Slides 📊
3.2. Measures of Central Tendency
When analyzing data, one of the first questions we ask is: “What’s the typical value?” In this chapter, we’ll explore three fundamental measures of central tendency that can be used to answer this question.
For simplicity, we will denote the variable under study as \(x\) throughout this section.
Road Map 🧭
Define sample mode, sample mean, and sample median. Learn their mathematical notations and properties.
Describe the strengths and weaknesses of each measure, and recognize which measure is the most appropriate given a data set.
3.2.1. Sample Mode, \(M\)
The sample mode is the simplest measure of central tendency—it’s the value that occurs most frequently in a dataset. We denote the sample mode with \(M\).
Properties
A data set might have zero, one, or more than one mode.
Zero when all values occur with equal frequency
One when exactly one value occurs most frequently
“Multimodal” when multiple values tie for the most frequent
A dataset with one mode is called unimodal. Datasets with two and three modes are called bimodal and trimodal, respectively.
The sample mode is most useful when working with discrete numerical data with a limited set of possible values.
It is less informative when the data contains many unique values with few repetitions. For this reason, the sample mode is not often used unless the data set is very simple.
Example 💡: Finding the Sample Mode
Consider this simple dataset: {1, 1, 2, 3, 4}
Computing the mode by hand
Since 1 occurs with the highest frequency, \(M = 1\).
Computing the mode on R
R does not have a built-in function for computing the sample mode. Therefore, we create a new function:
# define a new function:
getmode <- function(v) {
uniqv <- unique(v)
uniqv[which.max(tabulate(match(v, uniqv)))]
}
# define data
x <- c(1,1,2,3,4)
# use the newly defined function
getmode(x) # returns 1
🛑 Note: You may copy and paste the function above for your own use. If you are interested in learning how to create your own R functions, a general guide is provided in the appendix. However, you are not expected to write custom R functions in this course.
3.2.2. Sample Mean, \(\bar{x}\)
The sample mean, denoted as \(\bar{x}\) (pronounced “x-bar”), is what most people think of as the “average.” The sample mean is calculated by summing all observations and dividing by the sample size:
Properties
It is influenced by each observation in the dataset.
It can be affected significantly by outliers or extreme values.
Example 💡: Finding the Sample Mean
For the dataset \(\{2, 4, 6, 8\}\),
R provides a built-in function for calculating the mean.
x <- c(2, 4, 6, 8)
mean(x) # Returns 5
3.2.3. Sample Median, \(\tilde{x}\)
The sample median, denoted as \(\tilde{x}\) (pronounced “x-tilde”), is the middle value of the data arranged in order. It splits the data set so that 50% of the observations fall below and another 50% above it.
How to find the sample median
Arrange all observations in ascending order.
If there is an odd number of observations, the median is the middle value.
If there is an even number of observations, the median is the average of the two middle values.
Mathematically,
where \(x_{(i)}\) represents the \(i\)-th smallest value in the data set.
Properties
It depends only on the order (ranks) of most of the data, not the exact values.
It is robust to outliers—few extreme values don’t usually change a median.
Example 💡: Finding the sample median when \(n\) is odd
Take the data set \(\{1, 2, 4, 6, 8\}\). The data is already sorted with \(n = 5\).
The median is \(\tilde{x} = x_{(3)} = 4\).
y <- c(1, 2, 4, 6, 8)
median(y) # Returns 4
Example 💡: Finding the sample median when \(n\) is even
The dataset \(\{2, 4, 6, 8\}\) has \(n=4\), which is even. \(\frac{n}{2} = \frac{4}{2} = 2\). The median is the average of the 2nd and 3rd values:
x <- c(2, 4, 6, 8)
median(x) # Returns 5
3.2.4. Comparing the Measures: An Example
To better understand how the different measures of central tendency work in practice, let’s explore an example in depth.
Part 1
Miss Claridge asked her preschool class of nine students how many pets each had in their household. The results are recorded in the table below. A dot plot of the data is shown in Fig. 3.1.
