Slides 📊
6.2. Expected Value and Variance of Continuous Random Variables
Now that we understand how probability density functions work for continuous random variables, we need to extend our concepts of expected value and variance from the discrete world. The core ideas remain the same—we still want to measure the center and spread of a distribution—but the mathematical machinery shifts from summation to integration. This transition reveals the beautiful parallel structure between discrete and continuous probability theory.
Road Map 🧭
Extend expected value from discrete sums to continuous integrals.
Apply the Law of the Unconscious Statistician (LOTUS) for functions of continuous random variables.
Understand that the linearity and additive properties of expected values remain unchanged.
Define variance using integration and master the computational shortcut.
Explore properties of variance for linear transformations and sums of independent variables.
6.2.1. From Discrete Sums to Continuous Integrals
The expected value of a discrete random variable involved summing each possible value, weighted by its probability. For continuous random variables, we replace this discrete sum with a continuous integral, weighing each possible value by its probability density.
Definition
The expected value of a continuous random variable \(X\), denoted \(E[X]\) or \(\mu_X\), is the continuously weighted average of all values in its support:
This integral represents the “balance point” or center of mass of the probability distribution. Just as in the discrete case, values with higher probability density contribute more to the overall average.
Comparison with the Discrete Case
Discrete \(E[X]\) |
Continuous \(E[X]\) |
|---|---|
\[\sum_{x \in \text{supp}(X)} x \cdot p_X(x)\]
|
\[\int_{-\infty}^{\infty} x \cdot f_X(x) \, dx = \int_{\text{supp}(X)}x \cdot f_X(x) \, dx\]
|
The summation becomes an integration, and the probability mass function \(p_X(x)\) is replaced by the probability density function \(f_X(x)\). Although the integral is formally taken over the entire real line \((-\infty, \infty)\) in the general definition of continuous expectation, only values of \(x\) within the support contribute meaningfully to the computation, since \(f_X(x) = 0\) outside \(\text{supp}(X)\). Thus, the integral is effectively taken over the support—just as the summation is in the discrete case.
Remark: The Absolute Integrability Condition
For the expected value of \(X\) to be well-defined and finite, \(X\) must satisfy
All continuous distributions we encounter in this course satisfy this condition.
6.2.2. The Law of the Unconscious Statistician (LOTUS) for Continuous Random Variables
Just as in the discrete case, we often want to find the expected value of some function of a random variable, like \(E[X^2]\) or \(E[e^X]\). The Law of the Unconscious Statistician (LOTUS) extends naturally to continuous random variables.
Theorem: LOTUS
If \(X\) is a continuous random variable with PDF \(f_X(x)\), and \(g(x)\) is a function, then:
The Power of LOTUS
This theorem is powerful because it allows us to compute \(E[g(X)]\) directly without having to find the PDF of the new random variable \(Y = g(X)\). Instead, we simply plug \(g(x)\) into our expectation integral and use the original PDF \(f_X(x)\).
Example💡: Expected value of functions of \(X\)
Consider a continuous random variable \(X\) with PDF
Find \(E[X], E[X^2]\), and \(E[\sqrt{X}]\).
Find \(E[X]\) using the definition
\[E[X] = \int_0^1 x \cdot (2x) \, dx = \int_0^1 2x^2 \, dx = 2 \cdot \frac{x^3}{3}\Bigg\rvert_0^1 = \frac{2}{3}\]Apply LOTUS for \(E[X^2]\) and \(E[\sqrt{X}]\)
6.2.3. Properties of Expected Value: Unchanged by Continuity
The fundamental properties of expected value that we learned for discrete random variables apply unchanged to continuous random variables.
Linearity of Expectation
For any continuous random variable \(X\) and constants \(a\) and \(b\):
Proof of linearity of expectation
\[\begin{split}\begin{aligned} E[aX + b] &= \int_{-\infty}^{\infty} (ax + b) \cdot f_X(x) \, dx \\ &= a\int_{-\infty}^{\infty} x \cdot f_X(x) \, dx + b\int_{-\infty}^{\infty} f_X(x) \, dx \\ &= aE[X] + b \cdot 1 \\ &= aE[X] + b \end{aligned}\end{split}\]
Additivity of Expectation
For any set of continuous random variables \(X_1, X_2, \cdots, X_n\),
6.2.4. Variance for Continuous Random Variables
Definition
The variance of a continuous random variable \(X\) is the expected value of the squared deviation from the mean:
Computational Shortcut for Variance
Just as in the discrete case, we have the much more convenient computational formula:
Standard Deviation
The standard deviation is the square root of the variance:
Example💡: Computing Variance
For the random variable \(X\) with PDF
compute \(\text{Var}(X)\) and \(\sigma_X\).
Using \(E[X]\) and \(E[X^2]\) obtained in the previous example, apply the computational shortcut:
Therefore, \(\sigma_X = \sqrt{1/18} = 1/(3\sqrt{2}) \approx 0.236\).
6.2.5. Properties of Variance for Continuous Random Variables
The variance properties we learned for discrete random variables apply without modification to continuous random variables.
Variance of Linear Transformations
For any continuous random variable \(X\) and constants \(a\) and \(b\):
Recall that:
Adding a constant (\(b\)) doesn’t change how spread out a distribution is—it just shifts its location.
Multiplying by a constant (\(a\)) scales the variance by \(a^2\).
Variance of Sums of Independent Random Variables
When \(X\) and \(Y\) are independent continuous random variables:
This extends to any number of mutually independent variables:
Be Cautious 🛑
The additivity of variances only applies when the random variables are independent. This means that the mutual independence of all terms involved must be provided or mathematically shown before the rule is applied.
