13.3. Model Diagnostics and Statistical Inference
Having developed several point estimates related to simple linear regression, we now face the critical stage of uncertainty quantification using confidence regions and hypothesis tests. Before conducting any statistical inference, however, we must first verify that our model assumptions are reasonable.
Road Map 🧭
Understand why all assumption-checking procedures involve the residuals.
List the appropriate graphical tools to assess each linear regression assumption, and systematically search for signs of assumption violation in each plot.
Perform inference on the overall model utility and on the model parameters.
Slides 📊
13.3.1. Preliminaries for Model Diagnostics
Review of Simple Linear Regression Assumptions
The simple linear regression model
requires four key assumptions:
For each given \(x_i\), \(Y_i\) is a size-1 simple random sample from the distribution of all possible responses, \(Y|X=x_i\).
The association between the explanatory and response variables is linear on average.
The error terms are normally distributed: \(\varepsilon_i \stackrel{iid}{\sim} N(0, \sigma^2) \quad \text{for } i = 1, 2, \ldots, n.\)
The error terms have constant variance \(\sigma^2\) across all values of \(X\).
For detailed discussion on the assumptions, revisit The Simple Linear Regression Model. Note that normality has varying importance across procedures — see Robustness to Normality Assumptions for the full discussion.
Overview of Residuals and Their Properties
Note that \(\varepsilon_i\)’s are the only random component of the current linear regression model, and therefore, all model assumptions are essentially assumptions about the behavior of the error terms.
Also recall the mathematical definition of residuals:
Residuals can be viewed as the observed counterparts of the true error terms \(\varepsilon_i\) because:
Since we do not have access to the true realizations of \(\varepsilon_i\), the residuals instead play a key role in model diagnostics.
13.3.2. Scatter Plot and Residual Plot for Linearity and Constant Variance
We have used scatter plots for the preliminary assessment of the association between two quantitative variables. We introduce the residual plot as an additional tool for model diagnosis; it is simply a scatter plot of \((x_i, e_i)\) for \(i=1,\cdots, n\).
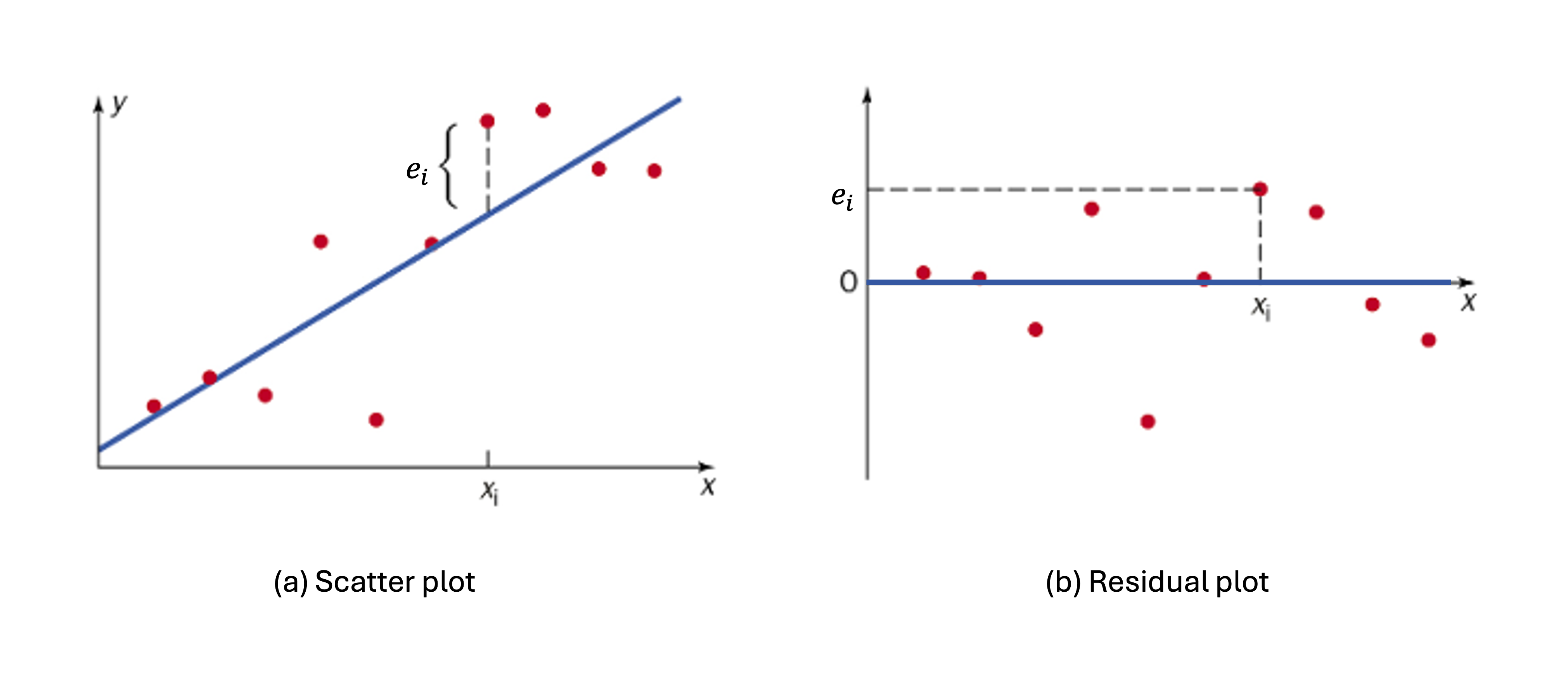
Fig. 13.22 Comparison of scatter plot and residual plot
A residual plot can be viewed as the original scatter plot rotated so that the regression line becomes horizontal. This removes the visual bias of the tilted trend line and highlights the deviations from the fitted line.
Scatter plots and residual plots are typically used together to assess two assumptions: linearity and constant variance.
Characteristics of Ideal Scatter and Residual Plots
When the linearity and constant variance assumptions hold, the points on both the scatter plot and residual plot form a random scatter around their respective summary lines, with a roughly constant spread across the \(x\)-axis.
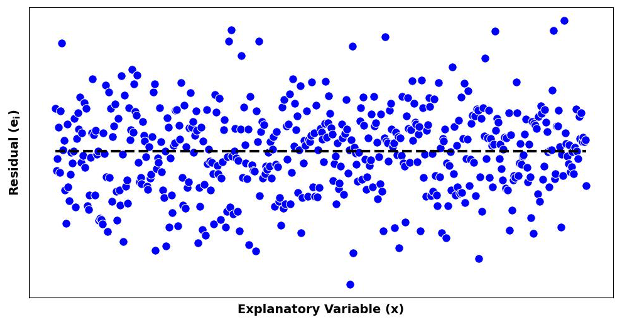
Fig. 13.23 A residual plot showing no signs of assumption violation
Signs of Assumption Violation on Scatter and Residual Plots
1. Violation of the Linearity Assumption
If residuals systematically fall below the zero line in certain regions of \(x\) values and above the line in others, this suggests the true relationship is non-linear.
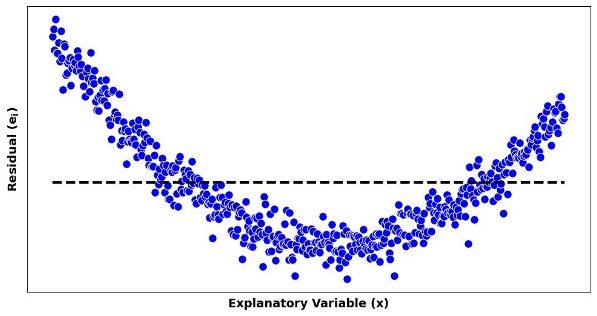
Fig. 13.24 Residual plots with linearity assumption violated
2. Violation of the Constant Variance Assumption
If the spread of points around the trend line is inconsistent, the data likely violate the constant variance assumption.
