Section 5.8 Hierarchical Models and Partial Pooling (Optional)
Optional Section — Self-Study
This section is not covered in class; it is kept as a self-study reference. Nothing later in the course depends on it: the chapter summary recaps its ideas, and Chapter 6 does not use hierarchical models. It is, however, the natural next step in Bayesian modeling — read it when your data arrive in groups (students within schools, patients within hospitals): partial pooling, the canonical Eight Schools problem, the funnel geometry that breaks naive MCMC and the non-centred parameterisation that fixes it, and LOO comparison of pooling strategies, closing the loop with Section 5.7.
Every model in this chapter so far has treated its data as a single undifferentiated group. The Beta-Binomial model in Section 5.2 Prior Specification and Conjugate Analysis estimated one probability \(\theta\) from one sequence of trials. The logistic regression in Section 5.6 Probabilistic Programming with PyMC estimated one coefficient vector \(\boldsymbol{\beta}\) from one dataset. But data in the real world are rarely so uniform. Exam scores come from different instructors. Clinical outcomes come from different hospitals. Species counts come from different ecosystems. In each case you have multiple related groups, and you face a choice: should you treat the groups as identical, treat them as completely unrelated, or try to learn both what they share and how they differ?
Hierarchical models formalise the third option. They place a distribution over group-level parameters, so that each group gets its own estimate but that estimate is informed by the data from every other group. The result is called partial pooling, and it is one of the most practically useful ideas in applied statistics. Groups with abundant data are left largely alone; groups with sparse data are pulled toward the overall pattern. The amount of pulling is not chosen by the analyst — it is learned from the data.
This section develops hierarchical models from motivation through implementation. We begin with the three pooling strategies and their tradeoffs (§5.8.1), formalise the mathematical structure (§5.8.2), work through the canonical Eight Schools problem including the geometry that makes naive MCMC fail (§5.8.3), demonstrate the same hierarchical idea with a categorical likelihood (§5.8.4), and close the loop with Section 5.7 Bayesian Model Comparison by comparing pooling strategies quantitatively using LOO (§5.8.5). A practical decision guide (§5.8.6) concludes the chapter’s final section.
Road Map 🧭
Understand: Why partial pooling adaptively balances bias and variance across groups, and what exchangeability means as a modeling assumption
Develop: Facility with hierarchical model specification, the centred/non-centred parameterisation trade-off, and the geometry of Neal’s funnel
Implement: Hierarchical Normal and Dirichlet-Multinomial models in PyMC, including non-centred reparameterisation, forest plots, and LOO model comparison
Evaluate: When hierarchical structure improves inference, how to diagnose funnel pathology, and how to compare pooling strategies quantitatively
The Pooling Problem
Before introducing any machinery, consider a concrete scenario. Five instructors each teach the same introductory statistics course to sections of 10–20 students. At the end of the semester, every student takes the same final exam. You want to estimate each instructor’s true average exam score \(\mu_i\). Three strategies present themselves.
Complete Pooling
Ignore the instructor variable entirely. Pool all students into a single group, fit one overall mean \(\mu\), and assign that estimate to every instructor:
where \(y_{ij}\) is the exam score for student \(j\) in instructor \(i\)’s section, and a single \(\mu\) is shared across all five sections. This model is fast and yields narrow intervals because it uses all the data, but it is unfair: instructors who are genuinely different get averaged away. If one instructor’s true mean is 85 and another’s is 65, both receive the same estimate of roughly 75. Complete pooling trades bias for precision.
No Pooling
Fit a separate, independent model to each instructor’s section:
for \(i = 1, \ldots, 5\). Now each instructor gets an unbiased estimate of their own mean. The cost is variance: an instructor with only 8 students gets a wide credible interval because the model has no way to borrow information from the other 60 students in the dataset. No pooling treats every group as if it has nothing in common with any other group. This is inefficient when the groups genuinely are related, and it cannot make predictions for a new instructor (one not in the training data) because new groups have no parameters at all.
Partial Pooling (Hierarchical)
Model the instructor-level means as draws from a common distribution:
with shared hyperparameters \(\mu\) (grand mean across instructors) and \(\tau\) (between-instructor standard deviation), and hyperpriors \(\mu \sim \mathcal{N}(50, 25)\), \(\tau \sim \text{HalfNormal}(10)\), \(\sigma \sim \text{HalfNormal}(15)\).
