type 2 Matched Pairs Design
Answers to Practice Problems
True/False Answers:
False — The blocking variable is NOT the primary focus; it’s a nuisance variable controlled to improve precision. The factor of interest is what we want to study.
True — Type 2 requires each unit to receive both treatments, so effects must dissipate before the second treatment.
False — CRD is appropriate when units are homogeneous; RBD adds complexity that isn’t needed if there’s no important blocking variable.
True — In a crossover (Type 2 Matched Pairs), each participant receives each treatment in sequence.
True — The washout must be long enough to eliminate carry-over effects; otherwise, the second treatment’s effects are confounded with residual first treatment effects.
True — Matched pairs forms blocks of size 2, requiring exactly two treatments per block.
Multiple Choice Answers:
Ⓐ — CRD works best with homogeneous units; blocking is unnecessary when units are already similar.
Ⓓ — Type 2 Matched Pairs: same person receives both treatments with washout between.
Ⓑ — There are 4 blocks (the 4 soil types). Within each block, plots are randomly assigned to the 3 fertilizers.
Ⓒ — Blocking requires more planning and more complex implementation than CRD, not simpler.
Ⓑ — Surgical procedures cannot be “undone” and repeated with a different technique on the same patient.
Ⓓ — Type 2 Matched Pairs (self-pairing/crossover) involves giving multiple treatments to the same unit, making carry-over effects a concern.