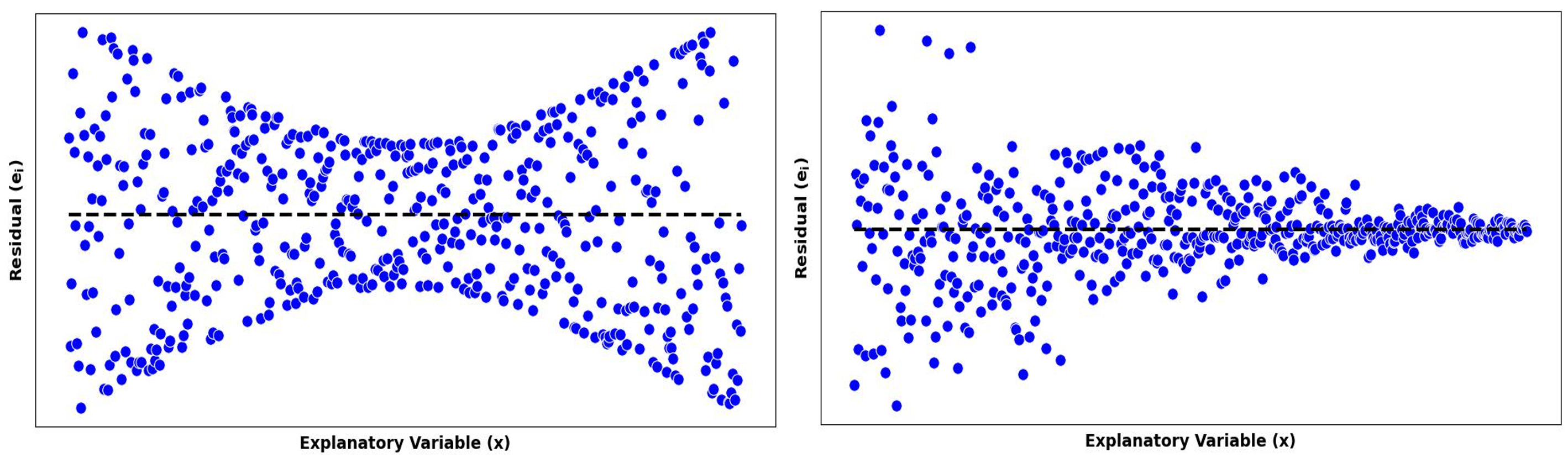
Fig. 13.25 Residual plots with constant variance assumption violated
Hourglass Pattern: The spread is larger for extreme values of \(X\) than in the middle range.
Cone Pattern: As \(X\) increases, the residual errors become larger.
Other patterns of non-constant variance can also occur. Even without systematic patterns, an inconsistent spread alone is a significant sign of assumption violation.
3. Outliers
Recall that scatter plots are also used to identify potential outliers and influential points. Residual plots can serve the same purpose.
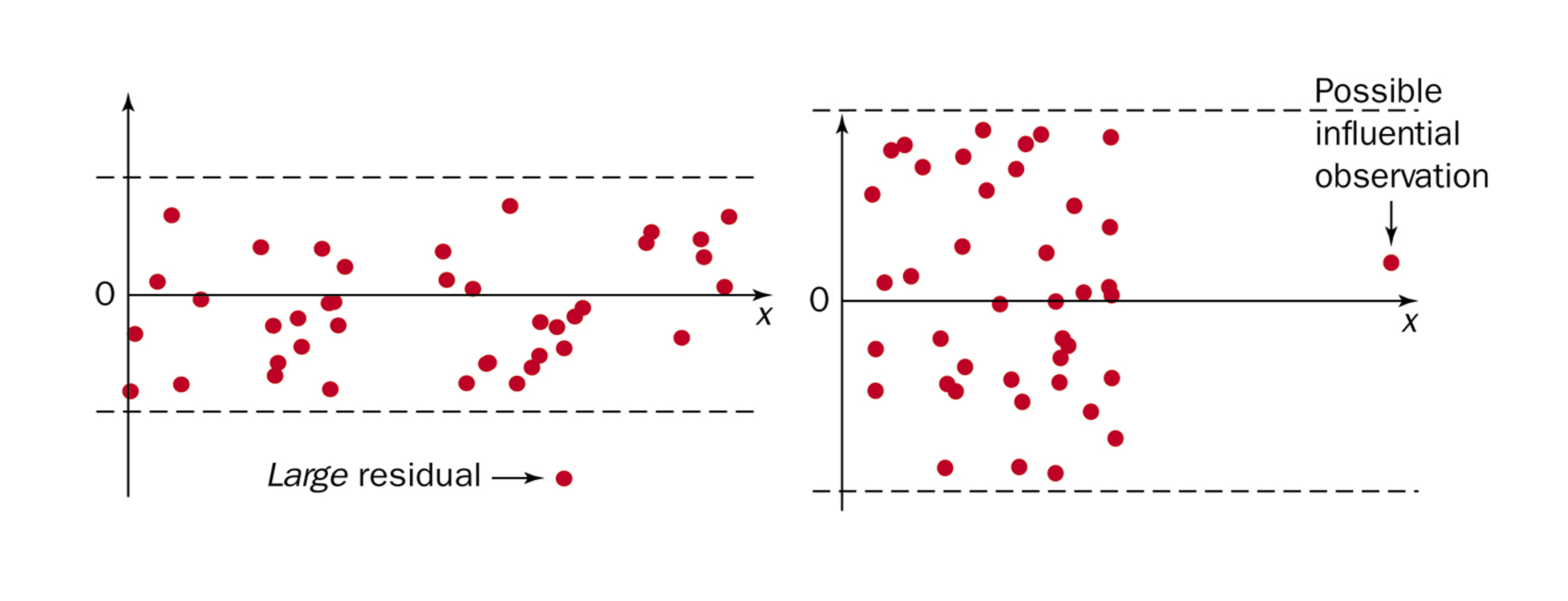
Fig. 13.26 Residual plots with outliers; left plot shows a \(y\)-outlier, and right shows an \(x\)-outlier that potentially has high influence on the model.
Violations May or May not Occur Simultaneously
While Fig. 13.24 show signs of non-linearity, it does not violate the constant variance assumption since the bandwidth of data points around their true summary curve (quadratic association) is reasonably constant.
Likewise, Fig. 13.25 shows no sign of non-linearity, as the patterns of spread above and below the zero line are roughly symmetric.
Be aware that different types of violations may occur simultaneously or separately, and be prepared to distinguish one case from another on the graphs.
Exercise: draw a residual plot that shows violation of linearity and constant variance assumptions simultaneously.
13.3.3. Histogram and Normal Probability Plot of Residuals for Normality
To verify normality of the error terms, we construct a histogram and a normal probability plot of the residuals.
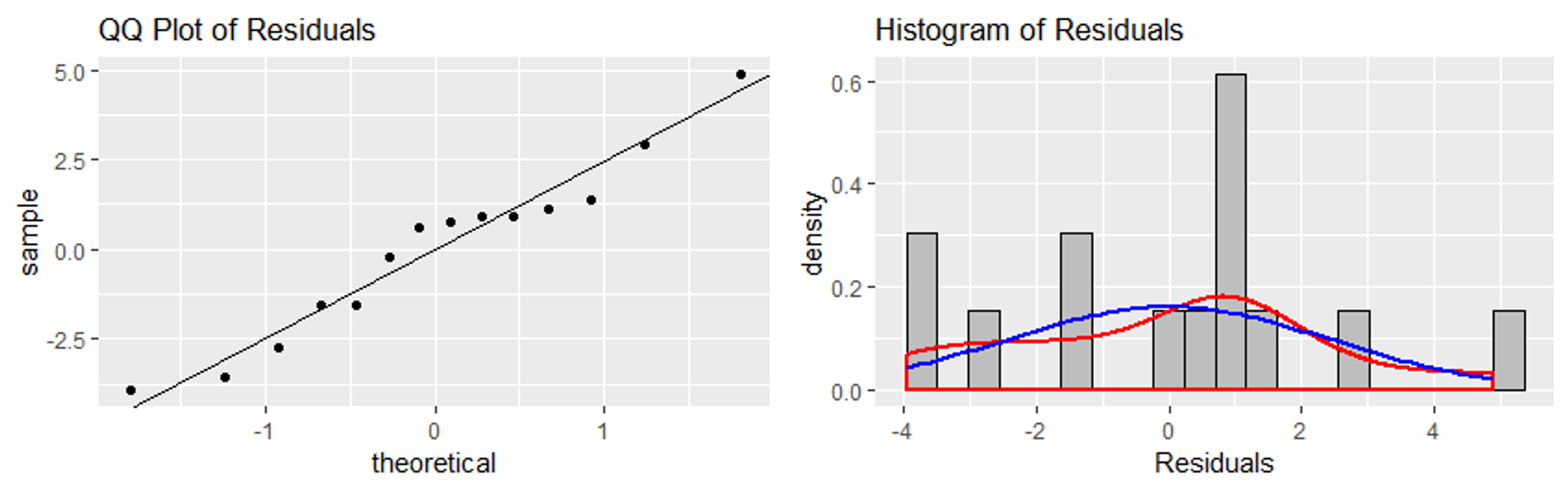
Fig. 13.27 Histogram and normal probability plot of residuals
These plots are used in the same way as in any prior context of normality assessment. We check whether the points follow a straight line on the normal probability plot and whether the histogram is bell-shaped.