Each instructor’s estimate \(\hat{\mu}_i\) is pulled toward the grand mean \(\mu\) by an amount that depends on two factors: (i) how much data that instructor has — instructors with more students are pulled less — and (ii) how similar the instructors are overall — when \(\tau\) is small, the data indicate that instructors are similar, so every group is pulled substantially; when \(\tau\) is large, the data indicate genuine diversity, so the pull is weak.
This adaptive compromise between the two extreme strategies is called shrinkage. Partial pooling gives narrower intervals than no pooling for groups with sparse data, while barely affecting groups with abundant data. It does not force a one-size-fits-all answer (unlike complete pooling), but it does use the overall pattern to stabilise noisy estimates (unlike no pooling).
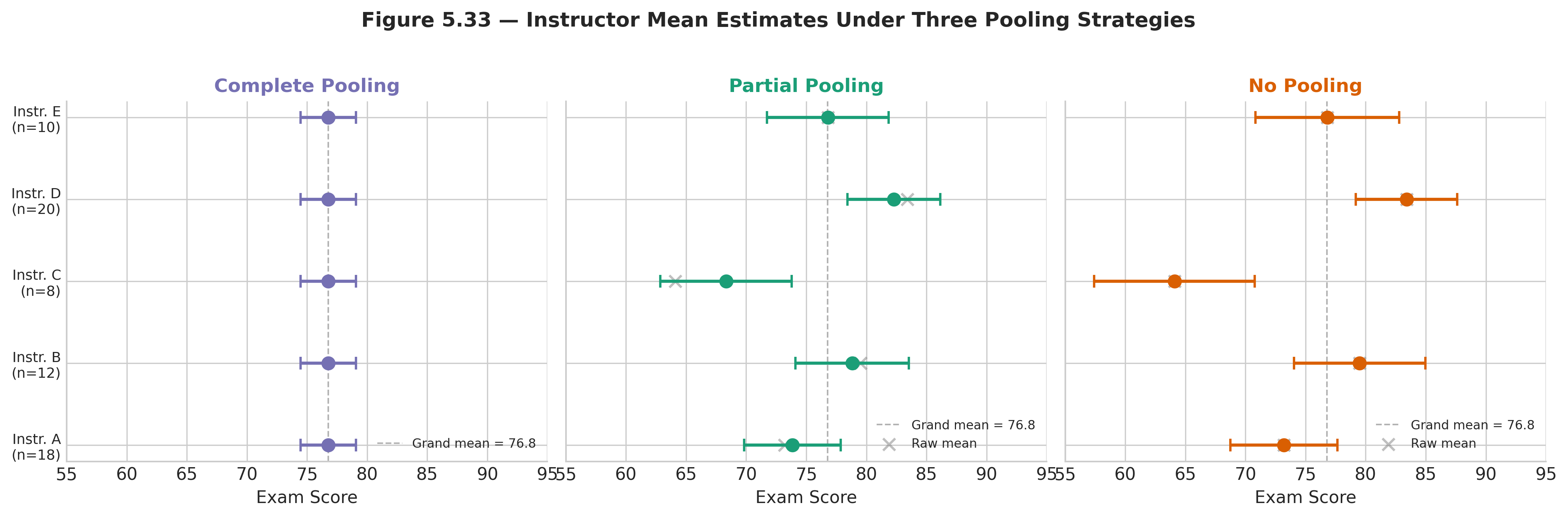
Fig. 204 Figure 5.33 — Instructor mean estimates under three pooling strategies. Complete pooling (left) assigns one value to all instructors. No pooling (centre) gives unbiased but noisy estimates, especially for instructors with small sections. Partial pooling (right) shrinks small-section estimates toward the grand mean while leaving large-section estimates largely unchanged.
Definition: Key Hierarchical Vocabulary
Hyperparameters are parameters that govern the distribution of other parameters. In the instructor example, \(\mu\) and \(\tau\) are hyperparameters because they control the Normal distribution from which the group-level means \(\mu_i\) are drawn.
Hyperpriors are the prior distributions placed on hyperparameters. The choices \(\mu \sim \mathcal{N}(50, 25)\) and \(\tau \sim \text{HalfNormal}(10)\) are hyperpriors.
Shrinkage is the pull of group-level estimates toward the grand mean. Shrinkage is stronger for groups with less data and weaker for groups with more data. In the no-pooling model, shrinkage is zero. In the complete-pooling model, shrinkage is total. The hierarchical model estimates the appropriate amount of shrinkage from the data.
