Slides 📊
12.4. Multiple Comparison Procedures
When ANOVA leads to rejection of the null hypothesis, we conclude that at least one population mean is different than the others. However, this global conclusion could mean that only one mean differs from the rest, that all means are completely different from each other, or any intermediate scenario.
To understand the specific structure of differences, we need to perform a multiple comparison procedure.
Road Map 🧭
Understand the impact of multiple simultaneous testing on the Family-Wise Error Rate (FWER).
Learn the Bonferroni correction and Tukey’s method as two major ways to control FWER. Recognize the advantages and limitations of each method.
Visually display multiple comparisons results using an underline graph.
Follow the correct sequence of steps to perform a complete ANOVA.
12.4.1. The Multiple Testing Problem
The Hypotheses
The multiple comparisons procedure is equivalent to performing a hypothesis test for each pair of groups \(i\) and \(j\) such that \(i,j \in \{1, \cdots,k\}\) and \(i < j\), using the dual hypothesis:
The Problem of Type I Error Inflation
When performing multiple simultaneous inferences, we are concerned not only with controlling the individual Type I error probability \(\alpha_{\text{single}}\), for each test, but also with managing the Family-Wise Error Rate (FWER), \(\alpha_{\text{overall}}\). The FWER is essentially the probability of making at least one individual Type I error.
Let us denote the number of comparisons to be made as \(c\). The naive approach of performing \(c\) different two-sample \(t\)-procedures with no further adjustments raises the serious issue of FWER inflation. To see how, suppose there are five groups requiring \(\binom{5}{2} = 10\) pairwise comparisons at \(\alpha_{\text{single}} = 0.05\) for each test. In a simplified setting where the test results are mutually independent, the FWER is:
The transition from the second to the third line above requires independence. The result means that we have about a 40% chance of making at least one false positive—far above our intended 5% level!
General Result
In general, the family-wise error rate of \(c\) independent tests is computed by:
Even with small \(c\), the FWER quickly grows to exceed the individual Type I error probability by a large margin. The issue is exacerbated by the fact that \(c\) grows quadratically with \(k\) as shown by the general formula:
Without any adjustments addressing this issue, this massive inflation of Type I error rate will undermine our statistical control and lead to false discoveries.
Important Caveat: The Independence Assumption
Note that our exploration of Type I error inflation was made under the assumption that the test results are independent. This is in fact quite unrealistic since pairwise comparisons use overlapping data and share the common MSE estimate. However, this provides a useful starting point for understanding the problem.
The adjustment methods introduced below will not require the independence assumption.
12.4.2. Methods for Controlling FWER
The Common Structure
Several statistical methods have been developed to control the family-wise error rate. We will examine two major approaches: the Bonferroni correction and Tukey’s HSD method, and briefly discuss two special cases—Šidák correction and Dunnett’s method—in the appendix.
For every method, a confidence interval equivalent to the test (12.1) is constructed as:
where the form of \(\mathbf{t^{**}}\) is specific to each method. All other components remain unchanged and draw a close parallel with the independent two-sample confidence interval under the equal variance assumption.
Method 1: The Bonferroni Correction
The Bonferroni correction bounds the individual type I error so that it yields a family-wise error rate below a desired level. The correction relies on Boole’s inequality (also called the union bound):
How does Boole’s Inequality Hold?
Let us examine a two-way case. Beginning with the general addition rule:
which agrees with Boole’s inequality with \(c=2\). Cases with \(c > 2\) can be inductively reasoned.
Applying the inequality to our context,
To ensure a target FWER of at most \(\alpha_{\text{overall}}\), therefore, we choose:
and use the \(t\)-critical value:
in the general confidence interval (12.2). Note that independence of test results is not required for this approach, since Boole’s inequality holds regardless of independence between events.
Example 💡: Bonferroni Multiple Comparisons for Coffeehouse Data
📊 Download the coffeehouse dataset (CSV)
Sample (Levels of Factor Variable) |
Sample Size |
Mean |
Variance |
|---|---|---|---|
Population 1 |
\(n_1 = 39\) |
\(\bar{x}_{1.} = 39.13\) |
\(s_1^2 = 62.43\) |
Population 2 |
\(n_2 = 38\) |
\(\bar{x}_{2.} = 46.66\) |
\(s_2^2 = 168.34\) |
Population 3 |
\(n_3 = 42\) |
\(\bar{x}_{3.} = 40.50\) |
\(s_3^2 = 119.62\) |
Population 4 |
\(n_4 = 38\) |
\(\bar{x}_{4.} = 26.42\) |
\(s_4^2 = 48.90\) |
Population 5 |
\(n_5 = 43\) |
\(\bar{x}_{5.} = 34.07\) |
\(s_5^2 = 98.50\) |
Combined |
\(n = 200\) |
\(\bar{x}_{..} = 37.35\) |
\(s^2 = 142.14\) |
Recall the coffeehouse dataset. In the ANOVA F-test, we rejected the null hypothesis that all true means are equal.
Suppose the Bonferroni correction is to be used for all confidence intervals of pairwise differences, with \(\alpha_{\text{overall}} = 0.05\). Compute the interval for the difference between Coffeehouse 2 and Coffeehouse 3.
Key components
\(\bar{x}_2 - \bar{x}_3 = 46.66 - 40.50 = 6.16\)
\(df_E = n-k = 200-5 = 195\)
\(MSE = 99.75\) from the ANOVA table (see Chapter 12.3)
For \(k=5\), the number of comparisons is \(\binom{5}{2}=10\). Then, \(\alpha_{\text{single}} = \frac{0.05}{10} = 0.005\).
Computing the critical value
Using R,
qt(0.0025, df=195, lower.tail=FALSE)
gives \(\mathbf{t^{**}} = t_{0.005/2, 195}=2.84\).
Substituting the appropriate values into Eq (12.2),
Conclusion
Since the interval includes 0, we do not have enough evidence to conclude that the true mean ages of Coffeehouses 2 and 3 are different at the family-wise error rate of \(\alpha_{\text{overall}}\) according to the Bonferroni correction.