13.3.4. Summary of Diagnostic Tools and Comprehensive Examples
We have introduced four graphical tools to assess the assumptions of linear regression. See the table below for a summary:
Assumption |
Graphical Tools |
|---|---|
SRS |
None (must be ensured through experimental design) |
Linearity |
Scatter plot and residual plot |
Constant variance |
Scatter plot and residual plot |
Normality of errors |
Histogram and QQ plot of residuals |
Example 💡: Comprehensive Diagnostic Exercise
For each of the following sets of graphical representations, assess whether the data set meets the assumptions required for valid linear regression.
Example 1
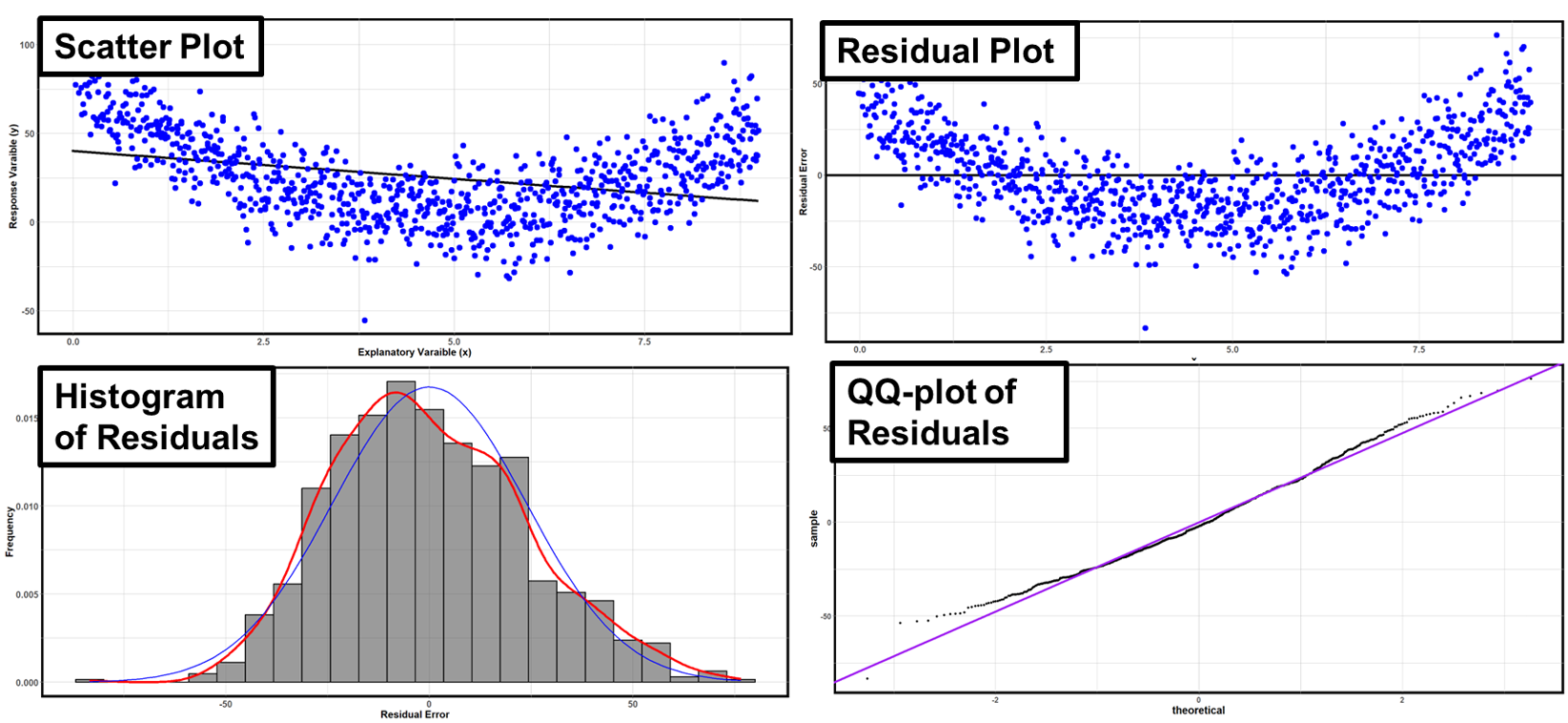
Fig. 13.28 Example 1 of graphical diagnosis
Scatter plot and residual plot show a systematic curved pattern.
If the correct summary curve is used (quadratic form), then the size of their vertical spread would not vary by the \(x\)-values. So non-constant variance is not a concern.
Histogram and normal probability plots look reasonable.
This data set violates the linearity assumption.
Example 2
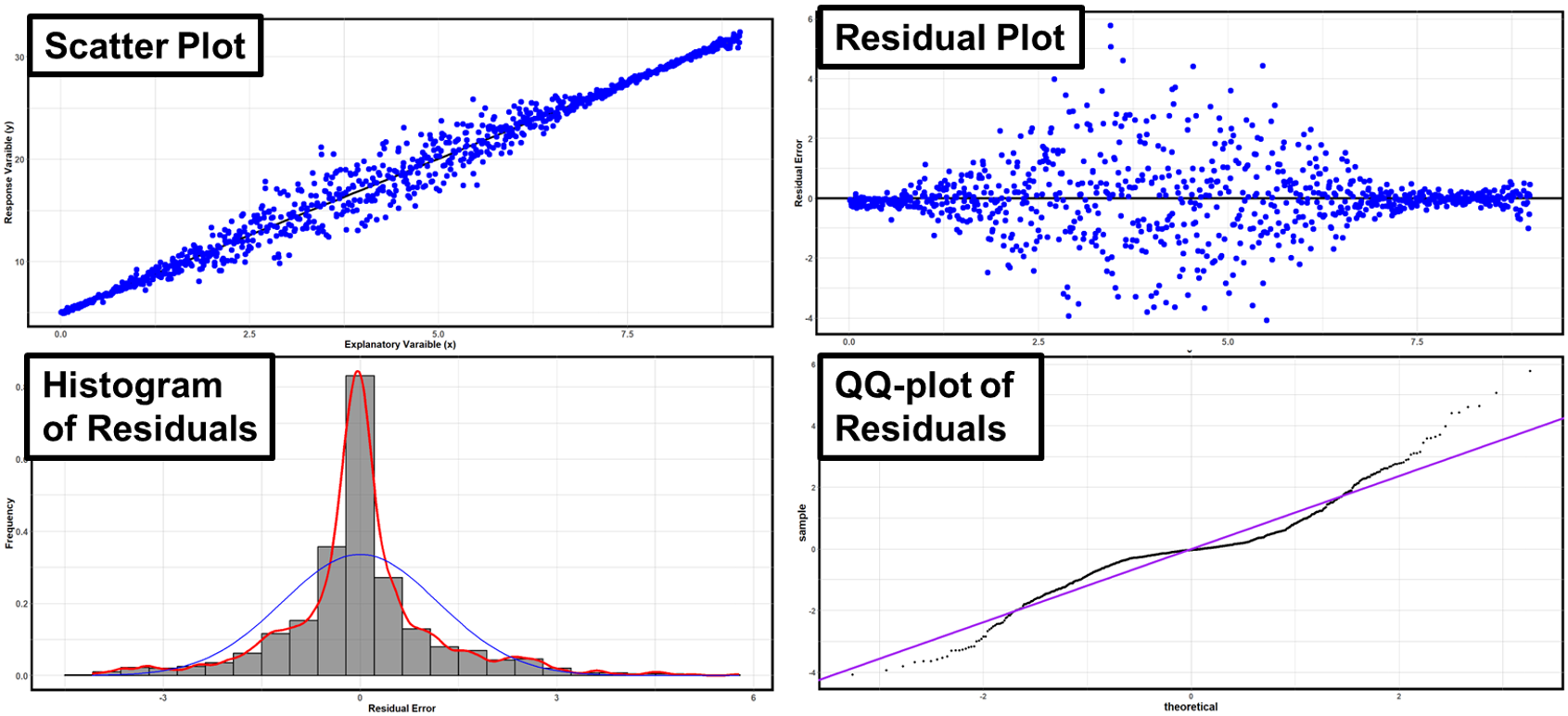
Fig. 13.29 Example 2 of graphical diagnosis
The dots follow a linear pattern according to both the scatter plot and the residual plot—they form mirror images below and above their summary lines.