For dependent variables, we need to account for covariance terms.
6.2.6. Covariance and Correlation: A Brief Introduction
When dealing with multiple continuous random variables that may be dependent, we need measures of how they vary together. The concepts of covariance and correlation also extend to continuous random variables.
Covariance
The covariance between continuous random variables \(X\) and \(Y\) is:
Correlation
The correlation coefficient is:
As before, correlation is unitless and bounded between -1 and +1.
Note
Working with continuous joint distributions involves multivariable calculus and is beyond the scope of this course. We’ll focus on single continuous random variables in the remainder of this chapter.
6.2.7. Bringing It All Together
Key Takeaways 📝
The expected value of a continuous random variable uses integration instead of summation, but represents the same concept: a weighted average using probability densities as weights.
All properties of expectation (LOTUS, linearity, additivity) remain unchanged—only the computational method (integration vs. summation) differs.
Variance maintains the same conceptual meaning and computational shortcut.
Variance properties for linear transformations and sums of independent variables apply identically to continuous random variables.
6.2.8. Exercises
These exercises develop your skills in computing expected values and variances for continuous random variables using integration, applying LOTUS for functions of random variables, and using the properties of expectation and variance.
Exercise 1: Basic Expected Value and Variance Computation
A biomedical engineer models the concentration \(X\) (in mg/L) of a drug in a patient’s bloodstream with the following PDF:
Verify this is a valid PDF.
Find \(E[X]\), the expected drug concentration.
Find \(E[X^2]\) using LOTUS.
Calculate \(\text{Var}(X)\) using the computational shortcut.
Find the standard deviation \(\sigma_X\).
If the therapeutic range requires concentrations within one standard deviation of the mean, what is this range?
Solution
Part (a): Verify PDF validity
Non-negativity: \(3x^2 \geq 0\) for all \(x \in [0, 1]\). ✓
Total area = 1:
Part (b): E[X]
Part (c): E[X²] using LOTUS
Part (d): Var(X) using computational shortcut
Finding common denominator (80):
Part (e): Standard deviation
Part (f): Therapeutic range
The range within one standard deviation of the mean is:
![Quadratic PDF with E[X] = 3/4 and therapeutic range shaded](https://yjjpfnblgtrogqvcjaon.supabase.co/storage/v1/object/public/stat-350-assets/Exercises/ch6-2/fig1_quadratic_pdf_expected_value.png)
Fig. 6.4 The PDF \(f_X(x) = 3x^2\) with E[X] = 0.75 mg/L marked and the therapeutic range (μ ± σ) shaded.
Exercise 2: Decreasing Linear PDF
A reliability engineer models the failure time \(X\) (in years) of a sensor component with PDF:
Sketch the PDF. Is this distribution skewed? If so, in which direction?
Find \(E[X]\).
Find \(E[X^2]\) and \(\text{Var}(X)\).
Based on your answers, does this component tend to fail early or late in its first year?
Solution
Part (a): Sketch and skewness
The PDF starts at \(f_X(0) = 2\) and decreases linearly to \(f_X(1) = 0\). This forms a right triangle with the base on the x-axis.
Since the PDF is higher for smaller values of \(x\), the distribution is right-skewed (positively skewed). Most of the probability mass is concentrated near 0, with a long tail toward 1.
Part (b): E[X]
Part (c): E[X²] and Var(X)
Part (d): Interpretation
The expected failure time is only \(\frac{1}{3}\) year (4 months), which is well before the midpoint of the first year. Combined with the right-skewed distribution, this indicates the component tends to fail early. The decreasing PDF shows that failures become progressively less likely as time passes—components that survive the initial period are less likely to fail later.
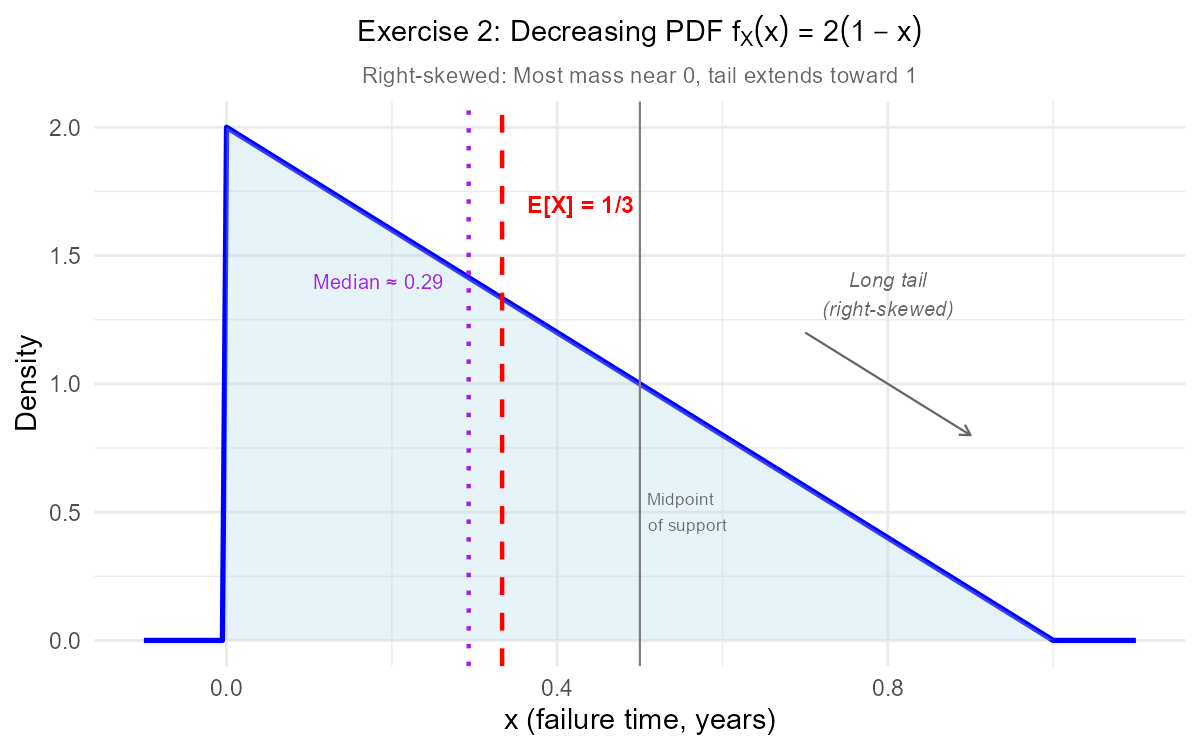
Fig. 6.5 The decreasing PDF \(f_X(x) = 2(1-x)\) is right-skewed with most mass concentrated near 0.