Method 2: Tukey’s Honestly Significant Difference (HSD) Method
The theoretical foundation of Tukey’s method rests on the distribution of the statistic for the largest difference among all possible pairwise comparisons, \(\max_i \bar{X}_i - \min_i\bar{X}_i\). When the group sizes are balanced and commonly denoted as \(n\), the statistic
is called the studentized range statistic and follows the studentized range distribution, which is determined by two parameters, \(k\) and \(n-k\).
We use the distribution of \(Q\) to compute the critical value for all comparisons since if we can identify a wide enough interval for the largest difference, then we are safe with all other pairwise comparisons. The critical value used for Tukey’s HSD is:
where \(q_{\alpha,k,n-k}\) is the \((1-\alpha)\)-quantile of the studentized range distribution with \(k\) groups and \(n-k\) degrees of freedom.
Performing Tukey’s Method on R
With Summary Statistics
Calculate the critical value for alpha:
q_crit <- qtukey(alpha, nmeans = k, df = n-k, lower.tail = FALSE) / sqrt(2)
Then for each pair \((i,j)\),
diff <- x_bar_i - x_bar_j
se_diff <- sqrt(MSE * (1/n_i + 1/n_j))
margin_error <- q_crit * se_diff
# Confidence interval
ci_lower <- diff - margin_error
ci_upper <- diff + margin_error
Using Raw Data
# Fit ANOVA model
fit <- aov(response ~ factor, data = dataset)
# Perform Tukey's HSD
tukey_results <- TukeyHSD(fit, ordered = TRUE, conf.level = 0.95)
# View results
tukey_results
Example 💡: Tukey Multiple Comparisons for Coffeehouse Data
📊 Download the coffeehouse dataset (CSV)
Sample (Levels of Factor Variable) |
Sample Size |
Mean |
Variance |
|---|---|---|---|
Population 1 |
\(n_1 = 39\) |
\(\bar{x}_{1.} = 39.13\) |
\(s_1^2 = 62.43\) |
Population 2 |
\(n_2 = 38\) |
\(\bar{x}_{2.} = 46.66\) |
\(s_2^2 = 168.34\) |
Population 3 |
\(n_3 = 42\) |
\(\bar{x}_{3.} = 40.50\) |
\(s_3^2 = 119.62\) |
Population 4 |
\(n_4 = 38\) |
\(\bar{x}_{4.} = 26.42\) |
\(s_4^2 = 48.90\) |
Population 5 |
\(n_5 = 43\) |
\(\bar{x}_{5.} = 34.07\) |
\(s_5^2 = 98.50\) |
Combined |
\(n = 200\) |
\(\bar{x}_{..} = 37.35\) |
\(s^2 = 142.14\) |
Suppose now that Tukey’s HSD method is to be used for all confidence intervals of pairwise differences, with \(\alpha_{\text{overall}} = 0.05\). Compute the interval for the difference between Coffeehouse 2 and Coffeehouse 3.
Compare the result with the Bonferroni-corrected interval.
Key components
\(\bar{x}_2 - \bar{x}_3 = 46.66 - 40.50 = 6.16\)
\(df_E = n-k = 200-5 = 195\)
\(MSE = 99.75\) from the ANOVA table (see Chapter 12.3)
Computing the critical value
Using R,
qtukey(0.05, nmeans = 5, df = 195, lower.tail = FALSE) / sqrt(2)
gives \(\mathbf{t^{**}} = 2.75\).
Substituting the appropriate values into Eq (12.2),
Conclusion
Since the interval does not include 0, we have enough evidence to conclude that the true mean ages of Coffeehouses 2 and 3 are different at the family-wise error rate of \(\alpha_{\text{overall}}\) according to Tukey’s HSD method.
Why does it give a different conclusion than Bonferroni?
The Bonferroni correction tends to make the inference results overly conservative as \(c\) grows by choosing \(\alpha_{\text{single}}\) that falls well below the true requirement. When the number of comparisons is greater than a few, therefore, Tukey’s HSD has higher power and is generally a better choice than Bonferroni.
Bonferroni or Tukey’s HSD?
Advantage |
Disadvantage |
|
Bonferroni |
|
|
Tukey’s HSD |
|
|
12.4.3. Interpreting Multiple Comparisons Results
Reading the R output
A confidence interval that does not contain 0 indicates a statistically significant difference at the family-wise error rate \(\alpha_{\text{overall}}\).
A typical R output for a multiple comparisons procedure consists of:
diff: The evaluated difference \(\bar{x}_{i\cdot} - \bar{x}_{j\cdot}\)lwr: Lower bound of confidence intervalupr: Upper bound of confidence intervalp adj: Adjusted \(p\)-value accounting for multiple comparisons
The adjusted \(p\)-values can be compared directly to \(\alpha_{\text{overall}}\) to determine significance, or you can examine whether 0 falls within each confidence interval.
Visually Displaying the Results
After obtaining multiple comparison results, creating an effective visual summary helps communicate the pattern of group differences clearly and intuitively. The standard approach uses an “underline” notation to show which groups cannot be distinguished statistically. To construct underline diagrams, follow the steps below:
Arrange the groups from smallest to largest sample mean.
Identify all pairs that are NOT significantly different.
Draw lines under groups that are not significantly different.
Interpret the grouping pattern. Groups connected by the same underline are statistically indistinguishable from each other.
Example 💡: Underline Diagrams
Consider four groups A, B, C, D whose observed sample means are ordered as \(\bar{x}_A < \bar{x}_B < \bar{x}_C < \bar{x}_D.\) For each case of multiple comparisons results, draw and interpret the underline diagram.