Unsorted pet counts data |
||||||||
|---|---|---|---|---|---|---|---|---|
4 |
8 |
7 |
9 |
4 |
3 |
5 |
1 |
4 |
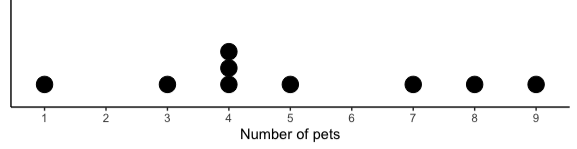
Fig. 3.1 Dot plot of pet counts
We will analyze this data using the three measures of central tendency. Let us begin by expressing the data using formal notation. Denote the variable of pet counts with \(x\). We have \(n=9\). The individual data points are then denoted as \(x_1, x_2, \cdots, x_9\).
Sample Mode
The value 4 occurs most frequently (three times). Therefore, \(M = 4\).
Sample Mean
\[\bar{x} = \frac{1}{9}\sum_{i=1}^9 x_i = \frac{1}{9}(4 + 8 + 7 + 9 + 4 + 3 + 5 + 1 + 4) = \frac{45}{9} = 5\]Sample Median
First, sort the data: \(\{1, 3, 4, 4, 4, 5, 7, 8, 9\}\). Since \(n\) is odd, compute \((9+1)/2 = 5\). The median is the 5th value. \(\tilde{x} = 4\).
Part 2
Miss Claridge discovers that there was an error during the data recording process; the student who was recorded as having nine pets actually had nineteen. How will the measures change due to this update?
New sorted pet counts data |
||||||||
|---|---|---|---|---|---|---|---|---|
1 |
3 |
4 |
4 |
4 |
5 |
7 |
8 |
9 → 19 |
Sample Mode
The value 4 still occurs most frequently. \(M = 4\).
Sample Mean
\[\bar{x} = \frac{1}{9}\sum_{i=1}^9 x_i = \frac{1}{9}(1+3+4+4+4+5+7+8+19) = \frac{55}{9} = 6.11\]Sample Median
\(n\) did not change. \((9+1)/2 = 5\). The median is still the 5th value. \(\tilde{x} = 4\).
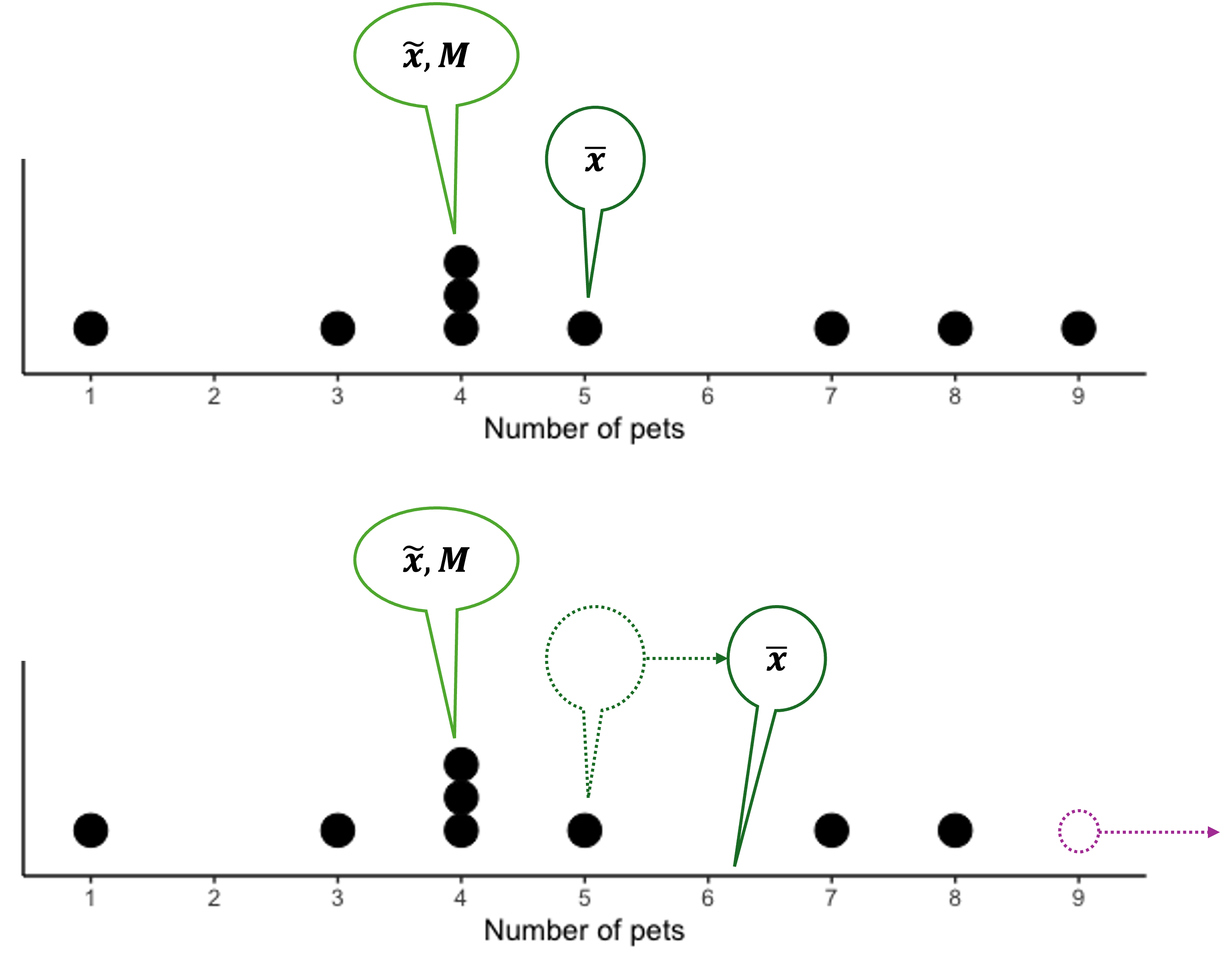
Fig. 3.2 Upper graph: central tendency measures before update. Lower: after update.
In Part 2, both the sample mode and median remained at 4, while the sample mean increased from 5 to 6.11. This illustrates how the sample mean is pulled towards all data points, including outliers and extreme values. In contrast, the sample median and mode are more resistant to such influences.