Exercise 3: LOTUS with Multiple Functions
An aerospace engineer models aerodynamic drag coefficient \(X\) with PDF:
Verify this is a valid PDF.
Find \(E[X]\).
Find \(E[X^2]\).
Find \(E[X^3]\).
The power required to overcome drag is proportional to \(X^3\). If \(P = 100X^3\) watts, find \(E[P]\).
A naive calculation substitutes \(E[X]\) into the power formula, computing \(g(E[X]) = 100 \cdot (E[X])^3\) instead of \(E[P]\). What value would this give? Which is correct and why do they differ?
Solution
Part (a): Verify PDF validity
Non-negativity: \(\frac{3}{8}x^2 \geq 0\) for all \(x\). ✓
Total area = 1:
Part (b): E[X]
Part (c): E[X²]
Part (d): E[X³]
Part (e): E[P] using LOTUS
Since \(P = 100X^3\):
Part (f): Naive calculation and comparison
The naive calculation substitutes \(E[X]\) directly into the power formula:
The correct expected power is 400 watts (from LOTUS).
Why they differ: In general, \(E[g(X)] \neq g(E[X])\) unless \(g\) is a linear function. The power function \(g(x) = 100x^3\) is convex (curves upward for \(x > 0\)), which means \(E[g(X)] > g(E[X])\). Because \(g(x)\) is convex, variability in \(X\) increases the expected value of \(g(X)\).
The naive approach underestimates average power because it ignores variability. Higher-than-average drag coefficients contribute disproportionately to power consumption due to the cubic relationship.
![Convex function showing E[g(X)] greater than g(E[X])](https://yjjpfnblgtrogqvcjaon.supabase.co/storage/v1/object/public/stat-350-assets/Exercises/ch6-2/fig3_jensen_convex.png)
Fig. 6.6 For the convex function \(g(x) = 100x^3\), we have \(E[g(X)] = 400 > g(E[X]) = 337.5\).
Exercise 4: Symmetric Distribution and Expected Value
A quality control engineer models measurement error \(X\) (in mm) with PDF:
Verify this is a valid PDF.
This PDF is symmetric about \(x = 0\). Use this fact to determine \(E[X]\) without integration.
Find \(E[X^2]\).
Calculate \(\text{Var}(X)\).
Find \(E[X^4]\). (Hint: You’ll need this for problems involving variance of \(X^2\).)
Solution
Part (a): Verify PDF validity
Non-negativity: For \(-1 \leq x \leq 1\), we have \(x^2 \leq 1\), so \(1 - x^2 \geq 0\). Thus \(f_X(x) = \frac{3}{4}(1-x^2) \geq 0\). ✓
Total area = 1:
Part (b): E[X] by symmetry
The PDF \(f_X(x) = \frac{3}{4}(1-x^2)\) is an even function (symmetric about \(x = 0\)):
When a PDF is symmetric about \(x = c\), the expected value equals \(c\).
Therefore, \(E[X] = 0\).
Part (c): E[X²]
Since \(x^2 - x^4\) is an even function, we can use:
Part (d): Var(X)
Part (e): E[X⁴]
Using symmetry:
![Symmetric parabolic PDF with E[X] = 0](https://yjjpfnblgtrogqvcjaon.supabase.co/storage/v1/object/public/stat-350-assets/Exercises/ch6-2/fig4_symmetric_pdf.png)
Fig. 6.7 The symmetric PDF \(f_X(x) = \frac{3}{4}(1-x^2)\) has \(E[X] = 0\) by symmetry—no integration needed!
Exercise 5: Linear Transformations
A chemical engineer measures temperature \(X\) in Celsius with \(E[X] = 25°C\) and \(\sigma_X = 3°C\).
Convert to Fahrenheit using \(F = \frac{9}{5}X + 32\). Find \(E[F]\) and \(\sigma_F\).
Convert to Kelvin using \(K = X + 273.15\). Find \(E[K]\) and \(\sigma_K\).
A control system triggers an alarm when temperature deviates more than 2 standard deviations from the mean. Express this range in all three temperature scales.
Why does adding a constant (like 273.15 for Kelvin) not change the standard deviation?