Example 1: Simple Grouping
A vs B: not significant
B vs C: significant
C vs D: not significant
A vs C: significant
A vs D: significant
B vs D: significant
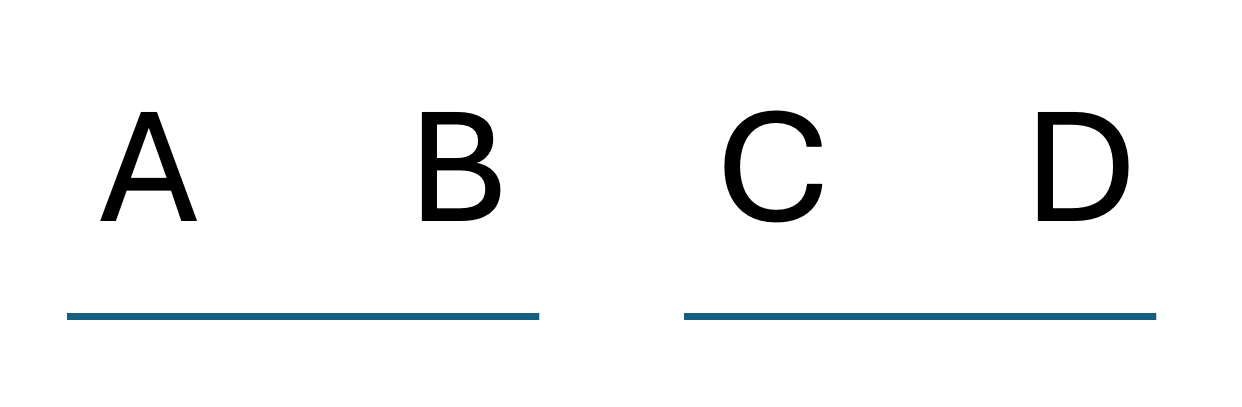
Groups A and B form one cluster and groups C and D form another cluster. The two clusters are significantly different from each other.
Example 2: Complex Overlapping Pattern
A vs B: not significant
B vs C: not significant
C vs D: not significant
A vs C: not significant
A vs D: significant
B vs D: significant

Groups A, B, and C are all statistically indistinguishable from each other. Groups C and D are not statistically different, either. However, Group D is significantly different from groups A and B.
Example 3: Ambiguous Transitivity
A vs B: not significant
B vs C: significant
C vs D: not significant
A vs C: significant
A vs D: not significant
B vs D: significant
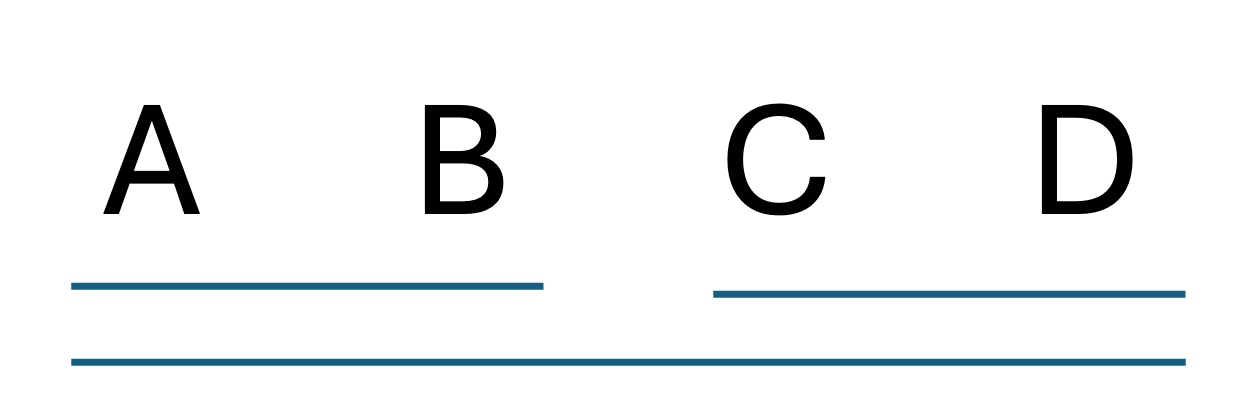
Sometimes the results create apparent contradictions that require careful interpretation, mainly due to heavy imbalance in group sizes.
Groups A and B are similar; groups C and D are similar. However, the data also suggests that A is more similar to D than to C. This illustrates the limitations of interpreting statistical significance as a perfect ordering—the underlying population means may have a different relationship than what our sample evidence suggests.
12.4.4. The Complete ANOVA Workflow
An ANOVA procedure requires a series of steps to be performed in the correct order. The list below summarizes the complete ANOVA workflow:
Perform exploratory data analysis. Use side-by-side boxplots.
Graphically and numerically check assumptions of independence, normality, and equal variances.
Construct the ANOVA table. Perform the ANOVA \(F\)-test for any group differences.
If the result of Step 3 is statistically significant, proceed to multiple comparisons.
Apply the appropriate multiple comparisons method.
Create an underline diagram and interpret the results.
Example 💡: Complete Tukey’s HSD Multiple Comparisons ☕️
Let us continue with the coffeehouse example. Disregarding the Bonferroni example, suppose the multiple comparison procedure is to be performed using Tukey’s HSD. This is in fact more appropriate since with \(c=10\), the Bonferroni adjusted \(\alpha_{\text{single}}\) is too small.
Use \(\alpha_{\text{overall}} = 0.05\).
Manual Computation
The critical value calculation:
# Manual critical value calculation
q_crit <- qtukey(0.05, nmeans = 5, df = 195, lower.tail = FALSE) / sqrt(2)
# q_crit ≈ 2.75
Then for all possible pairs \((i,j)\), compute the interval using Equation (12.2).
Using the Raw Data
Assuming that we have the fitted ANOVA model saved to fit, we can also run:
tukey_results <- TukeyHSD(fit, ordered = TRUE, conf.level = 0.95)
Results
Pair |
Difference |
95% CI Lower |
95% CI Upper |
Significant? |
|---|---|---|---|---|
5-4 |
7.65 |
1.50 |
13.80 |
✔ |
1-4 |
12.71 |
6.56 |
18.86 |
✔ |
3-4 |
14.08 |
8.00 |
20.16 |
✔ |
2-4 |
20.24 |
14.01 |
26.47 |
✔ |
3-5 |
6.43 |
0.35 |
12.51 |
✔ |
2-5 |
12.59 |
6.36 |
18.82 |
✔ |
2-1 |
7.53 |
1.30 |
13.76 |
✔ |
2-3 |
6.16 |
0.0031 |
12.32 |
✔ |
1-5 |
5.06 |
-1.09 |
11.21 |
❌ |
3-1 |
1.37 |
-4.71 |
7.45 |
❌ |
The Underline Graph
First, order the groups in the ascending order of the sample means. Since pairs 1-5 and 3-1 have non-significant relationships, the appropriate underline graph is:
CH4 CH5 ——— CH1 ——— CH3 CH2
Coffeehouse 4 has the youngest customer base, significantly different from all other coffeehouses.