The Mathematical Structure
A hierarchical model organises parameters into levels. At the bottom are the observations, governed by group-specific parameters. At the middle level, the group parameters are governed by shared hyperparameters. At the top, hyperpriors express uncertainty about the hyperparameters themselves. This three-level structure is the defining feature of the hierarchical framework.
The Generative Story
Writing the model top-down as a generative process makes the structure transparent:
where \(J\) is the number of groups, \(n_i\) is the sample size in group \(i\), and the total dataset contains \(N = \sum_{i=1}^{J} n_i\) observations.
The joint model factors as:
Read this factorisation left to right. First, nature draws the hyperparameters \(\mu\) and \(\tau\) from their hyperpriors. Then, for each group, nature draws a group-specific parameter \(\theta_i\) from the group-level distribution governed by those hyperparameters. Finally, for each observation within each group, nature draws the data \(y_{ij}\) from the likelihood, which depends only on its group parameter \(\theta_i\).
The crucial structural feature is that the groups are linked only through the hyperparameters. Conditional on \(\mu\) and \(\tau\), the group parameters \(\theta_1, \ldots, \theta_J\) are independent. But marginally — before conditioning on \(\mu\) and \(\tau\) — they are dependent, because they share a common source of variation. This marginal dependence is what enables borrowing of strength: the data from group \(i\) inform the hyperparameters, which in turn inform the estimate for group \(k\).
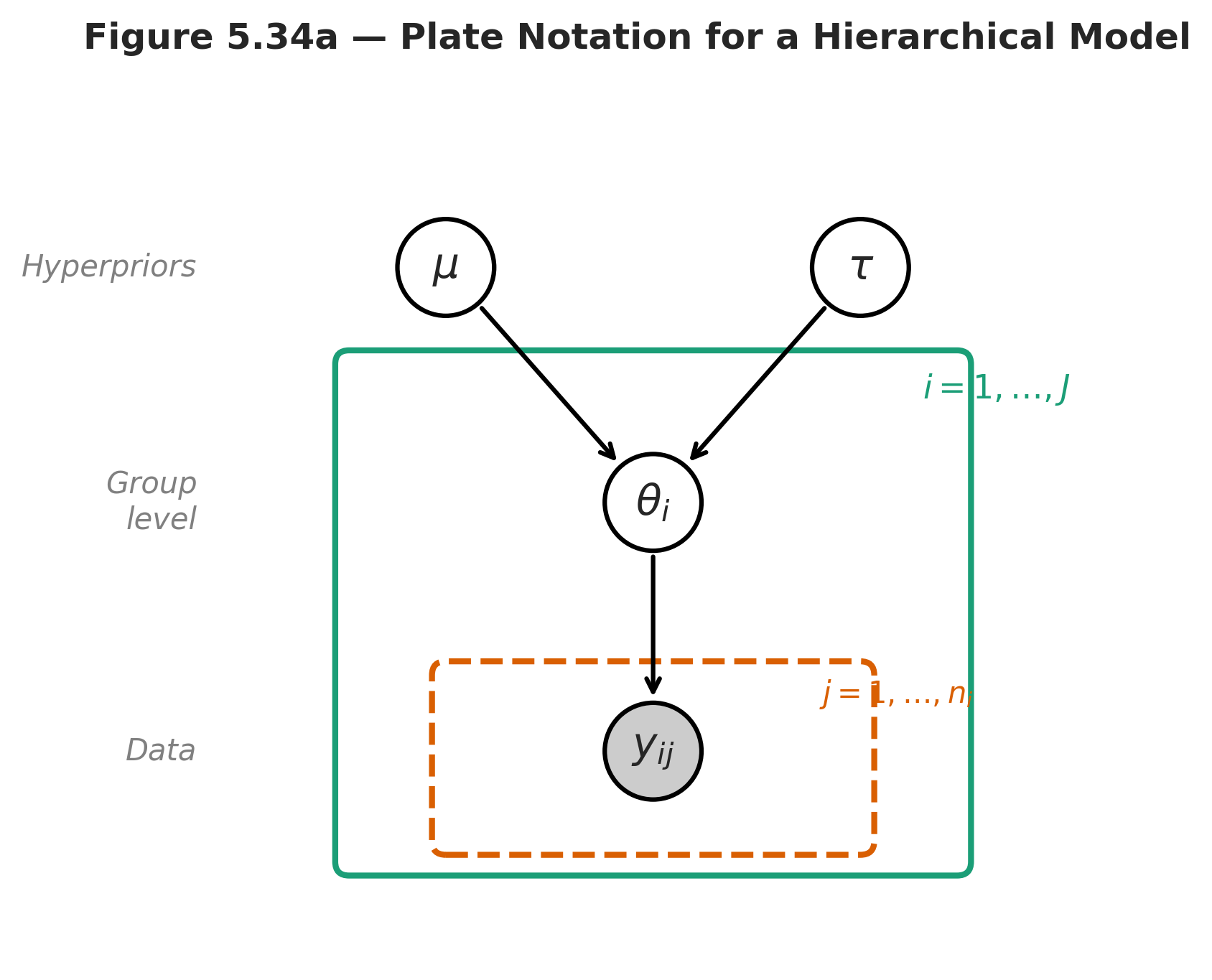
Fig. 205 Figure 5.34 — Plate notation for a hierarchical model. Shaded nodes are observed, unshaded nodes are latent. The outer plate indexes groups \(i = 1, \ldots, J\); the inner plate indexes observations \(j = 1, \ldots, n_i\) within each group.