Solution
Part (a): Fahrenheit conversion
Using \(F = \frac{9}{5}X + 32\):
Expected value (linearity):
Standard deviation (variance of linear transformation):
Alternatively: \(\sigma_F = \left|\frac{9}{5}\right| \sigma_X = \frac{9}{5} \times 3 = 5.4°F\)
Part (b): Kelvin conversion
Using \(K = X + 273.15\):
Expected value:
Standard deviation:
The standard deviation is unchanged because adding a constant only shifts the distribution, not its spread.
Part (c): Alarm range (±2σ from mean)
Celsius: \(25 \pm 2(3) = (19, 31)°C\)
Fahrenheit: \(77 \pm 2(5.4) = (66.2, 87.8)°F\)
Kelvin: \(298.15 \pm 2(3) = (292.15, 304.15)\) K
Part (d): Why adding a constant doesn’t change σ
Variance measures spread—how far values deviate from the mean. When we add a constant \(b\) to every value:
Every observation shifts by the same amount
The mean also shifts by that same amount
The deviations from the mean remain unchanged: \((X + b) - (\mu + b) = X - \mu\)
Since variance is based on squared deviations, and those deviations don’t change, variance (and therefore standard deviation) remains the same.
Mathematically: \(\text{Var}(X + b) = E[(X + b - E[X + b])^2] = E[(X - \mu_X)^2] = \text{Var}(X)\)
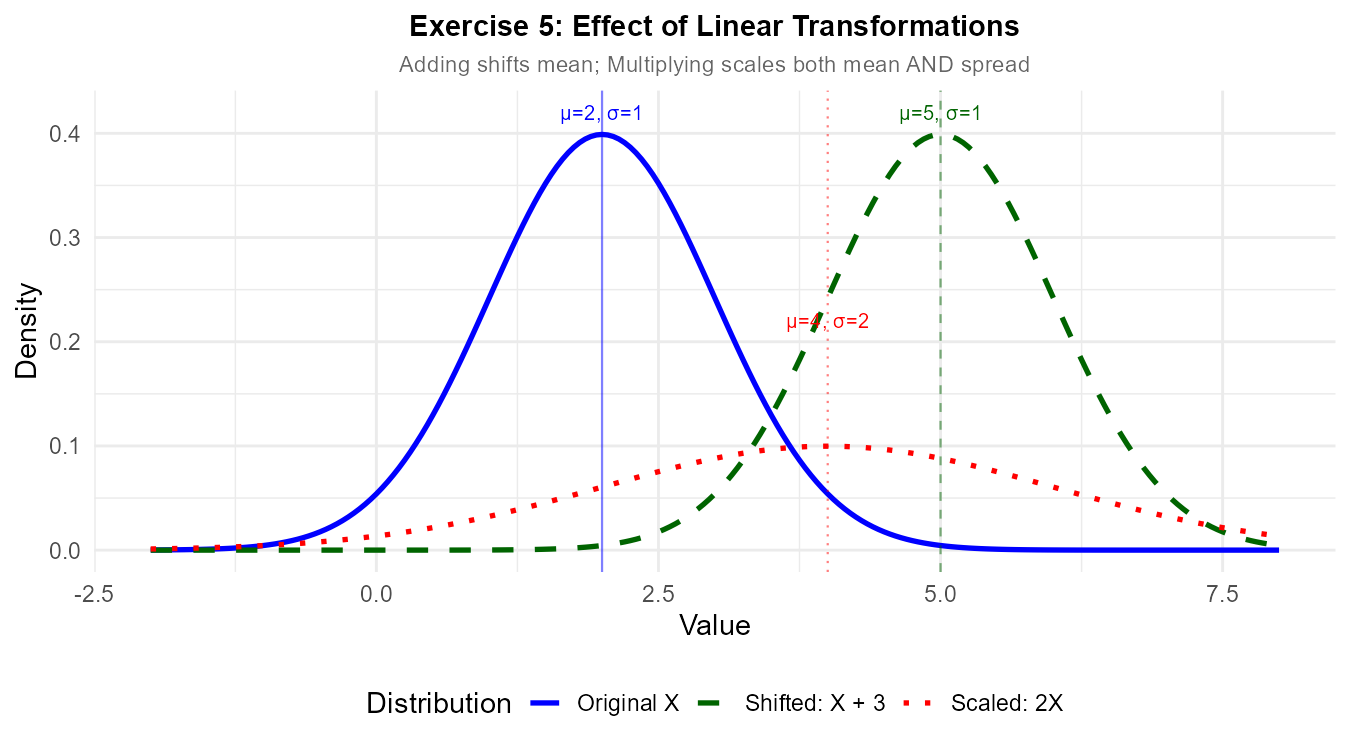
Fig. 6.8 Linear transformations: Adding a constant shifts the mean but preserves spread; multiplying scales both mean and spread.
Exercise 6: Sum of Independent Random Variables
A data center has three independent server racks. The power consumption \(X_i\) (in kW) of each rack has \(E[X_i] = 15\) kW and \(\text{Var}(X_i) = 4\) kW².
Find the expected total power consumption \(E[X_1 + X_2 + X_3]\).
Find \(\text{Var}(X_1 + X_2 + X_3)\) and the standard deviation of total power.
The facility has a 50 kW power budget. How many standard deviations above the expected total is this budget?
If a fourth identical rack is added, find the new expected total and standard deviation.
By what factor does the standard deviation increase when going from 3 to 4 racks? Is this more or less than the factor increase in expected value?
Solution
Part (a): Expected total power
By additivity of expectation:
Part (b): Variance and SD of total power
Since the racks are independent, variances add:
Part (c): Budget margin in standard deviations
The 50 kW budget is about 1.44 standard deviations above the expected consumption.