Coffeehouse 2 has the oldest customer base, significantly different from all other coffeehouses.
Coffeehouses 5, 1, and 3 form an intermediate cluster where customers cannot be distinguished by age statistically.
12.4.5. Bringing It All Together
Key Takeaways 📝
After the ANOVA \(F\)-test yields a significant result, multiple comparisons are essential to identify which specific groups differ.
Family-wise error rate (FWER) must be controlled in multiple comparisons contexts.
Bonferroni correction controls FWER by adjusting individual test significance levels, but it tends to be overly conservative, especially with many comparisons.
Tukey’s HSD method provides superior power while maintaining exact FWER control by using the studentized range distribution.
Visual displays using underlines effectively communicate complex patterns of group similarities and differences, though they should be interpreted carefully regarding transitivity.
The complete ANOVA workflow integrates exploratory analysis, assumption checking, overall F-testing, and targeted multiple comparisons to provide comprehensive understanding of group differences.
12.4.6. Exercises
Exercise 1: The Multiple Testing Problem
A researcher compares mean reaction times across \(k = 8\) different interface designs.
How many pairwise comparisons are needed to compare all pairs of designs?
If each comparison is conducted as a separate test at \(\alpha_{\text{single}} = 0.05\), what is the family-wise error rate (FWER), assuming independent tests?
What does this FWER value mean in practical terms?
Why is controlling the FWER important in scientific research?
Solution
Part (a): Number of pairwise comparisons
Part (b): Family-wise error rate
Assuming independence:
Part (c): Practical meaning
Even if all 8 interface designs have identical true mean reaction times (\(H_0\) true for all comparisons), there is a 76.22% probability of incorrectly declaring at least one pair significantly different.
This is more than a 3 in 4 chance of making a false discovery!
Part (d): Why FWER control matters
Scientific integrity: High FWER leads to false discoveries that don’t replicate
Resource waste: Follow-up studies based on false positives waste time and money
Misleading conclusions: Researchers may make incorrect recommendations about which designs are better
Publication bias: False positives are more likely to be published, distorting the literature
Practical decisions: Companies might choose an interface that isn’t actually superior
R verification:
k <- 8
num_comp <- choose(k, 2) # 28
alpha_overall <- 1 - (1 - 0.05)^num_comp # 0.7622
Exercise 2: FWER as a Function of Comparisons
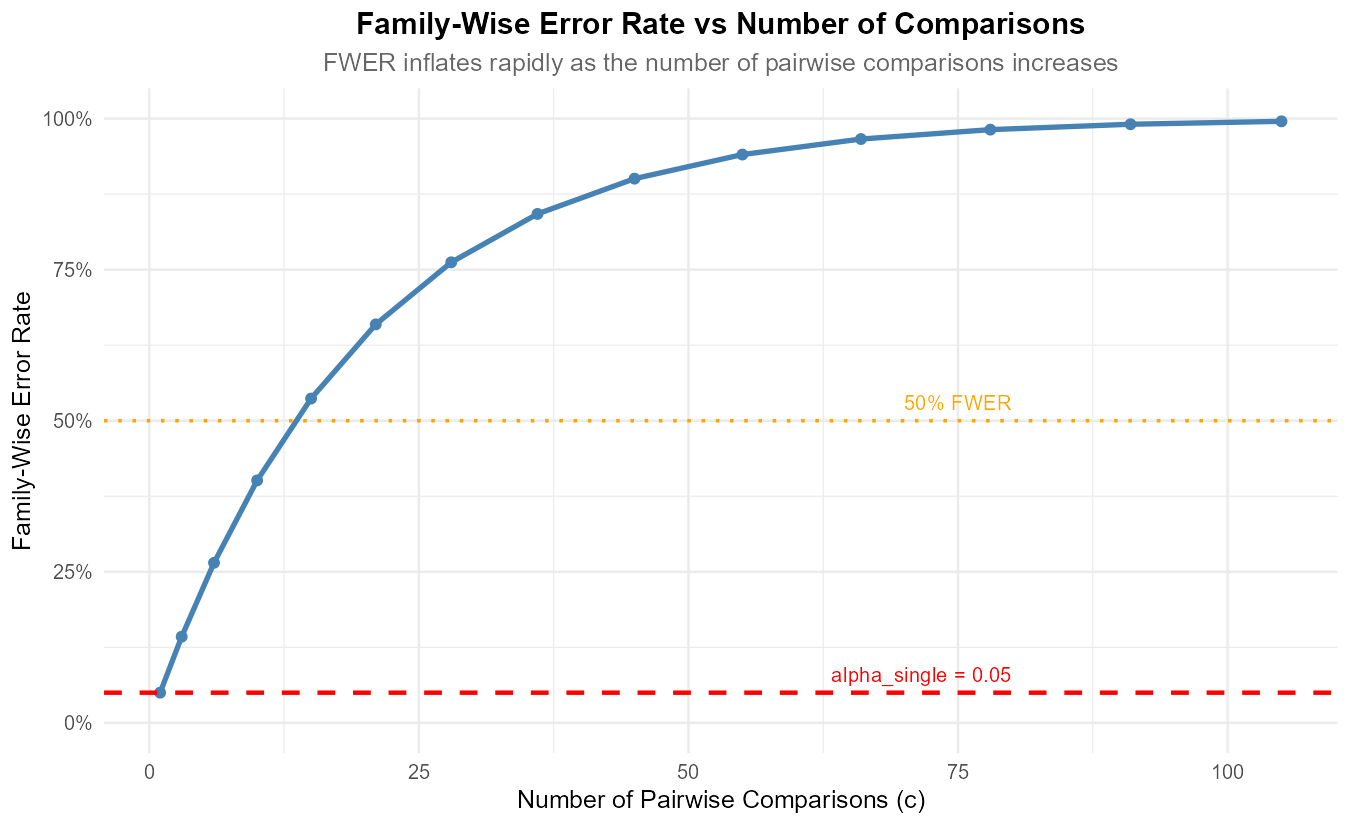
Fig. 12.20 Figure 1: Family-wise error rate as a function of number of comparisons (\(\alpha_{\text{single}} = 0.05\)).