The spread of the points are narrower in the two ends than in the middle region. This raises a concern for non-constant variance.
The histogram and the QQ plot indicate that the error distribution has heavier tails than the blue curve. The error distribution may not be normal.
This data set violates the constant-variance assumption and is suspected to have non-normal error terms.
When Assumptions Are Violated
If diagnostic procedures reveal serious assumption violations, we should not proceed with linear regression analysis. Instead, we should take an appropriate measure to mitigate the effect of the violation or use a different analysis method.
Linearity Violations:
Consider transformations of variables (log, square root, etc.)
Fit non-linear models (beyond course scope)
Use piecewise or segmented regression for different regions
Constant Variance Violations:
Variable transformations may help stabilize variance
Weighted least squares methods (beyond course scope)
Robust regression techniques
Normality Violations:
For parameter estimation, CIs for the mean response, and hypothesis tests: often less critical at moderate sample sizes because the CLT applies to these averaging-based procedures
For prediction intervals: normality remains critical because the prediction error includes a single future observation that does not benefit from averaging
Bootstrap methods for inference (beyond course scope)
Non-parametric alternatives
Independence Violations:
Time series methods for temporally correlated observations
Mixed effects models for clustered data
13.3.5. The F-Test for Model Utility
Once we have verified that our model assumptions are reasonably satisfied, we proceed with statistical inference. The first question we typically ask is: “Does the simple linear regression model provide useful information about the relationship between the explanatory and response variables?”
We organize our answer to this question into the usual four-step hypothesis test. We refer to the ANOVA table constructed in Chapter 13.2.
Step 1: Parameter of Interest
The focus of this test is on the overall usefulness of the linear relationship rather than on specific parameters. Therefore, it is okay to skip explicit parameter definition.
Step 2: Hypotheses
\(H_0:\) There is no linear association between \(X\) and \(Y\).
\(H_a:\) There is a linear association between \(X\) and \(Y\).
Important: Always state the hypotheses using the experimental context, replacing “X” and “Y” with the actual variable names and providing sufficient background information.
Step 3: Test Statistic and P-value
Recall that MSR is a scaled measurement of the variability attributed to the model structure, while MSE is a scaled measure of random error. Therefore, if MSR is substantially greater than MSE, we can consider the model to be statistically significant.
The corresponding test statistic is:
with degrees of freedom \(df_1 = 1\) and \(df_2 = n-2\).
A large observed value of \(F_{TS}\) is in favor of the alternative hypothesis that the model is significant. Therefore,
Step 4: Decision and Conclusion
If p-value ≤ \(\alpha\):
Reject \(H_0\). At the \(\alpha\) significance level, we have sufficient evidence to conclude that there is a linear association between [explanatory variable] and [response variable] in [context].”
If p-value > \(\alpha\):
Fail to reject \(H_0\). At the \(\alpha\) significance level, we do not have sufficient evidence to conclude that there is a linear association between [explanatory variable] and [response variable] in [context].”
Example 💡: Blood Pressure Study, Continued
Assuming that the assumptions of linear regression have been verified, perform the \(F\)-test for model utility using \(\alpha = 0.05.\) Use the partially filled ANOVA table from the previous lesson:
Source |
df |
Sum of Squares |
Mean Square |
F-statistic |
p-value |
|---|---|---|---|---|---|
Regression |
1 |
\(555.7126\) |
\(555.7126\) |
? |
? |
Error |
\(9\) |
\(382.8267\) |
\(42.5363\) |
||
Total |
\(10\) |
\(938.5393\) |
Step 1: Parameter Definition
This step is skipped for model utility tests.
Step 2: Hypotheses:
\(H_0\): There is no linear association between patient age and change in blood pressure.
\(H_a\): There is a linear association between patient age and change in blood pressure.
Step 3: Computation
The test statistic has two degrees of freedom: \(df_1=1\) and \(df_2=9\). The \(p\)-value is:
Step 4: Conclusion
At \(\alpha = 0.05\), we reject \(H_0\) and conclude that there is sufficient evidence of a linear association between patient age and change in blood pressure.
13.3.6. Distributional Properties of the Slope and Intercept Estimators
To develop inference procedures for \(\beta_0\) and \(\beta_1\), we need to understand the statistical properties of their estimators, \(b_0\) and \(b_1\). This draws distinction from our focus on \(b_0\) and \(b_1\) as estimates so far, yielding one set of realized values based on a single data. We would now like to study their behaviors across many different datasets.
1. Slope and Intercept Estimators Are Linear Combinations of the Responses
The first step in constructing inference for regression parameters is to recognize that their estimators are linear combinations of the response variables, \(Y_i, i=1,\cdots, n\). Capital \(Y\) is used throughout this section to emphasize that we are discussing responses as random variables, not their observed values. The values of the explanatory variable are still considered given and fixed.
We first show that the slope estimator \(b_1\) is a linear combination of \(Y_i, i=1,\cdots, n\), starting with its definition:
Each coefficient to the responses above only consists of non-random quantities involving the explanatory variable.
For the intercept estimator, we borrow the result of Eq. (13.10).
Again, the coefficient of each term above consists of non-random quantities involving only the sample size and the explanatory values.
‼️ Key Observation
Recall that each \(Y_i\) is normally distributed given an observed \(x_i\). Since both \(b_1\) and \(b_0\) are linear combinations of normal random variables, they must also be normally distributed. We now proceed to state their expectations and variances.
2. The Expectation and Variance of the Parameter Estimators
The Slope Estimator
The Intercept Estimator
Key Insights:
Both \(b_1\) and \(b_0\) are unbiased estimators of \(\beta_1\) and \(\beta_0\), respectively.
The slope variance depends only on the error variance and the spread of the explanatory values.
The intercept variance includes additional uncertainty when \(\bar{x} \neq 0\).
Derive the Results as an Independent Exercise
The expectations and variances of both estimators can be derived using general properties and some algebraic manipulation. You are encouraged to verify these results as an independent exercise.
3. The Complete Distribution of the Estimators
Provided that all model assumptions hold,
4. Estimated Standard Errors and t-Distribution
Since \(\sigma^2\) is unknown, we replace it with its estimate \(s^2 = MSE\) to obtain the estimated standard errors:
Studentization of each estimator then gives us a \(t\)-distributed random variable, both with \(df=n-2\):
We use these as the foundation for confidence regions and hypothesis tests on the true values of the regression parameters, \(\beta_1\) and \(\beta_0\).
13.3.7. Confidence Regions for Parameters
Recall the general form of a \(t\)-confidence region:
The table below applies the general form to all possible parameter-side combination:
Side |
\(\beta_0\) |
\(\beta_1\) |
|---|---|---|
CI |
\[b_0 \pm t_{\alpha/2, n-2}\sqrt{MSE\left(\frac{1}{n} + \frac{\bar{x}^2}{S_{XX}}\right)}\]
|
\[b_1 \pm t_{\alpha/2, n-2} \sqrt{\frac{MSE}{S_{XX}}}\]
|
UCB |
\[b_0 + t_{\alpha, n-2}\sqrt{MSE\left(\frac{1}{n} + \frac{\bar{x}^2}{S_{XX}}\right)}\]
|
\[b_1 + t_{\alpha, n-2} \sqrt{\frac{MSE}{S_{XX}}}\]
|
LCB |
\[b_0 - t_{\alpha, n-2}\sqrt{MSE\left(\frac{1}{n} + \frac{\bar{x}^2}{S_{XX}}\right)}\]
|
\[b_1 - t_{\alpha, n-2} \sqrt{\frac{MSE}{S_{XX}}}\]
|
13.3.8. Hypothesis Testing for the Slope Parameter
Step 1: Parameter of Interest
Define \(\beta_1\) as the slope of the true regression line relating [explanatory variable] to [response variable]. Make sure to use experiment-specific variable names and context.