Exchangeability
The group-level assumption \(\theta_i \mid \mu, \tau \sim p(\theta_i \mid \mu, \tau)\) for all \(i\) is a statement of exchangeability: before looking at the data, we have no reason to believe that any one group is systematically different from any other. The order of the group labels does not matter — relabelling “School A” as “School C” does not change the model.
Exchangeability is not the same as independence. The \(\theta_i\) are exchangeable but dependent (through the shared hyperparameters). An analogy: imagine drawing coloured marbles from an urn. Before any draw, any marble is equally likely. But once you draw a red marble, you update your beliefs about the urn’s composition, which changes the probabilities for the next draw. The marbles are exchangeable but not independent.
Exchangeability is the key modeling assumption of the hierarchical framework, and it should be checked. If there is a known structural distinction between groups — for example, if some schools are private and some are public, and you have reason to believe this matters — that distinction should be encoded explicitly in the model (e.g., as a covariate at the group level), not assumed away under exchangeability.
The Shrinkage Formula
The mechanics of partial pooling can be made precise for the Normal-Normal hierarchy. Suppose the group-level model is \(\theta_i \sim \mathcal{N}(\mu, \tau^2)\) and the data model is \(\bar{y}_i \mid \theta_i \sim \mathcal{N}(\theta_i, \sigma_i^2)\), where \(\bar{y}_i\) is the sample mean for group \(i\) and \(\sigma_i^2\) is its known variance (this is the Eight Schools setup). Then the posterior mean for \(\theta_i\), conditional on \(\mu\) and \(\tau\), is:
where the shrinkage factor \(B_i\) is:
This is a weighted average of the group’s own data \(\bar{y}_i\) and the grand mean \(\mu\). The weight given to the grand mean is \(B_i\), which depends on the ratio of within-group noise \(\sigma_i^2\) to between-group variation \(\tau^2\). Three limiting cases make the behaviour transparent:
When \(\sigma_i^2 \gg \tau^2\) (noisy group, similar groups): \(B_i \to 1\), and the estimate is pulled almost entirely to the grand mean. The group’s own data are so noisy relative to the between-group spread that they carry little information.
When \(\sigma_i^2 \ll \tau^2\) (precise group, diverse groups): \(B_i \to 0\), and the estimate is determined almost entirely by the group’s own data. The within-group precision is high enough to overwhelm the pull toward \(\mu\).
When \(\tau \to 0\) (all groups identical): \(B_i \to 1\) for every group, and partial pooling becomes complete pooling.
In the Eight Schools data, School E has \(\sigma_E = 9\) (one of the smallest standard errors), so its shrinkage factor is relatively low — its estimate is determined mainly by its own data. School H has \(\sigma_H = 18\) (the largest standard error), so its shrinkage factor is high — it is pulled more strongly toward the grand mean. The hierarchical model adapts the degree of pooling to each group’s information content automatically.
Example 💡 Shrinkage in Action
Given: Eight Schools data with rounded working values \(\mu \approx 8\) and \(\tau \approx 6\) (the non-centred model of §5.8.3 gives posterior means of roughly 7.4 and 4.8).