Using Figure 1 or calculations:
Complete the following table showing FWER for different numbers of groups:
k (groups)
c (comparisons)
FWER (\(\alpha = 0.05\))
3
5
10
15
At what number of groups does the FWER first exceed 50%?
A clinical trial compares 6 treatments. If the researchers use individual \(\alpha = 0.05\) tests without correction, approximately what FWER do they face?
Solution
Part (a): Completed table
k (groups) |
c (comparisons) |
FWER (\(\alpha = 0.05\)) |
|---|---|---|
3 |
3 |
14.26% |
5 |
10 |
40.13% |
10 |
45 |
90.06% |
15 |
105 |
99.54% |
Calculations:
\(k=3\): \(c = 3\), FWER \(= 1 - 0.95^{3} = 0.1426\)
\(k=5\): \(c = 10\), FWER \(= 1 - 0.95^{10} = 0.4013\)
\(k=10\): \(c = 45\), FWER \(= 1 - 0.95^{45} = 0.9006\)
\(k=15\): \(c = 105\), FWER \(= 1 - 0.95^{105} = 0.9954\)
Part (b): FWER exceeds 50%
Solving \(1 - 0.95^c \geq 0.5\):
\(0.95^c \leq 0.5 \implies c \geq \log(0.5)/\log(0.95) = 13.5134\)
So we need \(c \geq 14\) comparisons, which first occurs at k = 6 groups (\(c = 15\)).
Part (c): Clinical trial with 6 treatments
\(c = \binom{6}{2} = 15\) comparisons
FWER \(= 1 - 0.95^{15} = 1 - 0.4633 =\) 0.5367 = 53.67%
More than half the time, they would falsely declare at least one treatment different when no differences exist!
R verification:
# Part (a)
k_values <- c(3, 5, 10, 15)
for (k in k_values) {
num_comp <- choose(k, 2)
fwer <- 1 - (0.95)^num_comp
cat("k =", k, ": c =", num_comp, ", FWER =", round(fwer, 4), "\n")
}
# Part (b)
log(0.5) / log(0.95) # 13.5134
choose(6, 2) # 15 comparisons at k=6
# Part (c)
1 - 0.95^15 # 0.5367
Exercise 3: Bonferroni Correction
A materials scientist compares the hardness of 4 different alloy compositions. After rejecting \(H_0\) in the overall ANOVA F-test, she wants to identify which specific pairs differ.
Given: \(n = 60\) total (15 per group), \(MSE = 18.5\), and the group means are:
Alloy A: \(\bar{x}_1 = 245.2\)
Alloy B: \(\bar{x}_2 = 252.8\)
Alloy C: \(\bar{x}_3 = 248.5\)
Alloy D: \(\bar{x}_4 = 261.3\)
Using the Bonferroni correction with overall \(\alpha = 0.05\):
How many pairwise comparisons are there?
What is the adjusted significance level \(\alpha_{\text{single}}\) for each comparison?
Calculate the Bonferroni-adjusted critical t-value.
Calculate the confidence interval for \(\mu_D - \mu_A\).
Is the difference between Alloy D and Alloy A statistically significant?
Solution
Part (a): Number of comparisons
Part (b): Adjusted significance level
Part (c): Bonferroni critical value
For the CI, we need \(t_{\alpha_{\text{single}}/2,\; n-k}\):
(Using R: qt(0.008333/2, 56, lower.tail = FALSE))
Part (d): CI for \(\mu_D - \mu_A\)
Point estimate: \(\bar{x}_D - \bar{x}_A = 261.3 - 245.2 = 16.1\)
Standard error (equal n per group):
Margin of error:
95% family-wise CI:
Part (e): Statistical significance
Since the interval (11.8042, 20.3958) does not contain 0, the difference between Alloy D and Alloy A is statistically significant at the 0.05 family-wise level.
Alternatively: We can conclude \(\mu_D > \mu_A\) because the entire interval is positive.
R verification:
k <- 4; n <- 60; n_per_group <- 15
MSE <- 18.5
xbar <- c(245.2, 252.8, 248.5, 261.3)
num_comp <- choose(k, 2) # 6
alpha_single <- 0.05 / num_comp # 0.008333
df_E <- n - k # 56
t_bonf <- qt(alpha_single/2, df_E, lower.tail = FALSE) # 2.7352
# CI for D - A
point_est <- xbar[4] - xbar[1] # 16.1
SE <- sqrt(MSE * (1/15 + 1/15)) # 1.5706
ME <- t_bonf * SE # 4.2958
c(point_est - ME, point_est + ME) # (11.8042, 20.3958)
Exercise 4: Tukey’s HSD Method
Using the same alloy data from Exercise 3, now apply Tukey’s HSD method.
Calculate the Tukey critical value \(q^*\) using R’s
qtukey()function.Calculate the Tukey-adjusted margin of error for comparing any two groups.
Calculate the Tukey HSD confidence interval for \(\mu_D - \mu_A\).
Compare the Tukey CI width to the Bonferroni CI width from Exercise 3. Which is narrower?
Why is Tukey’s method generally preferred over Bonferroni for pairwise comparisons?
Solution
Part (a): Tukey critical value
The studentized range critical value:
q_raw <- qtukey(0.05, nmeans = 4, df = 56, lower.tail = FALSE)
# q_raw = 3.7447
q_star <- q_raw / sqrt(2) # Convert to t-scale
# q_star = 2.6479
Part (b): Tukey margin of error
For equal sample sizes:
Using the Tukey formula (alternative form):
Part (c): Tukey CI for \(\mu_D - \mu_A\)
Part (d): Comparison of CI widths
Bonferroni CI: (11.8042, 20.3958), width = 8.5917
Tukey CI: (11.9413, 20.2587), width = 8.3173
Tukey’s CI is narrower by about 0.2744 units (approximately 3.19% narrower).
Part (e): Why Tukey is preferred
More powerful: Tukey’s method uses the studentized range distribution, which is specifically designed for comparing all pairs of means. This gives narrower CIs and more power to detect differences.