3.2.5. Bringing It All Together
Key Takeaways 📝
Measures of central tendency indicate where the majority of the data is centered, bunched, or clustered.
The sample mode (\(M\)) finds the most frequent value(s) and works best for discrete data with few unique values.
The sample mean (\(\bar{x}\)) calculates the arithmetic average.
The sample median (\(\tilde{x}\)) finds the middle value and is robust against extreme values.
Appendix: Defining Your Own Functions in R
As we’ve seen with our sample mode function, R allows us to create custom functions for statistical operations that aren’t built into the language. The basic structure of a function in R is:
function_name <- function(argument1, argument2, ...) {
# Code goes between brackets
return(return_value) # Can return a single entity
}
Let’s break down the components:
Function name: The name you’ll use when calling the function
Arguments: The list of input values
Arguments can have default values:
function(argument = 0)You can create functions with no arguments:
function()
Function body (Everything between the curly brackets
{ }): code describing the steps to be taken when the function is calledReturn value: What the function outputs after computation
3.2.6. Exercises
These exercises build your skills in calculating and interpreting the three measures of central tendency: mode, mean, and median.
Exercise 1: Calculating Measures of Central Tendency
A quality control engineer records the number of defects found in 12 randomly inspected circuit boards:
Calculate the sample mode (\(M\)).
Calculate the sample mean (\(\bar{x}\)). Show your work using summation notation.
Calculate the sample median (\(\tilde{x}\)). Show the sorted data and your calculation.
Which measure best represents the “typical” number of defects for this data? Justify your answer.
Verify your calculations using R.