Compute shrinkage factors for Schools E and H:
Python verification:
mu_hat, tau_hat = 8.0, 6.0
for school, y_i, sig_i in [('E', -1, 9), ('H', 12, 18)]:
B_i = sig_i**2 / (sig_i**2 + tau_hat**2)
theta_hat = (1 - B_i) * y_i + B_i * mu_hat
print(f"School {school}: B = {B_i:.2f}, "
f"shrunk estimate = {theta_hat:.1f} "
f"(raw = {y_i})")
School E: B = 0.69, shrunk estimate = 5.2 (raw = -1)
School H: B = 0.90, shrunk estimate = 8.4 (raw = 12)
Result: School E’s negative raw effect (\(-1\)) is pulled substantially toward the grand mean (8), yielding a shrunk estimate of 5.2, exactly as the shrinkage formula (173) predicts. School H’s raw effect (12) is pulled almost all the way to the grand mean because its standard error is so large. Both estimates are more moderate than the raw data — this is shrinkage in action.
Borrowing Strength: The Information Flow
The phrase “borrowing strength” describes how hierarchical models use data from all groups to improve estimates for each individual group. The mechanism is indirect: the data from group \(i\) do not directly enter the likelihood for group \(k\). Instead, the data from group \(i\) inform the hyperparameters \(\mu\) and \(\tau\), and those hyperparameters in turn inform the prior for group \(k\)’s parameter \(\theta_k\).
This information flow has a concrete consequence. Consider a new school — School I — that was not in the original study. Under no pooling, we have no estimate for School I because it contributed no data. Under partial pooling, we can predict School I’s effect by drawing from the population distribution:
Using posterior samples \((\mu^{(s)}, \tau^{(s)})\) for \(s = 1, \ldots, S\), we obtain a predictive distribution for \(\theta_{\text{new}}\) that incorporates both the estimated population mean and the estimated between-group variability. This is the hierarchical model’s built-in mechanism for generalisation — making predictions for units not in the training data.
Worked Example 1: Eight Schools (Normal Likelihood)
The Eight Schools dataset is the canonical hierarchical example in Bayesian statistics, first analysed by [Rubin1981] and extensively discussed by [GelmanBDA3]. Eight US high schools each ran a short SAT coaching programme. Each school reported an estimated effect size \(y_i\) (improvement in SAT score) and its standard error \(\sigma_i\). The question: did the programme work, and did it work equally across schools?
The Data
School |
Effect \(y_i\) |
Std Error \(\sigma_i\) |
|---|---|---|
A |
28 |
15 |
B |
8 |
10 |
C |
\(-3\) |
16 |
D |
7 |
11 |
E |
\(-1\) |
9 |
F |
1 |
11 |
G |
18 |
10 |
H |
12 |
18 |
The standard errors \(\sigma_i\) are treated as fixed known quantities — they come from the original experimental design, not from the model. This is a known-variance Normal model, which simplifies the hierarchy.
The Hierarchical Model
The three-level structure specialised to this problem is:
The hyperprior \(\mu \sim \mathcal{N}(0, 20)\) centres the grand mean at zero (no prior assumption that coaching helps or hurts) with a standard deviation of 20 SAT points — generous enough to accommodate any plausible programme effect. The hyperprior \(\tau \sim \text{HalfNormal}(10)\) allows between-school variation from near zero (all schools are the same) to roughly 20 points (substantial heterogeneity). These are weakly informative priors in the sense of Section 5.2 Prior Specification and Conjugate Analysis: they constrain the parameter space to physically plausible ranges without strongly favouring any particular value.
The Centred Parameterisation (and Why It Fails)
The natural way to write this model in PyMC follows the mathematical specification directly:
import numpy as np
import pymc as pm
import arviz as az
# Eight Schools data
y_obs = np.array([28, 8, -3, 7, -1, 1, 18, 12], dtype=float)
sigma_i = np.array([15, 10, 16, 11, 9, 11, 10, 18], dtype=float)
J = len(y_obs)
with pm.Model() as centred:
mu = pm.Normal('mu', mu=0, sigma=20)
tau = pm.HalfNormal('tau', sigma=10)
theta = pm.Normal('theta', mu=mu, sigma=tau, shape=J)
y = pm.Normal('y', mu=theta, sigma=sigma_i, observed=y_obs)
idata_c = pm.sample(draws=2000, tune=1000, chains=4,
target_accept=0.90, random_seed=42)
This is called the centred parameterisation because each \(\theta_i\) is centred directly on \(\mu\) with scale \(\tau\). Run this code and PyMC will report divergent transitions — the sampler’s warning that it encountered posterior geometry it could not navigate reliably. Divergences are not a nuisance to be ignored; they indicate that the reported posterior samples may be biased (discussed in Section 5.5 MCMC Algorithms: Metropolis-Hastings and Gibbs Sampling).