Step 2: Hypotheses
It is possible to construct a one-sided or two-sided hypothesis test for the slope parameter against any null value \(\beta_{10}\).
The most common hypothesis is the two-sided variant with the null value \(\beta_{10} = 0\).
Step 3: Test Statistic and P-value
has \(t\)-distribution with \(df = n-2\). Once an observed value \(t_{TS}\) is obtained, the \(p\)-value computation should align with the sidedness of the hypothesis.
Two-sided: \(p\)-value \(= 2P(T_{n-2} > |t_{TS}|)\)
Upper-tailed: \(p\)-value \(= P(T_{n-2} > t_{TS})\)
Lower-tailed: \(p\)-value \(= P(T_{n-2} < t_{TS})\)
Step 4: Decision and Conclusion
Compare p-value to \(\alpha\) and draw conclusions about the slope parameter in context.
Hypothesis Tests for the Intercept
Hypothesis tests on \(\beta_0\) can be constructed in a similar manner. They are not explored in detail because:
The procedure only differs by the form of the standard error estimate, and
The intercept often does not have any practical significance.
Example 💡: Blood Pressure Study, Continued
For the blood pressure vs age data set, perform a hypothesis test to determine if the slope parameter is non-zero. Then, construct a corresponding confidence region.
Step 1: Define the parameter of interest
We are interested in \(\beta_1\), the true change in blood pressure per year increase in patient age.
Step 2: State the hypotheses
Step 3: Computation
The test statistic is:
The \(p\)-value is:
Step 4: Conclusion
\(p\)-value \(=0.0055 < \alpha\). The null hypothesis is rejected. At \(\alpha=0.05\), there is enough evidence to conclude that the slope of the true linear association between age and change in blood pressure is different than \(0\).
95% Confidence Interval:
The confidence region corresponding to a two-sided hypothesis test is a confidence interval. Use R to compute the critical value:
qt(0.025, df=9, lower.tail=FALSE)
#2.262
Then putting the components together,
We are 95% confident that each additional year of age is associated with a decrease in blood pressure between 0.196 and 0.856 mm Hg after treatment.
13.3.9. Special Case: Equivalence of F-test and t-test
For simple linear regresssion, the hypothesis test on \(H_a: \beta_1 \neq 0\) is equivalent to the \(F\)-test for model utility. Intuitively, this makes sense because, in order for the model to meaningfully describe the response variable, the explanatory variable must have a significant association with it.
Mathematically, this equivalence is explained through the special equality:
To see why this is true, recall that \(b_1 = \frac{S_{XY}}{S_{XX}}\) and \(\text{MSR} = b_1\text{S}_{XY}\). Using these,
This implies that both tests provide identical p-values and conclusions.
The Equivalence Only Holds for Simple LR
The two tests serve different purposes in general linear regression with multiple predictors:
The \(F\)-test assesses whether at least one of the predictors provide useful information about the response variable.
The \(t\)-test on a slope parameter assesses whether the single corresponding predictor is useful.
Example 💡: Blood Pressure Study, Continued
For the blood pressure dataset, verify the equivalence of the model utility \(F\)-test and the two-tailed \(t\)-test on the slope parameter against \(\beta_{10}=0\).
From the two previous examples,
\(t_{TS}^2 = (-3.61)^2 = 13.03\)
\(f_{TS}=13.06\)
There is a small difference due to rounding, but both tests give \(p\)-value \(= 0.0055\). ✔
13.3.10. Bring It All Together
Key Takeaways 📝
Diagnostic plots are essential for verifying model assumptions before conducting hypothesis tests or constructing confidence intervals.
Four key diagnostic tools work together: scatter plots, residual plots, histograms of residuals, and QQ plots provide complementary information about different aspects of model adequacy.
The model utility F-test assesses whether the linear relationship explains a significant portion of the variability in the response variable.
Inference on the slope and intercept adapts familiar principles used in previous inference procedures on single parameters.
In simple linear regression, the model utility F-test is equivalent to the \(t\)-test on \(H_a: \beta_1 \neq 0\).
13.3.11. Exercises
Exercise 1: Diagnostic Plot Interpretation
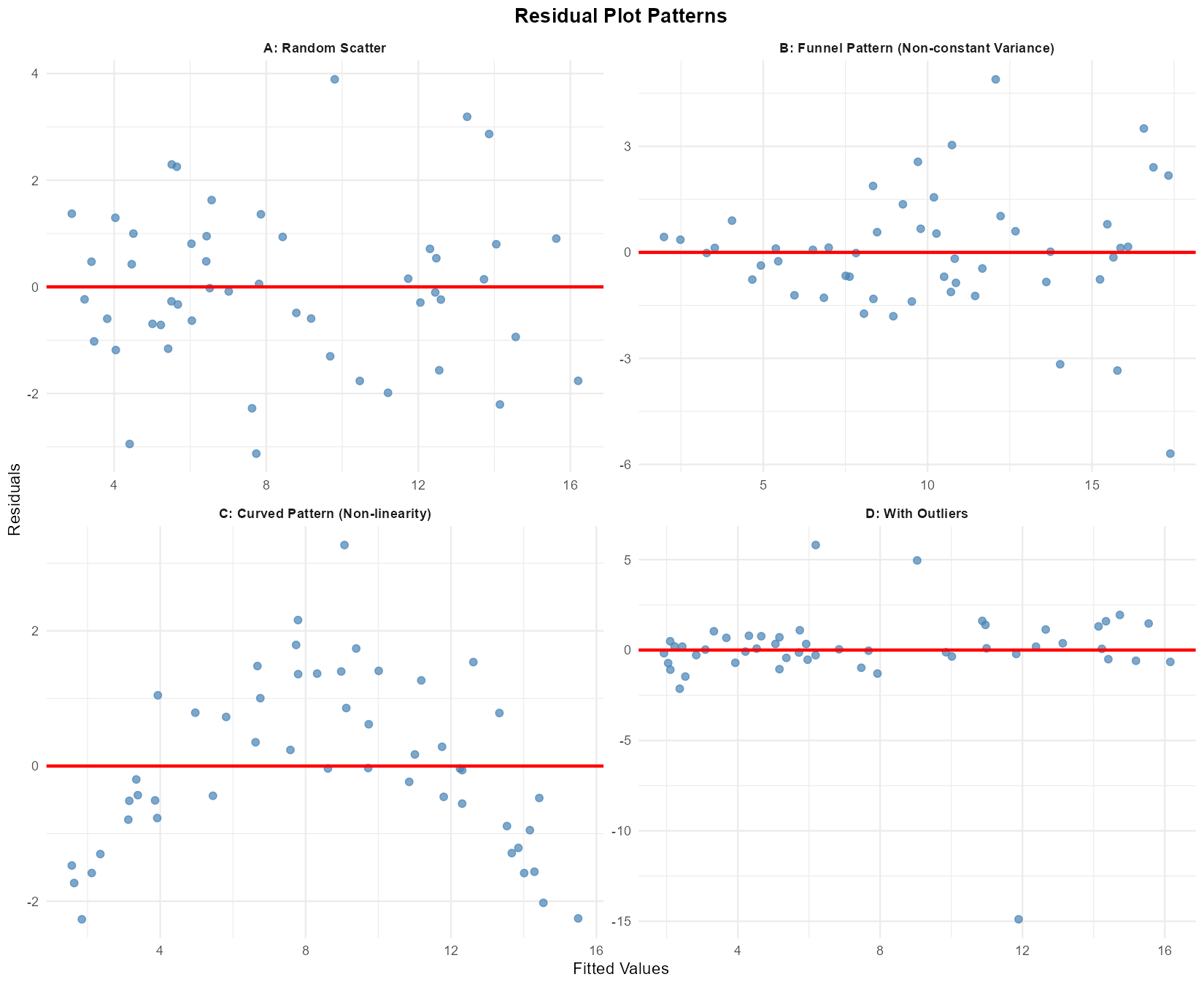
Fig. 13.30 Four residual plots showing different patterns
For each residual plot above (A, B, C, D), identify:
Whether the linearity assumption appears satisfied
Whether the constant variance (homoscedasticity) assumption appears satisfied
Any outliers or influential points
Overall assessment: Is the linear regression model appropriate?