Solution
Part (a): Sample Mode
First, count the frequency of each value:
0 appears 2 times
1 appears 3 times
2 appears 5 times ← most frequent
3 appears 1 time
4 appears 1 time
\(M = 2\) defects
Part (b): Sample Mean
Part (c): Sample Median
First, sort the data in ascending order:
Since \(n = 12\) is even, the median is the average of the 6th and 7th values:
Part (d): Best Measure
For this discrete count data, either the mode or median would be appropriate:
Mode (M = 2): Most frequently observed defect count
Median (x̃ = 2): Middle value, robust to the higher counts
Mean (x̄ = 1.67): Also reasonable, but gives a non-integer for count data
Since defects are discrete counts and the distribution is slightly right-skewed (has a few higher values like 3 and 4), the median or mode might be preferred for describing the “typical” board.
Part (e): R Verification
defects <- c(2, 0, 1, 3, 2, 1, 2, 4, 1, 2, 0, 2)
# Mean
mean(defects) # Returns 1.666667
# Median
median(defects) # Returns 2
# Mode (custom function)
getmode <- function(v) {
uniqv <- unique(v)
uniqv[which.max(tabulate(match(v, uniqv)))]
}
getmode(defects) # Returns 2
Exercise 2: Effect of Outliers on Central Tendency
A startup tracks the daily number of app downloads for 10 consecutive days:
Calculate the mean, median, and mode for this data.
On day 11, the app goes viral and receives 500 downloads. Add this value to the dataset and recalculate all three measures.
Create a table comparing the measures before and after adding the viral day. Which measure changed the most (in percentage terms)? Which changed the least?
If you were reporting “typical daily downloads” to investors, which measure would you use after the viral day? Explain your reasoning.
Solution
Part (a): Original Data (n = 10)
Sorted: \(\{45, 46, 47, 48, 48, 49, 50, 51, 52, 53\}\)
Mode: \(M = 48\) (appears twice; all others appear once)
Mean: \(\bar{x} = \frac{45+52+48+51+47+49+53+46+50+48}{10} = \frac{489}{10} = 48.9\)
Median: \(\tilde{x} = \frac{x_{(5)} + x_{(6)}}{2} = \frac{48 + 49}{2} = 48.5\)
Part (b): With Viral Day (n = 11)
New data: \(\{45, 52, 48, 51, 47, 49, 53, 46, 50, 48, 500\}\)
Sorted: \(\{45, 46, 47, 48, 48, 49, 50, 51, 52, 53, 500\}\)
Mode: \(M = 48\) (still appears twice)
Mean: \(\bar{x} = \frac{489 + 500}{11} = \frac{989}{11} = 89.9\)
Median: \(\tilde{x} = x_{(6)} = 49\) (6th value when n = 11)
Part (c): Comparison Table
Measure |
Before |
After |
% Change |
|---|---|---|---|
Mode |
48 |
48 |
0% |
Median |
48.5 |
49 |
1.0% |
Mean |
48.9 |
89.9 |
83.8% |
Changed most: Mean (increased by 83.8%)
Changed least: Mode (no change)
Part (d): Which Measure to Report?
After the viral day, the median (49) would be the best choice for reporting “typical daily downloads.”
Reasons:
The mean (89.9) is heavily distorted by the single outlier and doesn’t represent any typical day
The mode (48) only reflects frequency, not central tendency in the traditional sense
The median (49) represents what investors could expect on a “normal” day
For skewed data with outliers, the median is more representative of typical behavior
You might report both: “Typical daily downloads are around 49, with one viral day reaching 500.”
Exercise 3: Interpreting Differences Between Measures
For each scenario below, determine the likely relationship between the mean and median (mean > median, mean < median, or mean ≈ median). Explain your reasoning.
Home sale prices in a neighborhood where most homes are modest but a few luxury mansions exist.
Exam scores on a test that most students found easy, with a few students performing poorly.
Heights of adult males in a large random sample.
Time to complete an online checkout process, where most transactions are quick but some have technical difficulties causing long delays.