Exact FWER control: Tukey provides exact control of the family-wise error rate, while Bonferroni is conservative (actual FWER < nominal FWER).
Specifically designed for pairwise comparisons: Bonferroni is a general-purpose correction that works for any set of tests; Tukey is optimized for the specific case of all pairwise comparisons in ANOVA.
Efficiency increases with k: The advantage of Tukey over Bonferroni grows as the number of groups increases.
R verification:
# Full Tukey analysis
k <- 4; n <- 60; n_per <- 15
MSE <- 18.5
xbar <- c(245.2, 252.8, 248.5, 261.3)
names(xbar) <- c("A", "B", "C", "D")
df_E <- n - k
# Tukey critical value
q_raw <- qtukey(0.05, nmeans = k, df = df_E, lower.tail = FALSE)
q_star <- q_raw / sqrt(2) # 2.6479
# SE for equal n
SE <- sqrt(MSE * (1/n_per + 1/n_per)) # 1.5706
# Tukey ME
ME_tukey <- q_star * SE # 4.1587
# CI for D - A
point_est <- xbar["D"] - xbar["A"] # 16.1
c(point_est - ME_tukey, point_est + ME_tukey) # (11.9413, 20.2587)
# Width comparison (Bonferroni ME from Exercise 3)
t_bonf <- qt(0.05 / (2 * choose(k, 2)), df_E, lower.tail = FALSE)
bonf_width <- 2 * t_bonf * SE # 8.5917
tukey_width <- 2 * ME_tukey # 8.3173
Exercise 5: Interpreting Tukey HSD Output
A nutritionist compares weight loss (kg) across five diet programs. After a significant ANOVA result, she runs TukeyHSD() in R and obtains:
Tukey multiple comparisons of means
95% family-wise confidence level
$Diet
diff lwr upr p adj
B-A 4.20 0.82 7.58 0.0084
C-A -1.50 -4.88 1.88 0.7123
D-A 6.80 3.42 10.18 0.0000
E-A 3.10 -0.28 6.48 0.0873
C-B -5.70 -9.08 -2.32 0.0002
D-B 2.60 -0.78 5.98 0.2017
E-B -1.10 -4.48 2.28 0.8849
D-C 8.30 4.92 11.68 0.0000
E-C 4.60 1.22 7.98 0.0030
E-D -3.70 -7.08 -0.32 0.0253
Which pairs of diets show statistically significant differences at the 0.05 family-wise level?
Order the diets from lowest to highest mean weight loss.
Create an underline diagram showing which diets are not significantly different.
What practical conclusions can the nutritionist draw?
Solution
Part (a): Significant pairs (p adj < 0.05)
The following pairs are significantly different:
B-A: diff = 4.20, p = 0.0084 ✓
D-A: diff = 6.80, p < 0.0001 ✓
C-B: diff = -5.70, p = 0.0002 ✓
D-C: diff = 8.30, p < 0.0001 ✓
E-C: diff = 4.60, p = 0.0030 ✓
E-D: diff = -3.70, p = 0.0253 ✓
Non-significant pairs (p adj ≥ 0.05):
C-A: p = 0.7123
E-A: p = 0.0873
D-B: p = 0.2017
E-B: p = 0.8849
Part (b): Order diets by mean weight loss
Using Diet A as reference (x̄_A = baseline):
D-A = +6.80 → D is 6.80 above A
B-A = +4.20 → B is 4.20 above A
E-A = +3.10 → E is 3.10 above A
C-A = -1.50 → C is 1.50 below A
Order from lowest to highest mean weight loss:
C < A < E < B < D
Part (c): Underline diagram
Non-significant pairs form groups that can be underlined together:
C ——— A ——— E ——— B D
└─────────┘
Reading the diagram:
C and A are not significantly different
A and E are not significantly different
E and B are not significantly different
D stands alone (significantly different from all others)
Note: C-E and A-B ARE significantly different even though C-A, A-E, and E-B are not. This is the transitivity issue.
Part (d): Practical conclusions
Diet D is clearly the most effective, producing significantly more weight loss than all other diets.
Diet C is the least effective, with significantly less weight loss than B, D, and E.
Diets A, E, and B form an intermediate cluster where adjacent diets don’t differ significantly, but the extremes (A vs B via E) may differ.
Recommendation: If maximizing weight loss is the goal, Diet D is clearly superior. The choice among A, B, E may depend on other factors (cost, adherence, side effects).
Exercise 6: Constructing Underline Diagrams
An industrial engineer compares the productivity (units/hour) of workers trained with four different methods. The Tukey HSD results show:
Comparison |
Difference |
95% CI |
Significant? |
|---|---|---|---|
B - A |
2.3 |
(-0.8, 5.4) |
No |
C - A |
8.5 |
(5.4, 11.6) |
Yes |
D - A |
5.1 |
(2.0, 8.2) |
Yes |
C - B |
6.2 |
(3.1, 9.3) |
Yes |
D - B |
2.8 |
(-0.3, 5.9) |
No |
D - C |
-3.4 |
(-6.5, -0.3) |
Yes |
Order the training methods from lowest to highest mean productivity.
Construct the underline diagram.
Describe the groupings in words.
Which method(s) would you recommend and why?
Solution
Part (a): Order by mean productivity
From the differences (using A as reference):
B - A = +2.3 → B is 2.3 above A
C - A = +8.5 → C is 8.5 above A
D - A = +5.1 → D is 5.1 above A
Order: A < B < D < C
Verification: D - C = -3.4 (D is 3.4 below C) ✓
Part (b): Underline diagram
Non-significant pairs:
A and B (CI contains 0)
B and D (CI contains 0)
Significant pairs: A-C, A-D, B-C, C-D
A ——— B ——— D C
└─────────┘
Part (c): Groupings description
Group 1 (A, B): Methods A and B have statistically indistinguishable productivity levels. These are the lower-performing methods.
Group 2 (B, D): Methods B and D overlap. B bridges the low and middle groups.
Method C stands alone: Method C produces significantly higher productivity than all other methods.
Note: Although A-B and B-D are not significant, A-D IS significant (the “chain” doesn’t imply transitivity).
Part (d): Recommendation
Recommend Method C for training workers.