Solution
Plot |
Linearity |
Constant Var |
Outliers |
Model Appropriate? |
|---|---|---|---|---|
A |
✓ Satisfied |
✓ Satisfied |
None |
Yes - proceed |
B |
✓ Satisfied |
✗ Funnel pattern |
None |
No - variance issue |
C |
✗ Curved |
✓ Satisfied |
None |
No - linearity violated |
D |
✓ Satisfied |
✓ Satisfied |
Yes (3) |
Caution - investigate |
Exercise 2: Complete Diagnostic Analysis
A software engineer models the relationship between lines of code (X, in thousands) and execution time (Y, in seconds) for \(n = 25\) programs.
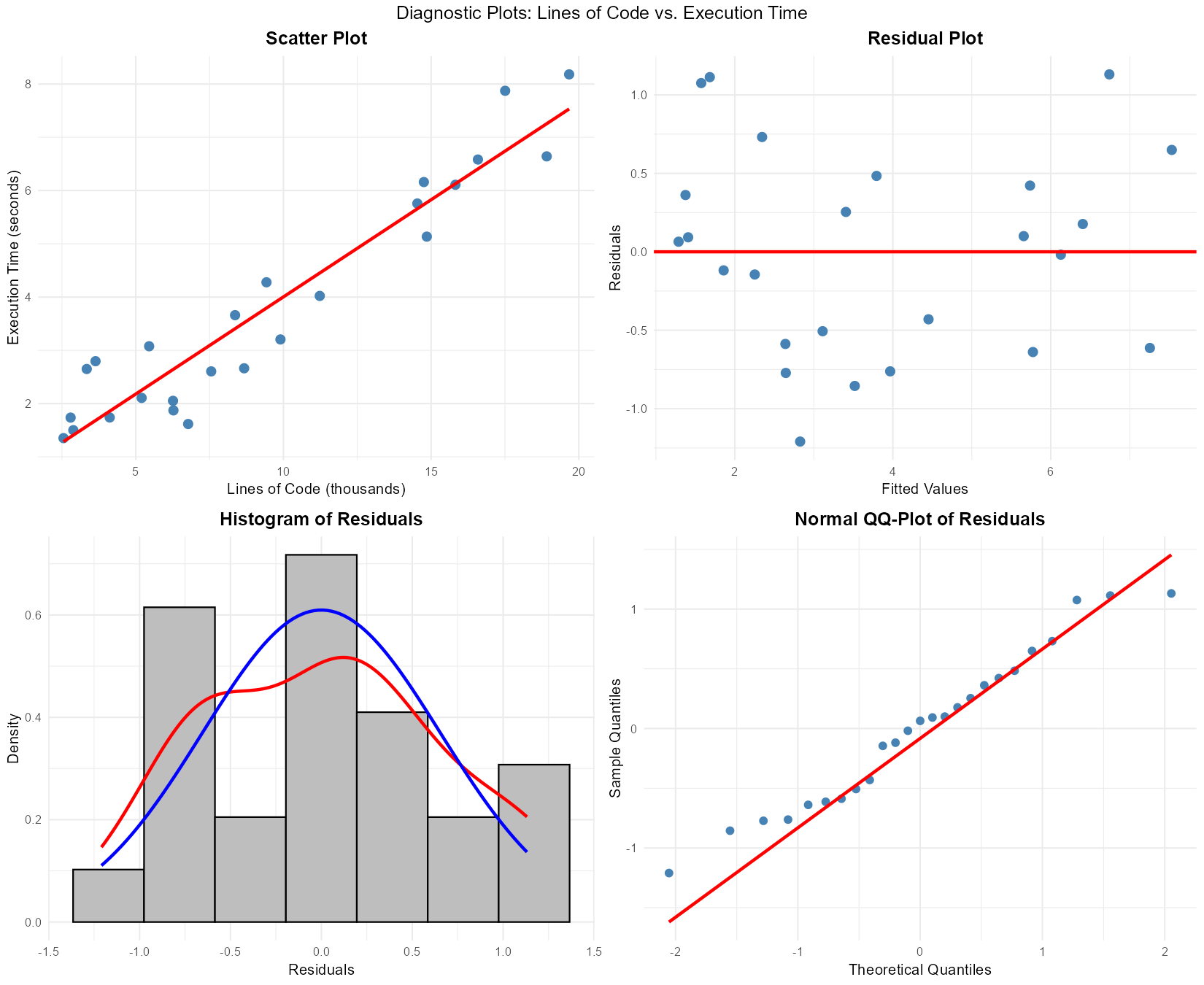
Fig. 13.31 Diagnostic plots: scatter plot, residual plot, histogram, and Q-Q plot
Based on the four diagnostic plots:
Assess the linearity assumption using the scatter plot and residual plot.
Assess the constant variance assumption using the residual plot.
Assess the normality assumption using the histogram and Q-Q plot.
Are there any apparent outliers? If so, describe them.
Would you proceed with inference based on this model? Justify your answer.
Solution
Part (a): Linearity assessment
Scatter plot: Shows a clear positive linear trend with points following an approximately straight pattern
Residual plot: Residuals appear randomly scattered around zero with no systematic curvature
Conclusion: Linearity assumption is satisfied ✓
Part (b): Constant variance assessment
Residual plot: The vertical spread of residuals appears roughly constant across all fitted values
No funnel shape or systematic change in spread
Conclusion: Equal variance assumption is satisfied ✓
Part (c): Normality assessment
Histogram: Residuals show an approximately symmetric, bell-shaped distribution
The kernel density (red) and normal curve (blue) align reasonably well
Q-Q plot: Points fall close to the reference line with no major systematic departures
Conclusion: Normality assumption is satisfied ✓
Part (d): Outliers
No obvious outliers. All points appear consistent with the general pattern, and no residuals are extremely far from zero.
Part (e): Proceed with inference?
Yes, inference is appropriate. All four assumptions (LINE) appear to be satisfied:
Linearity: Yes (scatter and residual plots)
Independence: Assumed (no time ordering mentioned)
Normality: Yes (histogram and Q-Q plot)
Equal variance: Yes (residual plot)
The model is well-suited for hypothesis tests and confidence intervals.
Exercise 3: ANOVA F-Test for Model Utility
An industrial engineer studies the relationship between conveyor belt speed (ft/min) and defect rate (defects per 1000 units). With \(n = 18\) production runs:
SSR = 245.6
SSE = 89.4
State the hypotheses for testing model utility.
Complete the ANOVA table and calculate the F-statistic.
Find the p-value using R:
pf(F_stat, 1, 16, lower.tail = FALSE)At \(\alpha = 0.05\), what is your conclusion? State it in context using proper conclusion format.
Solution
Part (a): Hypotheses
\(H_0: \beta_1 = 0\) (There is no linear relationship between conveyor speed and defect rate)
\(H_a: \beta_1 \neq 0\) (There is a linear relationship between conveyor speed and defect rate)
Part (b): ANOVA Table
Source |
df |
SS |
MS |
F |
|---|---|---|---|---|
Regression |
1 |
245.6 |
245.6 |
43.97 |
Error |
16 |
89.4 |
5.5875 |
|
Total |
17 |
335.0 |
Calculations:
\(df_{Error} = n - 2 = 18 - 2 = 16\)
\(MSR = 245.6/1 = 245.6\)
\(MSE = 89.4/16 = 5.5875\)
\(F = MSR/MSE = 245.6/5.5875 = 43.97\)
Part (c): P-value
pf(43.97, 1, 16, lower.tail = FALSE)
# p-value = 6.86e-06
Part (d): Conclusion
At \(\alpha = 0.05\), since p-value (6.86 × 10⁻⁶) < 0.05, we reject \(H_0\).
There is sufficient evidence to conclude that there is a significant linear relationship between conveyor belt speed and defect rate.