A company reports that their employees’ mean salary is $85,000 and median salary is $62,000. What does this suggest about the salary distribution?
Solution
Part (a): Home Sale Prices
Mean > Median (right-skewed)
The few luxury mansions with very high prices pull the mean upward, while the median remains near the price of a typical modest home. This is why real estate often reports median home prices.
Part (b): Exam Scores (Easy Test)
Mean < Median (left-skewed)
Most students score high (clustered near the top), but a few low scores pull the mean down. The median remains high because it’s resistant to the low outliers.
Part (c): Adult Male Heights
Mean ≈ Median (approximately symmetric)
Heights follow an approximately normal distribution, which is symmetric. In symmetric distributions, the mean and median are equal or very close.
Part (d): Checkout Time
Mean > Median (right-skewed)
Most transactions are quick, but occasional long delays create a right tail. The mean is pulled up by these outliers, while the median reflects the typical quick transaction.
Part (e): Salary Distribution
The large gap between mean ($85,000) and median ($62,000) suggests:
The distribution is strongly right-skewed
A relatively small number of high earners (executives, senior staff) have salaries much higher than most employees
The “typical” employee earns around $62,000 (the median)
The high salaries at the top pull the mean up to $85,000
This is common in salary distributions and explains why labor statistics often report median wages rather than mean wages.
Exercise 4: Choosing the Appropriate Measure
For each situation, identify which measure of central tendency (mode, mean, or median) is most appropriate. Justify your choice.
A shoe store wants to know which size to stock most heavily.
A professor wants to report the typical performance on an exam where scores are approximately normally distributed.
An economist wants to describe the typical household income in a city with significant wealth inequality.
A server administrator wants to report typical response times, knowing that occasional network issues cause very long delays.
A survey asks customers to rate satisfaction on a 1-5 scale. The company wants to report the most common rating.
A manufacturing process produces parts where nearly all measurements cluster tightly around the target, with no outliers.
Solution
Part (a): Shoe Size to Stock
Mode is most appropriate.
The store needs to know the most frequently purchased size
Shoe sizes are discrete categories
Mean shoe size (e.g., 9.3) doesn’t help inventory decisions
Median might miss the peak if the distribution is not symmetric
Part (b): Exam Scores (Normal Distribution)
Mean is most appropriate.
For symmetric, normally distributed data, mean = median
The mean uses all information in the data
The mean has nice mathematical properties for further analysis
No outliers to distort the result
Part (c): Household Income (Wealth Inequality)
Median is most appropriate.
Income distributions are typically right-skewed
A few very high incomes pull the mean up
The median better represents what a “typical” household earns
This is standard practice in economic reporting
Part (d): Server Response Times (Occasional Delays)
Median is most appropriate.
Response time distributions are typically right-skewed
Occasional long delays are outliers that inflate the mean
The median represents the typical user experience
Alternative: Report both median and 95th percentile
Part (e): Customer Satisfaction (1-5 Scale)
Mode is most appropriate.
Ordinal categorical data (1-5 scale)
The mode gives the most common response
Mean is technically questionable for ordinal data (though often reported)
“Most customers gave us a 4” is clearer than “average rating 3.7”
Part (f): Manufacturing Measurements (No Outliers)
Mean is most appropriate.
Data clusters tightly around target with no outliers
The mean incorporates all measurements
For quality control, the mean is used in control charts
Symmetric data means mean ≈ median anyway
Exercise 5: Working with Grouped Data
A software company has three development teams. The number of bugs fixed by each developer last month is recorded:
Team A (4 developers): 12, 15, 14, 13
Team B (6 developers): 8, 10, 9, 11, 7, 9
Team C (5 developers): 18, 22, 19, 20, 21
Calculate the mean number of bugs fixed for each team separately.
Calculate the overall mean for all 15 developers combined. (Hint: You must account for different team sizes.)
If you simply averaged the three team means from part (a), would you get the same answer as part (b)? Explain why or why not.
Which team shows the most variability in bugs fixed? (Just estimate from looking at the data—you’ll learn to calculate this precisely in the next section.)