Part (d): Four racks
Expected total:
Variance:
Standard deviation:
Part (e): Factor comparison
Standard deviation factor: \(\frac{4}{2\sqrt{3}} = \frac{4}{3.46} \approx 1.155\) (or exactly \(\frac{2}{\sqrt{3}} = \sqrt{\frac{4}{3}}\))
Expected value factor: \(\frac{60}{45} = \frac{4}{3} \approx 1.333\)
The standard deviation increases by a smaller factor than the expected value.
Key insight: For \(n\) independent, identically distributed random variables:
Expected value of sum = \(n \cdot \mu\) (scales linearly with \(n\))
Standard deviation of sum = \(\sqrt{n} \cdot \sigma\) (scales with \(\sqrt{n}\))
This “square root law” means that relative variability decreases as we add more independent components—an important principle in risk diversification.
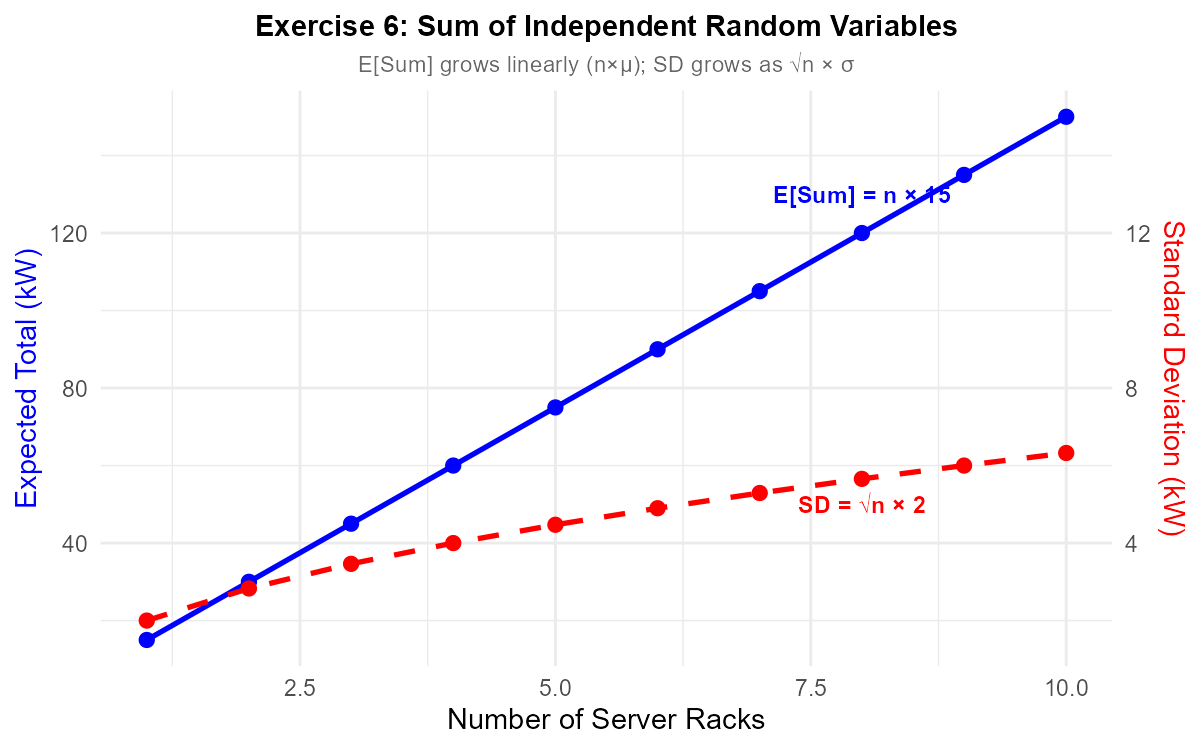
Fig. 6.9 For sums of independent RVs: \(E[\text{Sum}]\) grows linearly with \(n\), while \(\sigma_{\text{Sum}}\) grows as \(\sqrt{n}\).
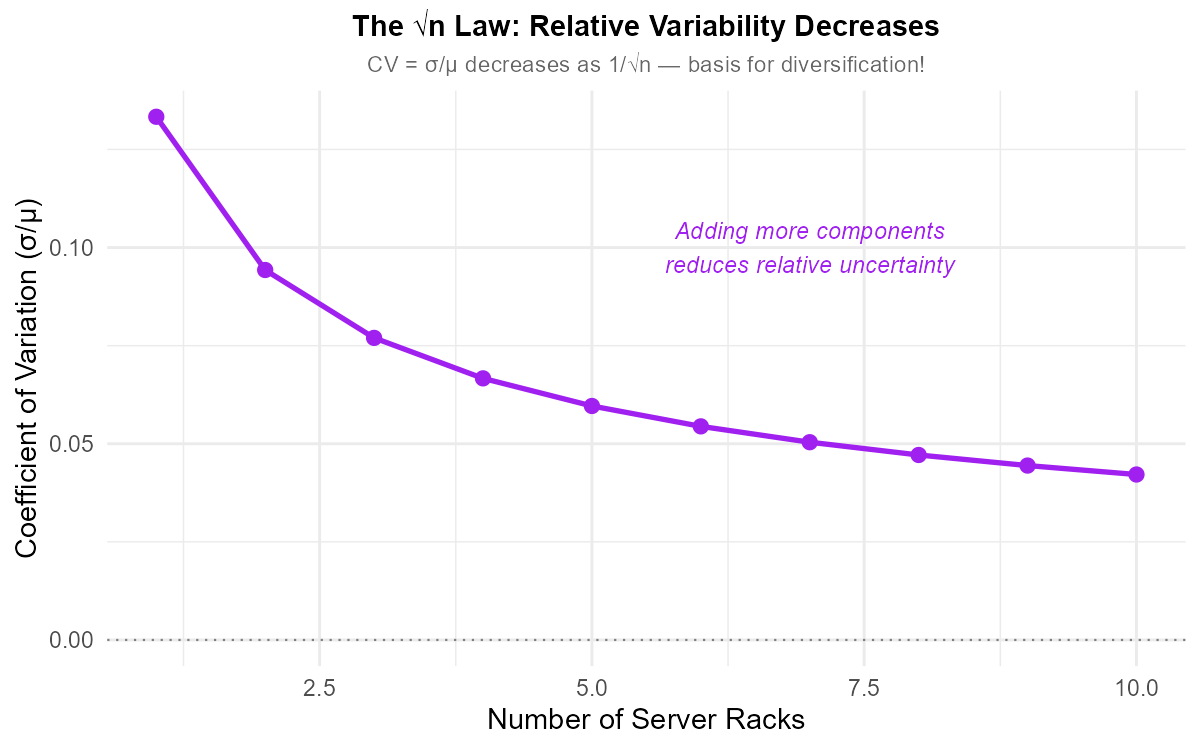
Fig. 6.10 The √n law: Relative variability (CV = σ/μ) decreases as \(1/\sqrt{n}\)—the basis for diversification benefits.