Rationale:
Method C produces significantly higher productivity than all other methods
The advantage over the next best (D) is 3.4 units/hour, which is statistically significant
Even compared to A, the improvement is 8.5 units/hour
If Method C is more expensive or difficult to implement, Method D might be a reasonable compromise—it’s significantly better than A and not significantly different from B, but significantly worse than C.
Exercise 7: Bonferroni vs Tukey Comparison
A researcher compares \(k = 6\) treatment groups with \(n = 12\) observations per group (total \(n = 72\)). \(MSE = 45.0\).
Calculate the Bonferroni critical value for 95% family-wise CIs.
Calculate the Tukey critical value for 95% family-wise CIs.
For two groups with means differing by 8.5, calculate both the Bonferroni and Tukey CIs.
Which method would you recommend for this analysis? Why?
Solution
Part (a): Bonferroni critical value
Number of comparisons: \(c = \binom{6}{2} = 15\)
\(\alpha_{\text{single}} = 0.05/15 = 0.003333\)
\(df_E = 72 - 6 = 66\)
(Using R: qt(0.003333/2, 66, lower.tail = FALSE))
Part (b): Tukey critical value
Part (c): Compare CIs for difference of 8.5
Standard error:
Bonferroni CI:
Width = 16.6825
Tukey CI:
Width = 16.0762
Part (d): Recommendation
Recommend Tukey’s method for this analysis.
Reasons:
Narrower intervals: Tukey CI is about 3.63% narrower (16.0762 vs 16.6825), giving more precision
More power: The narrower intervals mean more ability to detect true differences
All pairwise comparisons: When comparing all pairs (as in this case), Tukey is specifically designed and optimal
Exact FWER control: Tukey provides exact 95% family-wise coverage, while Bonferroni is conservative
Growing advantage: With \(k = 6\) groups (15 comparisons), the Tukey advantage is noticeable and would grow with more groups
Bonferroni is useful when: - Making only a few selected comparisons (not all pairs) - The comparison types are heterogeneous (not just pairwise)
R verification:
k <- 6; n <- 72; n_per <- 12
MSE <- 45
df_E <- n - k # 66
num_comp <- choose(k, 2) # 15
# Bonferroni
alpha_bonf <- 0.05 / num_comp
t_bonf <- qt(alpha_bonf/2, df_E, lower.tail = FALSE) # 3.0459
# Tukey
q_tukey <- qtukey(0.05, k, df_E, lower.tail = FALSE) / sqrt(2) # 2.9351
# CIs
SE <- sqrt(MSE * (1/n_per + 1/n_per)) # 2.7386
diff <- 8.5
CI_bonf <- c(diff - t_bonf * SE, diff + t_bonf * SE)
CI_tukey <- c(diff - q_tukey * SE, diff + q_tukey * SE)
diff(CI_bonf) # Width = 16.6825
diff(CI_tukey) # Width = 16.0762
Exercise 8: Complete Post-Hoc Analysis
A computer science researcher compares the accuracy (% correct) of 4 machine learning algorithms on a benchmark dataset. Each algorithm is tested on 20 independent runs.
ANOVA Results:
\(F = 8.72\), p-value = 0.00006 (significant at \(\alpha = 0.05\))
\(MSE = 15.8\), \(df_E = 76\)
Group Means:
Algorithm A (Random Forest): \(\bar{x}_1 = 87.3\%\)
Algorithm B (SVM): \(\bar{x}_2 = 84.1\%\)
Algorithm C (Neural Network): \(\bar{x}_3 = 91.5\%\)
Algorithm D (Gradient Boosting): \(\bar{x}_4 = 89.8\%\)
Conduct a complete Tukey HSD analysis:
Calculate the Tukey critical value.
Calculate 95% family-wise CIs for all 6 pairwise differences.
Identify which pairs are significantly different.
Create the underline diagram.
Write a summary of findings for a non-technical audience.
Solution
Assumption Note: Since the ANOVA was already conducted and found significant (p = 0.00006), we assume the standard ANOVA assumptions (independence, normality within groups, equal variances) were verified prior to the analysis. With n = 20 per group and equal sample sizes, ANOVA and Tukey HSD are robust to moderate assumption violations.
Part (a): Tukey critical value
\(k = 4\), \(df_E = 76\), \(\alpha = 0.05\)
Part (b): All pairwise CIs
Standard error (equal \(n = 20\)):
Margin of error:
All pairwise comparisons:
Pair |
Difference |
95% CI |
Significant? |
|---|---|---|---|
B - A |
-3.2 |
(-6.5018, 0.1018) |
No |
C - A |
4.2 |
(0.8982, 7.5018) |
Yes |
D - A |
2.5 |
(-0.8018, 5.8018) |
No |
C - B |
7.4 |
(4.0982, 10.7018) |
Yes |
D - B |
5.7 |
(2.3982, 9.0018) |
Yes |
D - C |
-1.7 |
(-5.0018, 1.6018) |
No |
Part (c): Significant pairs
Significantly different pairs (CI excludes 0):
C - A: Neural Network > Random Forest (by 4.2%)
C - B: Neural Network > SVM (by 7.4%)
D - B: Gradient Boosting > SVM (by 5.7%)
Part (d): Underline diagram
Order by mean: B (84.1) < A (87.3) < D (89.8) < C (91.5)
Non-significant pairs: B-A, A-D, D-C
B ——— A ——— D ——— C
└─────────┘ └─────┘
The two underlines show overlapping groups with no significant difference within each group.
Part (e): Non-technical summary
Summary: Machine Learning Algorithm Comparison
We compared four machine learning algorithms for classification accuracy. Here’s what we found:
Key Finding: The Neural Network algorithm achieved the highest average accuracy (91.5%), which was significantly better than both Random Forest (87.3%) and SVM (84.1%).
Performance Groups:
Top performers: Neural Network (91.5%) and Gradient Boosting (89.8%) - these were not significantly different from each other
Middle performer: Random Forest (87.3%) - overlaps with both top and bottom groups
Lower performer: SVM (84.1%) - significantly worse than Neural Network and Gradient Boosting
Recommendation: For this benchmark task, choose either Neural Network or Gradient Boosting. The Neural Network has a slight edge (1.7% higher) but the difference is not statistically significant. SVM appears to be the weakest choice among these options.