Neal’s Funnel
The divergences arise from a geometric pathology first described by [BetancourtGirolami2015] and named Neal’s funnel. The issue is the interaction between \(\tau\) and the \(\theta_i\).
When \(\tau\) is large — say \(\tau = 10\) — the school effects \(\theta_i\) can spread freely across a wide range of values. The posterior geometry in this region is smooth and NUTS navigates it easily.
When \(\tau\) is small — say \(\tau \approx 0.5\) — the model is saying that all schools have nearly the same effect. Consequently, every \(\theta_i\) must cluster tightly around \(\mu\), leaving almost no room to vary. The posterior geometry in this region is extremely narrow: a thin spike in \(J\)-dimensional \(\theta\)-space, constrained to a tiny neighbourhood of \(\mu\).
Now imagine the sampler trying to move through both regions. At the wide top of the funnel (large \(\tau\)), NUTS selects a step size \(\epsilon\) that efficiently covers the broad posterior. But when the sampler drifts toward the narrow stem (small \(\tau\)), that same step size is far too large: each leapfrog step overshoots the narrow constraint, the Hamiltonian diverges, and the proposal is rejected. The sampler gets stuck in the wide region and rarely visits the stem.
An analogy: imagine trying to sample uniformly from a wine glass shape. Steps sized for the wide rim will crash through the narrow stem; steps sized for the narrow stem will take forever to explore the rim. No single step size works for both regions.
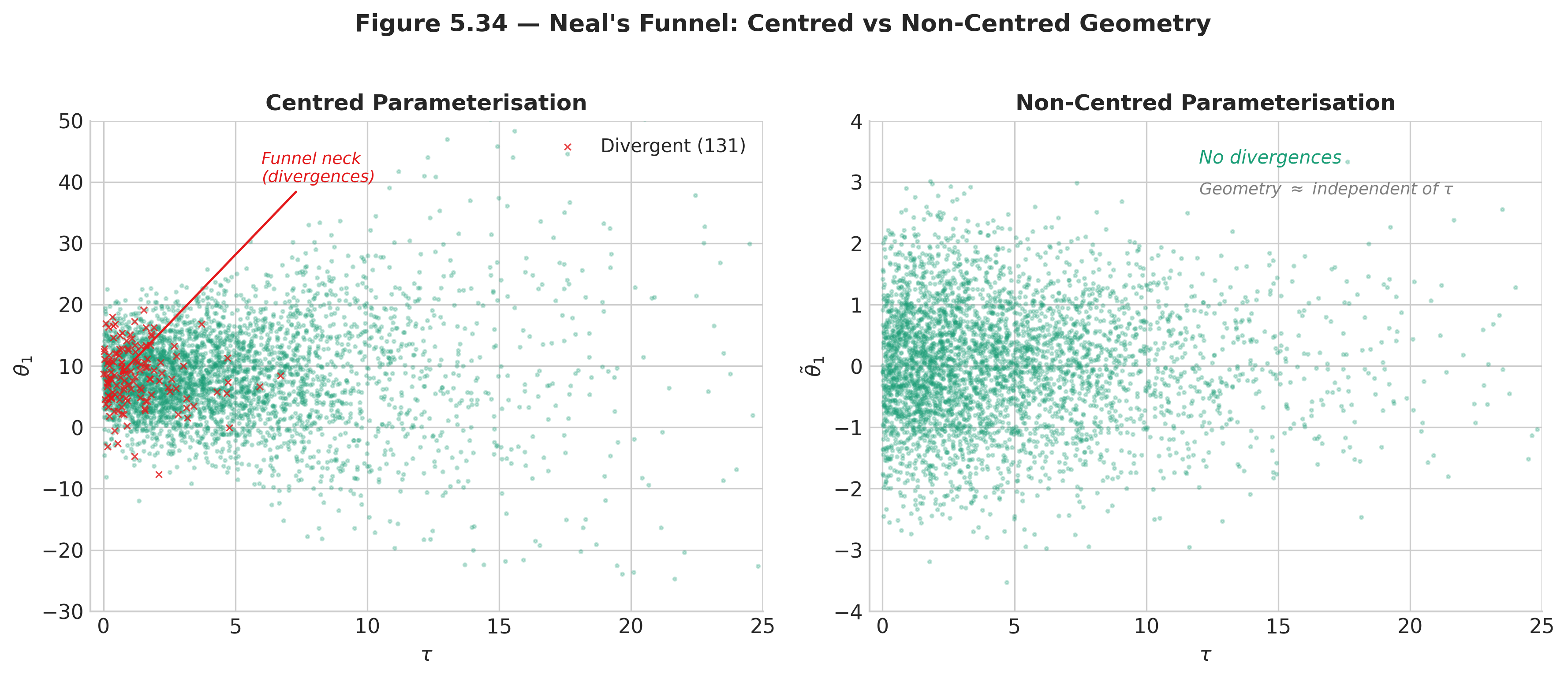
Fig. 206 Figure 5.35 — Neal’s funnel. Left: the centred parameterisation produces a funnel-shaped joint posterior in \((\tau, \theta_1)\) space; red points mark divergent transitions concentrated at the funnel’s neck. Right: the non-centred parameterisation transforms the geometry into a cylinder; divergences vanish.