Exercise 7: Piecewise PDF with Expected Value
A network engineer models packet sizes \(X\) (in KB) with PDF:
Verify this is a valid PDF. (Hint: Compute each piece separately.)
This is a triangular distribution. Identify its mode (peak).
Use symmetry to find \(E[X]\).
Find \(E[X^2]\) by computing the integral over both pieces.
Calculate \(\text{Var}(X)\).
Solution
Part (a): Verify PDF validity
Non-negativity:
For \(0 \leq x \leq 2\): \(\frac{x}{4} \geq 0\) ✓
For \(2 < x \leq 4\): \(4 - x \geq 0\), so \(\frac{4-x}{4} \geq 0\) ✓
Total area = 1:
First integral:
Second integral:
Total: \(\frac{1}{2} + \frac{1}{2} = 1\) ✓
Part (b): Mode
The mode is where the PDF reaches its maximum. Both pieces meet at \(x = 2\) with \(f_X(2) = \frac{2}{4} = \frac{1}{2}\).
Mode = 2 KB
Part (c): E[X] by symmetry
The triangular PDF is symmetric about \(x = 2\) (the peak).
By symmetry: \(E[X] = 2\) KB
Part (d): E[X²]
First integral:
Second integral:
Part (e): Var(X)
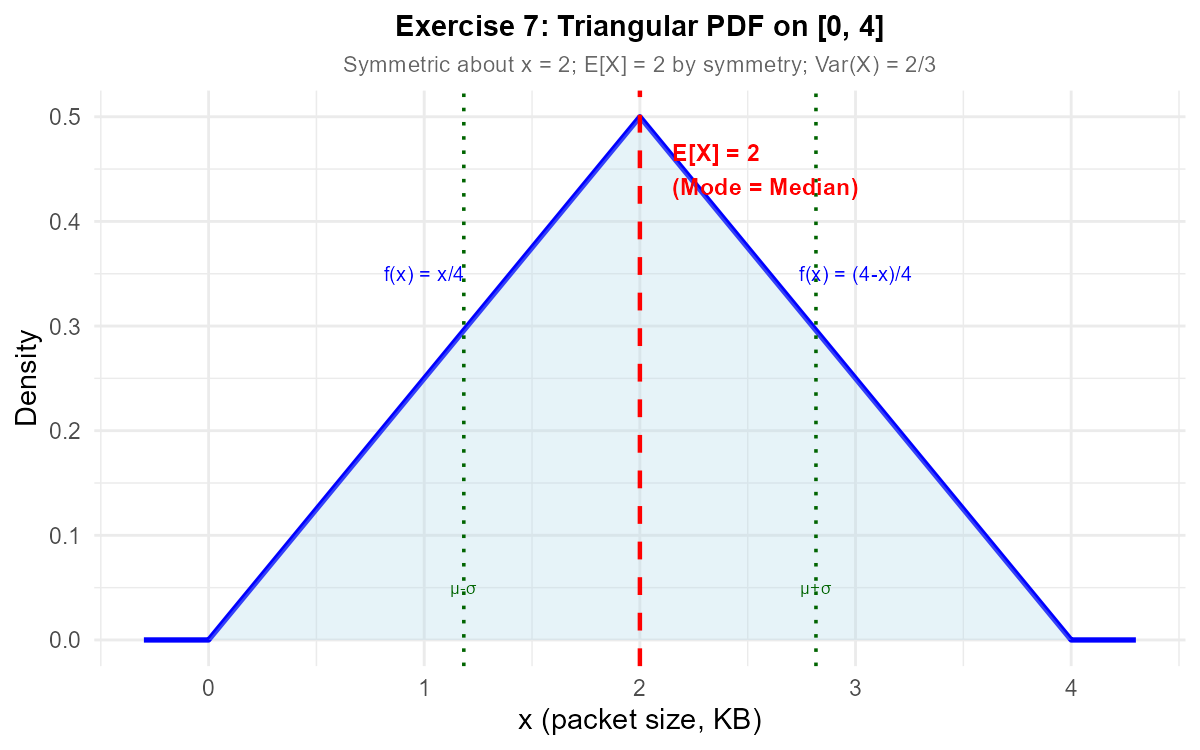
Fig. 6.11 The triangular PDF is symmetric about \(x = 2\), so \(E[X] = 2\) by symmetry.