Exercise 4: Inference for the Slope
From a regression of drug dosage (mg) on patient recovery time (days) with \(n = 24\) patients:
\(b_1 = -0.85\) (days per mg)
\(SE_{b_1} = 0.23\)
Construct a 95% confidence interval for the true slope \(\beta_1\).
Interpret this confidence interval in context.
Test \(H_0: \beta_1 = 0\) vs \(H_a: \beta_1 \neq 0\) at \(\alpha = 0.05\).
State the test statistic formula and calculate \(t_{TS}\)
Find the p-value
State your conclusion in context using proper format
Is the result of part (c) consistent with your confidence interval in part (a)? Explain.
Solution
Part (a): 95% CI for slope
Degrees of freedom: \(df = n - 2 = 24 - 2 = 22\)
Critical value: \(t_{0.025, 22} = 2.074\)
95% CI: (−1.33, −0.37)
Part (b): Interpretation
We are 95% confident that the true slope \(\beta_1\) is between −1.33 and −0.37 days per mg.
In context: For each additional mg of drug dosage, recovery time decreases by between 0.37 and 1.33 days, on average.
Part (c): Hypothesis test
Step 1: Parameter: \(\beta_1\) = true change in recovery time per mg increase in dosage
Step 2: \(H_0: \beta_1 = 0\) vs. \(H_a: \beta_1 \neq 0\)
Step 3: Test statistic:
P-value (two-sided): 2 * pt(abs(-3.70), 22, lower.tail = FALSE) = 0.0012
Step 4: At \(\alpha = 0.05\), since p-value (0.0012) < 0.05, we reject \(H_0\).
There is sufficient evidence to conclude that drug dosage has a significant linear effect on recovery time.
Part (d): Consistency
Yes, the results are consistent. The CI (−1.33, −0.37) does not contain 0, which corresponds to rejecting \(H_0: \beta_1 = 0\). This illustrates the duality between confidence intervals and hypothesis tests.
Exercise 5: Inference for the Intercept
Using the drug dosage regression from Exercise 4:
\(b_0 = 14.2\) (days)
\(SE_{b_0} = 1.85\)
\(n = 24\)
Interpret \(b_0\) in context. Is this interpretation meaningful?
Construct a 90% confidence interval for \(\beta_0\).
Test \(H_0: \beta_0 = 12\) vs \(H_a: \beta_0 \neq 12\) at \(\alpha = 0.10\).
Solution
Part (a): Interpretation of b₀
\(b_0 = 14.2\) represents the predicted recovery time (in days) when drug dosage is 0 mg.
Is it meaningful? Only if dosage = 0 is within or near the range of observed data. If the study only included positive dosages (e.g., 5-50 mg), then \(b_0\) is an extrapolation and may not have practical meaning. It would represent the baseline recovery time without the drug.
Part (b): 90% CI for β₀
\(df = 22\), \(t_{0.05, 22} = 1.717\)
90% CI: (11.02, 17.38)
Part (c): Test H₀: β₀ = 12
Test statistic:
P-value: 2 * pt(1.19, 22, lower.tail = FALSE) = 0.247
At \(\alpha = 0.10\), since p-value (0.247) > 0.10, we fail to reject \(H_0\).
There is not sufficient evidence to conclude that the true intercept differs from 12 days.
Exercise 6: F-test and t-test Relationship
For a simple linear regression with \(n = 30\) observations, the following results were obtained:
t-statistic for testing \(H_0: \beta_1 = 0\): \(t_{TS} = 4.28\)
F-statistic for model utility: \(F_{TS} = 18.32\)
Verify that \(F_{TS} = t_{TS}^2\) (allowing for rounding).
What are the degrees of freedom for the t-test? For the F-test?
Why is this relationship only true for simple linear regression (one predictor)?
Using
pt()andpf(), verify that the p-values are the same.
Solution
Part (a): Verify F = t²
\(t_{TS}^2 = (4.28)^2 = 18.32 = F_{TS}\) ✓
The relationship holds exactly.
Part (b): Degrees of freedom
t-test: \(df = n - 2 = 30 - 2 = 28\)
F-test: \(df_1 = 1\) (numerator), \(df_2 = n - 2 = 28\) (denominator)
Part (c): Why only for simple linear regression?
This relationship \(F = t^2\) holds only when:
There is exactly one predictor (df₁ = 1 for the F-test)
The t-test is for \(H_0: \beta_1 = 0\)
In multiple regression with \(k > 1\) predictors, the overall F-test has \(df_1 = k\), and there’s no single t-statistic that corresponds to it. Each predictor has its own t-test, but these are not equivalent to the overall F-test.
Part (d): P-value verification
# t-test p-value (two-sided)
2 * pt(4.28, 28, lower.tail = FALSE)
# [1] 0.000196
# F-test p-value
pf(18.32, 1, 28, lower.tail = FALSE)
# [1] 0.000196
The p-values are identical (within rounding), confirming the equivalence of the two tests for simple linear regression.
Exercise 7: Comprehensive Hypothesis Test
A civil engineer studies the relationship between traffic volume (vehicles per hour) and road surface wear (mm of depth reduction per year). Data from \(n = 15\) road sections yields:
\(\hat{y} = 0.12 + 0.0008x\)
\(R^2 = 0.72\)
\(MSE = 0.0045\)
\(S_{XX} = 12500000\)
Calculate \(SE_{b_1}\).
Test whether there is a significant positive relationship between traffic volume and road wear at \(\alpha = 0.01\).
Step 1: Define the parameter of interest.
Step 2: State \(H_0\) and \(H_a\) (in symbols and words).
Step 3: Calculate the test statistic and p-value. Report degrees of freedom.
Step 4: State your conclusion in context.
Construct a 99% confidence interval for \(\beta_1\).
Construct a 99% lower confidence bound for \(\beta_1\).
Solution
Part (a): Calculate \(SE_{b_1}\)
Part (b): Four-Step Hypothesis Test
Step 1: Let \(\beta_1\) = the true change in road wear (mm/year) per additional vehicle per hour.
Step 2:
\(H_0: \beta_1 = 0\) (no linear relationship between traffic volume and road wear)
\(H_a: \beta_1 > 0\) (positive linear relationship — more traffic causes more wear)
Step 3: Test statistic and p-value
\(df = n - 2 = 13\)
P-value: pt(42.1, 13, lower.tail = FALSE) ≈ 0 (essentially zero)
Step 4: At \(\alpha = 0.01\), since p-value ≈ 0 < 0.01, we reject \(H_0\).
There is sufficient evidence to conclude that there is a significant positive linear relationship between traffic volume and road surface wear.
Part (c): 99% CI for \(\beta_1\)
\(t_{0.005, 13} = 3.012\)
99% CI: (0.000743, 0.000857)
Part (d): 99% Lower Confidence Bound
For a one-sided bound: \(t_{0.01, 13} = 2.650\)
99% LCB: 0.000750
We are 99% confident that each additional vehicle per hour increases road wear by at least 0.00075 mm/year.
Exercise 8: Model Utility with R Output
The following R output is from a regression of patient systolic blood pressure (mmHg) on age (years):
Call:
lm(formula = BP ~ Age, data = patients)
Residuals:
Min 1Q Median 3Q Max
-15.234 -5.891 -0.456 4.789 18.234
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 95.4500 5.2340 18.236 < 2e-16 ***
Age 0.8920 0.1120 7.964 2.34e-09 ***
Residual standard error: 8.456 on 38 degrees of freedom
Multiple R-squared: 0.6253, Adjusted R-squared: 0.6154
F-statistic: 63.43 on 1 and 38 DF, p-value: 2.341e-09
Write the fitted regression equation.
Interpret the slope in context.
What is the estimate of \(\sigma\)?
What is \(R^2\)? Interpret it.
Is the model statistically significant at \(\alpha = 0.01\)? Cite the relevant test statistic and p-value.
Construct a 95% confidence interval for the slope using the output.
Solution
Part (a): Fitted equation
\(\widehat{BP} = 95.45 + 0.892 \times Age\)
Or: Predicted Systolic BP = 95.45 + 0.892(Age)
Part (b): Slope interpretation
For each additional year of age, systolic blood pressure increases by an estimated 0.892 mmHg, on average.