R verification:
k <- 4; n_per <- 20
MSE <- 15.8
df_E <- 76
xbar <- c(87.3, 84.1, 91.5, 89.8)
names(xbar) <- c("A", "B", "C", "D")
# Tukey critical value
q_star <- qtukey(0.05, k, df_E, lower.tail = FALSE) / sqrt(2) # 2.6268
SE <- sqrt(MSE * (1/n_per + 1/n_per)) # 1.2570
ME <- q_star * SE # 3.3018
# All pairwise comparisons
pairs <- combn(names(xbar), 2)
for (i in 1:ncol(pairs)) {
p1 <- pairs[1, i]; p2 <- pairs[2, i]
diff <- xbar[p2] - xbar[p1]
ci <- c(diff - ME, diff + ME)
sig <- ifelse(ci[1] > 0 | ci[2] < 0, "Yes", "No")
cat(p2, "-", p1, ":", round(diff, 1),
" CI: (", round(ci[1], 4), ",", round(ci[2], 4), ")",
" Sig:", sig, "\n")
}
Exercise 9: When NOT to Perform Multiple Comparisons
For each scenario, explain whether multiple comparison procedures should be performed and why.
ANOVA yields F = 1.23, p-value = 0.31
ANOVA yields F = 4.56, p-value = 0.006, but the researcher is only interested in comparing treatments to a control group.
ANOVA yields F = 8.91, p-value < 0.001, comparing 12 different drug formulations.
A study compares only k = 2 groups and finds a significant difference.
Solution
Part (a): F = 1.23, p = 0.31
Do NOT perform multiple comparisons.
We failed to reject H₀ in the overall F-test. This means we don’t have sufficient evidence that any population means differ. Conducting pairwise comparisons after a non-significant F-test:
Inflates the overall Type I error rate
Is considered “fishing” for significant results
Any significant findings would be unreliable
Part (b): F = 4.56, p = 0.006, interest only in control comparisons
Multiple comparisons are appropriate, but use Dunnett’s method instead of Tukey.
Since the researcher is only interested in comparing each treatment to the control (not all pairwise comparisons), Dunnett’s method is more appropriate:
Fewer comparisons: k-1 instead of k(k-1)/2
More power for the specific comparisons of interest
Still controls FWER appropriately
If Dunnett’s method is not available, Bonferroni with c = k-1 comparisons is an alternative.
Part (c): F = 8.91, p < 0.001, k = 12 formulations
Multiple comparisons are appropriate and necessary.
With a highly significant F-test, we know at least one mean differs. With k = 12 groups (66 pairwise comparisons), post-hoc analysis is essential to understand which formulations differ.
Recommendation: Use Tukey’s HSD. Given the large number of comparisons, Tukey will be substantially more powerful than Bonferroni.
Caution: With 66 comparisons, even significant findings should be interpreted carefully. Consider also reporting effect sizes and practical significance.
Part (d): k = 2 groups, significant difference
Multiple comparisons are NOT needed.
With only k = 2 groups, there’s only one pairwise comparison—which is exactly what the ANOVA (or equivalent t-test) already tested. There’s nothing more to compare.
The significant F-test already tells us that the two groups differ. Tukey HSD would just reproduce the same conclusion.
12.4.7. Additional Practice Problems
True/False Questions (1 point each)
Multiple comparison procedures should be performed regardless of whether the ANOVA F-test is significant.
Ⓣ or Ⓕ
The Bonferroni correction divides the overall significance level by the number of comparisons.
Ⓣ or Ⓕ
Tukey’s HSD method requires the assumption that all pairwise comparisons are independent.
Ⓣ or Ⓕ
If a Tukey 95% CI for μ_A - μ_B is (-2.5, 4.1), we conclude that A and B are significantly different.
Ⓣ or Ⓕ
The FWER increases as the number of groups increases.
Ⓣ or Ⓕ
Bonferroni correction is more conservative than Tukey’s method for pairwise comparisons.
Ⓣ or Ⓕ
Multiple Choice Questions (2 points each)
For k = 5 groups, how many pairwise comparisons are there?
Ⓐ 5
Ⓑ 10
Ⓒ 20
Ⓓ 25
Using Bonferroni with α_overall = 0.05 and 10 comparisons, the per-comparison α is:
Ⓐ 0.005
Ⓑ 0.01
Ⓒ 0.05
Ⓓ 0.50
An underline diagram shows:
A ——— B C ——— D. This indicates:Ⓐ All four means are significantly different
Ⓑ A differs from C and D; B differs from C and D
Ⓒ Only A-B and C-D pairs are NOT significantly different
Ⓓ The ANOVA F-test was not significant
Which method is specifically designed for comparing treatments to a control?
Ⓐ Bonferroni
Ⓑ Tukey HSD
Ⓒ Dunnett
Ⓓ Šidák
If 20 independent tests are conducted at α = 0.05 each, the FWER is approximately:
Ⓐ 0.05
Ⓑ 0.36
Ⓒ 0.64
Ⓓ 1.00
The Tukey critical value is obtained from which distribution?
Ⓐ t-distribution
Ⓑ F-distribution
Ⓒ Studentized range distribution
Ⓓ Chi-square distribution
Answers to Practice Problems
True/False Answers:
False — Multiple comparisons should only be performed after a significant F-test.
True — α_single = α_overall/c is the Bonferroni correction.
False — Tukey’s method does NOT require independence; it accounts for the correlation structure of pairwise comparisons.
False — The CI contains 0, so A and B are NOT significantly different.
True — More groups means more comparisons, leading to higher FWER if no correction is applied.
True — Bonferroni generally produces wider CIs (more conservative) than Tukey for all pairwise comparisons.
Multiple Choice Answers:
Ⓑ — C(5,2) = 10 pairwise comparisons
Ⓐ — α_single = 0.05/10 = 0.005
Ⓒ — Underlines connect non-significantly different means; A-B and C-D pairs are not significant.
Ⓒ — Dunnett’s method is designed specifically for treatment-vs-control comparisons.
Ⓒ — FWER = 1 - 0.95²⁰ = 0.64
Ⓒ — Tukey uses the studentized range distribution (q-distribution).