Exercise 8: LOTUS with Non-Polynomial Functions
A materials scientist models crack length \(X\) (in mm) with the uniform PDF:
Find \(E[X]\) and \(\text{Var}(X)\).
Find \(E[\sqrt{X}]\) using LOTUS.
Find \(E[e^X]\) using LOTUS.
Compare \(E[\sqrt{X}]\) with \(\sqrt{E[X]}\). Which is larger and why?
Compare \(E[e^X]\) with \(e^{E[X]}\). Which is larger and why?
Solution
Part (a): E[X] and Var(X)
Part (b): E[√X] using LOTUS
Part (c): E[eˣ] using LOTUS
Part (d): Compare E[√X] with √E[X]
\(E[\sqrt{X}] = \frac{2}{3} \approx 0.667\)
\(\sqrt{E[X]} = \sqrt{\frac{1}{2}} = \frac{1}{\sqrt{2}} \approx 0.707\)
\(E[\sqrt{X}] < \sqrt{E[X]}\)
Explanation: The square root function \(g(x) = \sqrt{x}\) is concave (curves downward). For concave functions, we have:
Intuitively: the square root “compresses” larger values more than smaller values, so averaging first (then taking the root) gives a higher result than taking roots first (then averaging).
Part (e): Compare E[eˣ] with e^{E[X]}
\(E[e^X] = e - 1 \approx 1.718\)
\(e^{E[X]} = e^{1/2} = \sqrt{e} \approx 1.649\)
\(E[e^X] > e^{E[X]}\)
Explanation: The exponential function \(g(x) = e^x\) is convex (curves upward). For convex functions, we have:
Intuitively: the exponential “amplifies” larger values more than smaller values, so the average of exponentials exceeds the exponential of the average.
![Concave square root function showing E[g(X)] less than g(E[X])](https://yjjpfnblgtrogqvcjaon.supabase.co/storage/v1/object/public/stat-350-assets/Exercises/ch6-2/fig8a_jensen_concave.png)
Fig. 6.12 Concave function \(g(x) = \sqrt{x}\): \(E[g(X)] \leq g(E[X])\).
![Convex exponential function showing E[g(X)] greater than g(E[X])](https://yjjpfnblgtrogqvcjaon.supabase.co/storage/v1/object/public/stat-350-assets/Exercises/ch6-2/fig8b_jensen_convex.png)
Fig. 6.13 Convex function \(g(x) = e^x\): \(E[g(X)] \geq g(E[X])\).
Exercise 9: Variance of a Transformed Variable
A computer scientist models algorithm runtime \(X\) (in seconds) with PDF:
Find \(E[X]\), \(E[X^2]\), and \(\text{Var}(X)\).
The cost function is \(C = 5X + 10\) dollars. Find \(E[C]\) and \(\text{Var}(C)\).
A quadratic cost model uses \(Q = 3X^2\). Find \(E[Q]\).
For the quadratic cost \(Q = 3X^2\), find \(\text{Var}(Q)\). (Hint: You need \(E[X^4]\).)
Solution
Part (a): Basic moments
Part (b): Linear cost C = 5X + 10
Using linearity of expectation:
Using variance of linear transformation:
Part (c): Quadratic cost Q = 3X²
Note: \(Q\) is defined as a cost in dollars, where the coefficient 3 carries units of dollars/second² to ensure dimensional consistency.
Using LOTUS:
Part (d): Var(Q) for Q = 3X²
We need \(E[Q^2] = E[9X^4] = 9E[X^4]\).
First, find \(E[X^4]\):
Now:
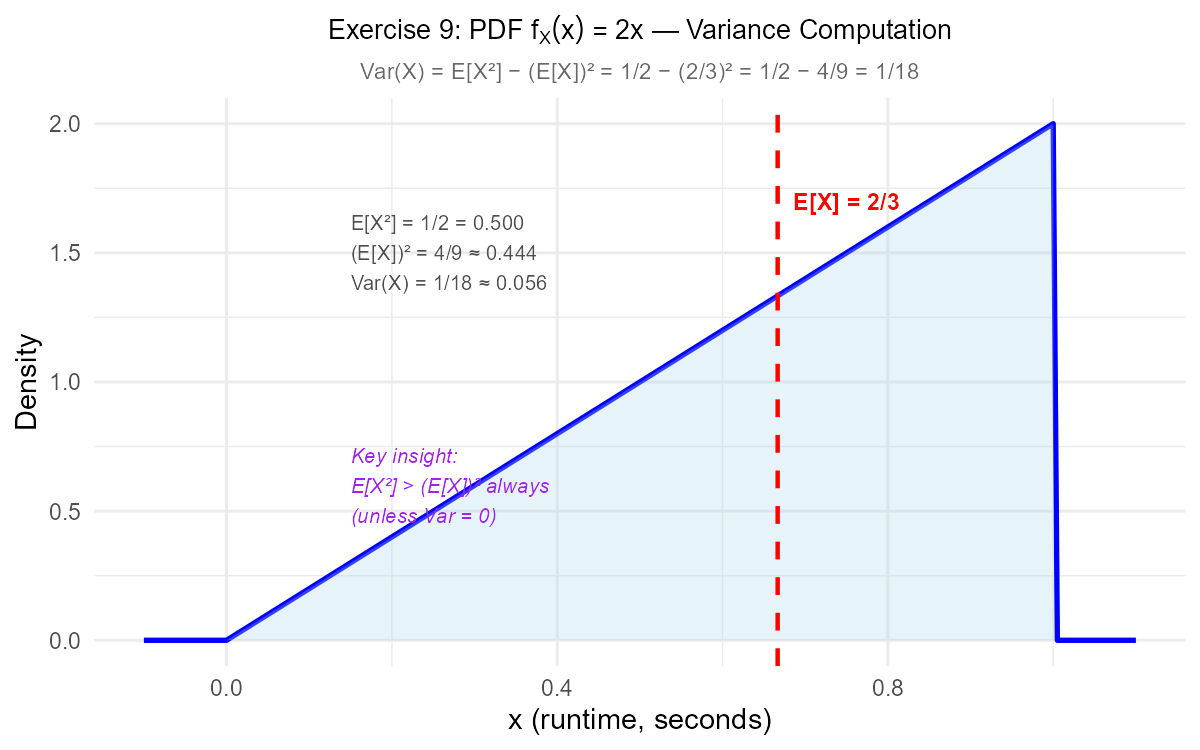
Fig. 6.14 The variance shortcut: \(\text{Var}(X) = E[X^2] - (E[X])^2\). Note that \(E[X^2] > (E[X])^2\) always (unless Var = 0).