Solution
Part (a): Team Means
Team A (\(n_1 = 4\)):
Team B (\(n_2 = 6\)):
Team C (\(n_3 = 5\)):
Part (b): Overall Mean
Total developers: \(N = n_1 + n_2 + n_3 = 4 + 6 + 5 = 15\)
Method 1 (sum all values):
Method 2 (weighted average of team means):
Part (c): Simple Average of Team Means
Simple average: \(\frac{13.5 + 9.0 + 20.0}{3} = \frac{42.5}{3} = 14.17\)
No, this is NOT the same as the overall mean (13.87).
The simple average treats each team equally, but the teams have different sizes. Team B (with the lowest mean of 9.0) has 6 developers, while Team A has only 4. The overall mean must weight each team by its size to properly represent all developers.
The simple average of means only equals the overall mean when all groups have the same size.
Part (d): Variability Estimate
Looking at the ranges:
Team A: 15 - 12 = 3 (range)
Team B: 11 - 7 = 4 (range)
Team C: 22 - 18 = 4 (range)
Teams B and C appear to have similar variability (range of 4), while Team A has slightly less variability (range of 3).
However, looking at the data:
Team A values cluster fairly tightly around 13.5
Team B values spread from 7 to 11 around mean of 9
Team C values spread from 18 to 22 around mean of 20
The variability appears roughly similar across teams, though Team A might be slightly more consistent.
Exercise 6: Conceptual Understanding
Answer the following conceptual questions about measures of central tendency.
A dataset has \(\bar{x} = \tilde{x} = M = 50\). What can you conclude about the shape of this distribution?
Can a dataset have more than one mode? Can it have more than one median? Explain.
A professor says: “The median exam score was 78, but after adding 5 points to everyone’s score, the median became 83.” Verify whether this statement makes sense mathematically.
If every value in a dataset is multiplied by 2, what happens to the mean? What happens to the median? What happens to the mode?
True or False: “The mean of a dataset must be equal to one of the values in the dataset.” Explain.
A dataset of 99 values has a median of 50. If a 100th value is added, and the new median is 52, what can you conclude about the value that was added?
Solution
Part (a): When All Three Measures Are Equal
When \(\bar{x} = \tilde{x} = M\), the distribution is likely:
Symmetric (or very close to symmetric)
Unimodal (single peak)
No significant outliers
This is characteristic of a symmetric, bell-shaped distribution like the normal distribution. However, you cannot conclude it’s perfectly normal—only that it’s reasonably symmetric with a single mode.
Part (b): Multiple Modes and Medians
Mode: Yes, a dataset can have multiple modes.
Bimodal: Two values tie for highest frequency
Multimodal: Three or more values tie
Example: {1, 1, 2, 3, 3} has modes M = 1 and M = 3
Median: Technically, when n is even, the median is defined as the average of the two middle values, so there is always exactly one median value. However, both middle values could be considered “median positions.”
In practice, we report a single median value
Example: {1, 2, 3, 4} has median = (2+3)/2 = 2.5
Part (c): Adding a Constant
Yes, this makes sense.
When you add a constant \(c\) to every value:
The median increases by exactly \(c\)
Original median: 78
After adding 5: 78 + 5 = 83 ✓
This is because the median depends only on position (order), and adding the same amount to all values shifts every value—including the middle one—by that amount.
Part (d): Multiplying by a Constant
If every value is multiplied by 2:
Mean: Multiplied by 2 → \(\bar{x}_{new} = 2\bar{x}_{old}\)
Median: Multiplied by 2 → \(\tilde{x}_{new} = 2\tilde{x}_{old}\)
Mode: Multiplied by 2 → \(M_{new} = 2M_{old}\)
All three measures scale proportionally because multiplication is a linear transformation that preserves the relative ordering and proportions of values.
Part (e): Mean Must Equal a Data Value?
False.
The mean often does not equal any value in the dataset.
Example: {1, 2, 3, 4} has mean \(\bar{x} = \frac{10}{4} = 2.5\), but 2.5 is not in the dataset.