Common Pitfall ⚠️
Divergent transitions are not a tuning problem. Increasing target_accept from 0.90 to
0.95 or 0.99 can reduce the number of divergences by forcing a smaller step size, but it does
not eliminate the geometric pathology. If divergences appear in a hierarchical model, the first
diagnosis should be a reparameterisation, not a tuning adjustment. Ignoring divergences risks
biased posterior estimates — typically with the between-group variance \(\tau\)
underestimated because the sampler fails to explore the funnel’s stem.
The Non-Centred Parameterisation
The solution is a change of variables that decouples the group parameters from \(\tau\). Instead of writing \(\theta_i \sim \mathcal{N}(\mu, \tau)\), we write:
The auxiliary variables \(\tilde{\theta}_i\) are standard Normal regardless of \(\tau\). This is a deterministic transformation: the joint distribution of \((\theta_1, \ldots, \theta_J)\) is unchanged, but the geometry of the sampled parameters \((\tilde{\theta}_1, \ldots, \tilde{\theta}_J)\) is now approximately independent of \(\tau\). The funnel is replaced by a cylinder that NUTS traverses without difficulty.
with pm.Model() as noncentred:
mu = pm.Normal('mu', mu=0, sigma=20)
tau = pm.HalfNormal('tau', sigma=10)
theta_raw = pm.Normal('theta_raw', mu=0, sigma=1, shape=J)
theta = pm.Deterministic('theta', mu + tau * theta_raw)
y = pm.Normal('y', mu=theta, sigma=sigma_i, observed=y_obs)
idata_nc = pm.sample(draws=2000, tune=1000, chains=4,
target_accept=0.90, random_seed=42,
idata_kwargs={"log_likelihood": True})
The only change is in how theta is constructed: a standard Normal theta_raw is sampled
first, then theta is built deterministically. Mathematically, \(\theta_i = \mu +
\tau \cdot \tilde{\theta}_i\) with \(\tilde{\theta}_i \sim \mathcal{N}(0,1)\) produces
the same distribution as \(\theta_i \sim \mathcal{N}(\mu, \tau)\). Computationally, the
difference is decisive.
After sampling:
print(az.summary(idata_nc, var_names=['mu', 'tau', 'theta'],
hdi_prob=0.89))
mean sd hdi_5.5% hdi_94.5% r_hat ess_bulk ess_tail
mu 7.39 4.49 0.46 14.63 1.00 6268.0 4290.0
tau 4.79 3.76 0.00 9.71 1.00 4368.0 3464.0
theta[0] 9.72 6.90 -0.91 19.97 1.00 7153.0 6535.0
theta[1] 7.43 5.78 -1.06 17.07 1.00 8471.0 6410.0
theta[2] 6.32 6.64 -3.80 16.53 1.00 8010.0 6198.0
theta[3] 7.38 5.73 -1.87 16.18 1.00 8476.0 6342.0
theta[4] 5.55 5.76 -3.60 14.72 1.00 8649.0 6199.0
theta[5] 6.37 5.90 -2.69 15.66 1.00 9389.0 7200.0
theta[6] 9.51 5.95 -0.16 18.67 1.00 8428.0 6542.0
theta[7] 7.78 6.59 -2.13 18.44 1.00 7874.0 6043.0
All \(\hat{R}\) values are at 1.00, and effective sample sizes are in the thousands — the non-centred reparameterisation (175) has eliminated the sampling pathology entirely.