6.2.9. Additional Practice Problems
True/False Questions (1 point each)
For a continuous random variable, \(E[X^2] = (E[X])^2\).
Ⓣ or Ⓕ
If \(X\) has PDF symmetric about \(x = 5\), then \(E[X] = 5\).
Ⓣ or Ⓕ
For any random variable \(X\) and constant \(c\), \(\text{Var}(X + c) = \text{Var}(X)\).
Ⓣ or Ⓕ
If \(X\) and \(Y\) are independent, then \(\text{Var}(X + Y) = \text{Var}(X) + \text{Var}(Y)\).
Ⓣ or Ⓕ
\(E[3X + 2] = 3E[X] + 2\) is an example of the linearity of expectation.
Ⓣ or Ⓕ
For any function \(g(x)\), \(E[g(X)] = g(E[X])\).
Ⓣ or Ⓕ
Variance can never be negative.
Ⓣ or Ⓕ
If \(\text{Var}(X) = 9\), then \(\text{Var}(2X) = 18\).
Ⓣ or Ⓕ
Multiple Choice Questions (2 points each)
For \(f_X(x) = 2x\) on \([0, 1]\), what is \(E[X]\)?
Ⓐ 1/3
Ⓑ 1/2
Ⓒ 2/3
Ⓓ 3/4
If \(E[X] = 4\) and \(E[X^2] = 20\), what is \(\text{Var}(X)\)?
Ⓐ 4
Ⓑ 16
Ⓒ 20
Ⓓ 36
If \(\text{Var}(X) = 5\), what is \(\text{Var}(3X - 7)\)?
Ⓐ 5
Ⓑ 8
Ⓒ 15
Ⓓ 45
If \(X\) and \(Y\) are independent with \(\text{Var}(X) = 3\) and \(\text{Var}(Y) = 5\), what is \(\text{Var}(X + Y)\)?
Ⓐ 2
Ⓑ 8
Ⓒ 15
Ⓓ 64
For \(f_X(x) = 3x^2\) on \([0, 1]\), what is \(E[X^2]\)?
Ⓐ 1/2
Ⓑ 3/5
Ⓒ 3/4
Ⓓ 4/5
Which property allows us to compute \(E[X^2]\) directly from \(f_X(x)\) without finding the PDF of \(X^2\)?
Ⓐ Linearity of expectation
Ⓑ Additivity of variance
Ⓒ Law of the Unconscious Statistician (LOTUS)
Ⓓ Variance shortcut formula
Answers to Practice Problems
True/False Answers:
False — In general, \(E[X^2] \geq (E[X])^2\). Equality holds only when \(\text{Var}(X) = 0\) (i.e., \(X\) is a constant).
True — Symmetry about \(x = c\) implies \(E[X] = c\) (the balance point).
True — Adding a constant shifts all values but doesn’t change the spread. \(\text{Var}(X + c) = \text{Var}(X)\).
True — For independent random variables, variances add: \(\text{Var}(X + Y) = \text{Var}(X) + \text{Var}(Y)\).
True — This is exactly the linearity property: \(E[aX + b] = aE[X] + b\).
False — In general, \(E[g(X)] \neq g(E[X])\) unless \(g\) is linear. This is why LOTUS is needed.
True — Variance is \(E[(X - \mu)^2]\), an expected value of squared terms, which cannot be negative.
False — \(\text{Var}(2X) = 2^2 \cdot \text{Var}(X) = 4 \times 9 = 36\), not 18.
Multiple Choice Answers:
Ⓒ — \(E[X] = \int_0^1 x \cdot 2x \, dx = 2 \cdot \frac{1}{3} = \frac{2}{3}\).
Ⓐ — \(\text{Var}(X) = E[X^2] - (E[X])^2 = 20 - 16 = 4\).
Ⓓ — \(\text{Var}(3X - 7) = 3^2 \cdot \text{Var}(X) = 9 \times 5 = 45\).
Ⓑ — For independent RVs: \(\text{Var}(X + Y) = \text{Var}(X) + \text{Var}(Y) = 3 + 5 = 8\).
Ⓑ — \(E[X^2] = \int_0^1 x^2 \cdot 3x^2 \, dx = 3 \cdot \frac{1}{5} = \frac{3}{5}\).
Ⓒ — LOTUS (Law of the Unconscious Statistician) allows \(E[g(X)] = \int g(x) f_X(x) \, dx\) directly.