Part (c): Estimate of σ
\(\hat{\sigma} = 8.456\) mmHg (residual standard error from output)
Part (d): R² interpretation
\(R^2 = 0.6253\)
Approximately 62.5% of the variation in systolic blood pressure is explained by the linear relationship with age.
Part (e): Model significance
Yes, the model is statistically significant at \(\alpha = 0.01\).
F-statistic = 63.43 on 1 and 38 DF
p-value = 2.341 × 10⁻⁹ < 0.01
(Equivalently: t = 7.964 for the slope, p-value = 2.34 × 10⁻⁹)
Part (f): 95% CI for slope
\(t_{0.025, 38} = 2.024\)
95% CI: (0.665, 1.119)
We are 95% confident that for each additional year of age, systolic BP increases by between 0.67 and 1.12 mmHg.
Exercise 9: Assumption Checking in R
A researcher has fitted a regression model and needs to check assumptions. Complete the following R code to create proper diagnostic plots:
# Fit the model
fit <- lm(y ~ x, data = mydata)
# Create residual plot
mydata$fitted <- ____________
mydata$residuals <- ____________
ggplot(mydata, aes(x = fitted, y = residuals)) +
geom_point() +
geom_hline(yintercept = ____, color = "blue", linewidth = 1) +
labs(title = "Residual Plot",
x = "____________",
y = "____________") +
theme_minimal()
# Create Q-Q plot of residuals
ggplot(mydata, aes(sample = ____________)) +
stat_qq() +
stat_qq_line(color = "red", linewidth = 1) +
labs(title = "Normal Q-Q plot of Residuals",
x = "Theoretical Quantiles",
y = "Sample Quantiles") +
theme_minimal()
Fill in the blanks to complete the code.
What pattern in the residual plot would indicate non-constant variance?
What pattern in the Q-Q plot would indicate heavy-tailed residuals?
Solution
Part (a): Completed code
# Fit the model
fit <- lm(y ~ x, data = mydata)
# Create residual plot
mydata$fitted <- fitted(fit)
mydata$residuals <- residuals(fit)
ggplot(mydata, aes(x = fitted, y = residuals)) +
geom_point() +
geom_hline(yintercept = 0, color = "blue", linewidth = 1) +
labs(title = "Residual Plot",
x = "Fitted Values",
y = "Residuals") +
theme_minimal()
# Create Q-Q plot of residuals
ggplot(mydata, aes(sample = residuals)) +
stat_qq() +
stat_qq_line(color = "red", linewidth = 1) +
labs(title = "Normal Q-Q plot of Residuals",
x = "Theoretical Quantiles",
y = "Sample Quantiles") +
theme_minimal()
Part (b): Non-constant variance pattern
A funnel shape (or megaphone/cone pattern) in the residual plot indicates non-constant variance:
Opening funnel: Variance increases with fitted values (common)
Closing funnel: Variance decreases with fitted values (less common)
The vertical spread of residuals should be roughly constant across all fitted values for the assumption to be satisfied.
Part (c): Heavy-tailed residuals
In the Q-Q plot, heavy-tailed residuals show an S-shape:
Points curve below the reference line on the left side
Points curve above the reference line on the right side
This indicates more extreme values than a normal distribution would produce.
13.3.12. Additional Practice Problems
True/False Questions (1 point each)
If the 95% confidence interval for \(\beta_1\) contains 0, then the \(F\)-test for model utility will also fail to reject \(H_0\) at \(\alpha = 0.05\).
Ⓣ or Ⓕ
In simple linear regression, the \(F\)-test for model utility and the two-sided \(t\)-test for the slope always produce the same p-value.
Ⓣ or Ⓕ
A significant p-value for the slope guarantees that all four LINE assumptions are satisfied.
Ⓣ or Ⓕ
A fan-shaped pattern in the residual plot (residuals spreading out as fitted values increase) indicates a violation of the constant variance assumption.
Ⓣ or Ⓕ
If the residuals in a regression analysis are normally distributed, the data points in a QQ-plot of residuals will closely follow a straight line.
Ⓣ or Ⓕ
The degrees of freedom for the \(t\)-test on \(\beta_1\) in simple linear regression is \(n - 1\).
Ⓣ or Ⓕ
Multiple Choice Questions (2 points each)
A biomedical engineer fits a simple linear regression with \(b_1 = 4.2\) and \(SE_{b_1} = 1.05\) using \(n = 27\) observations. What is the test statistic for \(H_0\!: \beta_1 = 0\)?
Ⓐ \(t_{TS} = 0.25\)
Ⓑ \(t_{TS} = 3.15\)
Ⓒ \(t_{TS} = 4.00\)
Ⓓ \(t_{TS} = 4.41\)
For the test in Question 7, the degrees of freedom are:
Ⓐ 26
Ⓑ 25
Ⓒ 27
Ⓓ 28
A regression model has \(F_{TS} = 9\). What is \(|t_{TS}|\) for the two-sided test of \(H_0\!: \beta_1 = 0\)?
Ⓐ 3.0
Ⓑ 4.5
Ⓒ 9.0
Ⓓ 81.0
Which diagnostic plot is used to check the linearity and constant variance assumptions in the LINE framework?
Ⓐ Histogram of the response variable \(Y\)
Ⓑ QQ-plot of the residuals
Ⓒ Residuals vs. fitted values plot
Ⓓ Scatter plot of \(Y\) vs. \(X\) with no fitted line
A residual plot shows a clear curved (quadratic) pattern with residuals positive at low and high fitted values and negative in the middle. This pattern most directly indicates a violation of:
Ⓐ Independence
Ⓑ Normality
Ⓒ Linearity
Ⓓ Equal variance
A mechanical engineer fits a simple linear regression model and obtains the following R output:
Coefficients: Estimate Std. Error t value Pr(>|t|) (Intercept) 12.500 3.200 3.906 0.00058 pressure 0.840 0.150 5.600 0.00001 Residual standard error: 4.2 on 28 degrees of freedomWhat is the 95% confidence interval for \(\beta_1\)? Use \(t_{0.025, 28} = 2.048\).
Ⓐ \((0.533,\ 1.147)\)
Ⓑ \((0.690,\ 0.990)\)
Ⓒ \((0.753,\ 0.927)\)
Ⓓ \((0.527,\ 1.153)\)
Answers to Practice Problems
True/False Answers:
True — By the duality between confidence intervals and hypothesis tests, if 0 is inside the 95% CI for \(\beta_1\), then the two-sided \(t\)-test does not reject at \(\alpha = 0.05\). In SLR, the \(F\)-test is equivalent to this two-sided \(t\)-test, so it also fails to reject.
True — In simple linear regression, \(F = t^2\) and the p-values are identical. This equivalence holds only for simple (not multiple) linear regression.
False — A significant p-value tells us there is evidence of a linear relationship, but it says nothing about whether the assumptions underlying the model are satisfied. Assumptions must be verified through diagnostic plots.
True — A fan shape indicates that the spread of residuals changes with the level of the fitted values, violating the constant variance (homoscedasticity) assumption in LINE.
True — The QQ-plot compares the sample quantiles of the residuals to theoretical normal quantiles. If the residuals are normally distributed, the points will fall approximately along the reference line.
False — The degrees of freedom for the \(t\)-test on \(\beta_1\) in simple linear regression is \(n - 2\), not \(n - 1\).
Multiple Choice Answers:
Ⓒ — \(t_{TS} = \frac{b_1}{SE_{b_1}} = \frac{4.2}{1.05} = 4.00\).
Ⓑ — In simple linear regression, \(df = n - 2 = 27 - 2 = 25\).
Ⓐ — In SLR, \(F = t^2\), so \(|t| = \sqrt{F} = \sqrt{9} = 3.0\).
Ⓒ — The residuals vs. fitted values plot is the primary diagnostic for checking both linearity (no systematic pattern) and constant variance (uniform spread). The QQ-plot checks normality, not linearity or constant variance.
Ⓒ — A systematic curved pattern in the residual plot indicates that the true relationship is not linear. This is a violation of the L (Linearity) assumption in LINE.
Ⓐ — \(CI = b_1 \pm t_{0.025, 28} \cdot SE_{b_1} = 0.840 \pm 2.048(0.150) = 0.840 \pm 0.307 = (0.533,\ 1.147)\).