The mean is a mathematical calculation that can fall anywhere within (or even outside, if negative values exist) the range of the data.
Part (f): Effect of Adding One Value on Median
Original: 99 values with median = \(x_{(50)} = 50\) (the 50th value when sorted)
After adding one value (n = 100, even):
New median = \(\frac{x_{(50)} + x_{(51)}}{2} = 52\)
For the median to increase from 50 to 52:
The average of the new 50th and 51st values must be 52
This means \(x_{(50)} + x_{(51)} = 104\)
The added value must be greater than 50 (the old median). Specifically:
If the new value is inserted and becomes the 51st value or higher, it pushes the median up
The new value is likely ≥ 54 (to make the new 51st value at least 54, giving average ≥ 52 with 50)
We can conclude the added value was significantly larger than the original median.
3.2.7. Additional Practice Problems
True/False Questions (1 point each)
The sample mean is always affected by every value in the dataset.
Ⓣ or Ⓕ
The sample median is the value that occurs most frequently in a dataset.
Ⓣ or Ⓕ
For a symmetric distribution, the mean and median are approximately equal.
Ⓣ or Ⓕ
A dataset can have no mode if all values occur with equal frequency.
Ⓣ or Ⓕ
If the mean is greater than the median, the distribution is likely left-skewed.
Ⓣ or Ⓕ
The median is calculated by finding \(\frac{1}{n}\sum_{i=1}^{n} x_i\).
Ⓣ or Ⓕ
Multiple Choice Questions (2 points each)
For the dataset {3, 5, 5, 7, 8, 9, 10}, what is the median?
Ⓐ 5
Ⓑ 6
Ⓒ 7
Ⓓ 6.71
A real estate website reports that the median home price in a city is $350,000 and the mean is $425,000. This suggests that:
Ⓐ Most homes cost exactly $350,000
Ⓑ The distribution of home prices is left-skewed
Ⓒ Some expensive homes are pulling the mean above the median
Ⓓ The mode is $425,000
Which measure of central tendency is MOST resistant to outliers?
Ⓐ Mean
Ⓑ Median
Ⓒ Mode
Ⓓ All are equally resistant
For the dataset {2, 2, 3, 3, 3, 4, 4, 100}, the mean is 15.125 and the median is 3. Which statement best explains this difference?
Ⓐ The calculation of the mean is incorrect
Ⓑ The dataset has two modes, which affects the mean
Ⓒ The outlier (100) pulls the mean much higher than the median
Ⓓ The median should be recalculated using the mean
Answers to Practice Problems
True/False Answers:
True — The mean formula \(\bar{x} = \frac{1}{n}\sum x_i\) includes every observation. Changing any single value changes the sum and therefore the mean.
False — This describes the mode, not the median. The median is the middle value when data is sorted.
True — In symmetric distributions, the mean and median coincide at the center. For perfectly symmetric distributions, they are exactly equal.
True — When all values have the same frequency, no single value is “most frequent,” so there is no mode. Some texts say the dataset is “amodal.”
False — When mean > median, the distribution is right-skewed (positively skewed). High values in the right tail pull the mean up.
False — This formula calculates the mean, not the median. The median is found by locating the middle value(s) of sorted data.
Multiple Choice Answers:
Ⓒ — The sorted data is {3, 5, 5, 7, 8, 9, 10} with n = 7 (odd). The median is the \(\frac{7+1}{2} = 4\)th value, which is 7.
Ⓒ — When mean ($425,000) > median ($350,000), the distribution is right-skewed. Some expensive homes are pulling the mean above the median. This is typical for real estate prices.
Ⓑ — The median is most resistant to outliers because it depends only on the position (rank) of values, not their magnitude. Extreme values don’t affect which value is in the middle.
Ⓒ — The outlier (100) pulls the mean much higher than the median. The mean includes all values, so the extreme 100 significantly inflates it. The median only looks at the middle values (3 and 3), so it’s unaffected by the outlier.