Forest Plot
The forest plot is the standard visualisation for hierarchical model estimates. It shows each group’s posterior distribution as a credible interval with a point estimate, arranged vertically for comparison:
school_names = ['A', 'B', 'C', 'D', 'E', 'F', 'G', 'H']
labeller = az.labels.MapLabeller(
var_name_map={f'theta[{i}]': school_names[i] for i in range(J)}
)
az.plot_forest(idata_nc, var_names=['theta'], combined=True,
hdi_prob=0.89, r_hat=True, labeller=labeller)
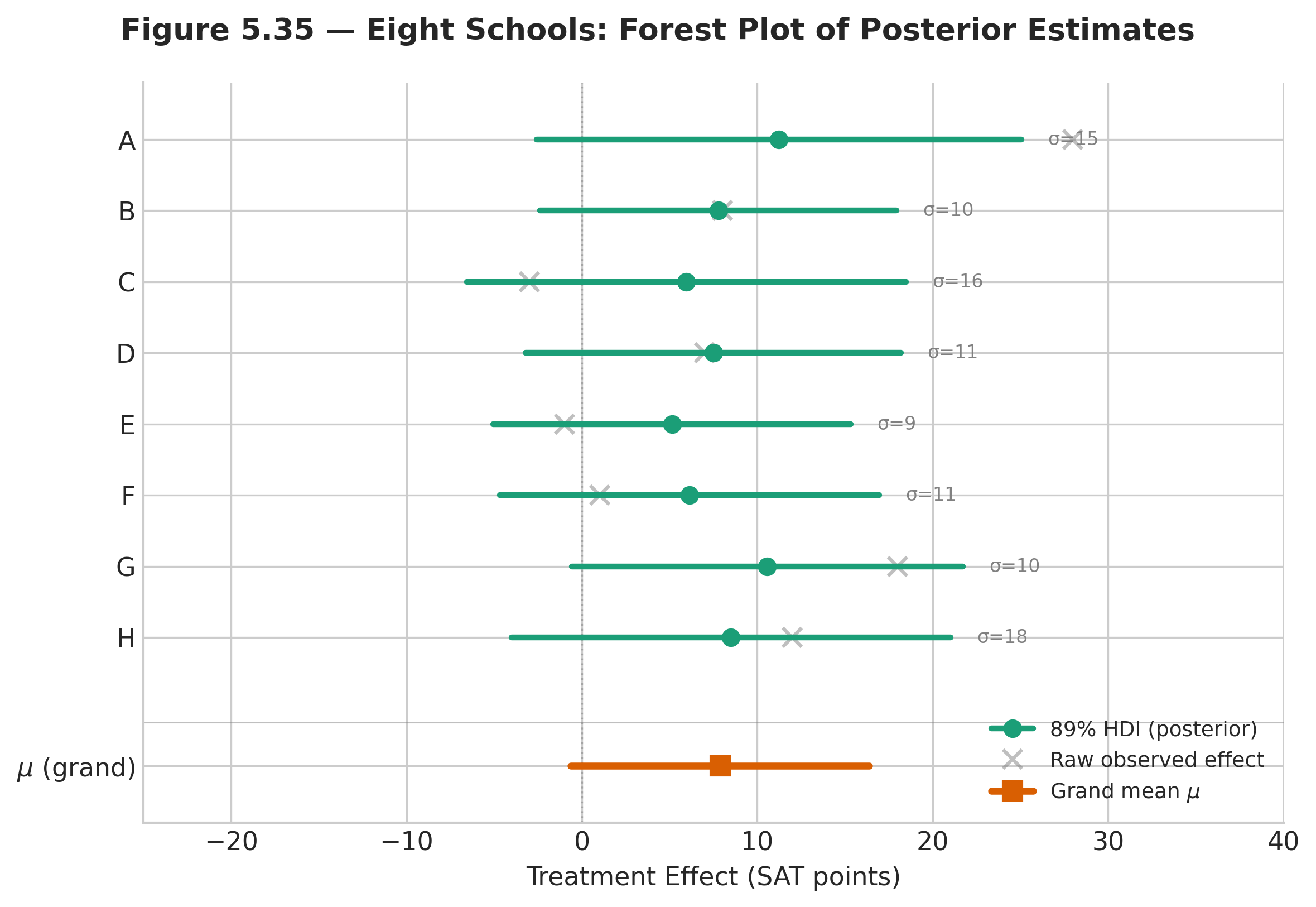
Fig. 207 Figure 5.36 — Forest plot of Eight Schools posterior estimates. Horizontal bars are 89% HDI intervals; dots are posterior means. All schools are shrunk toward the grand mean \(\mu \approx 8\). Schools with larger standard errors (A, C, H) are shrunk more.
Key observations to read from the forest plot:
Schools A and G have the largest observed effects (28 and 18), but their posterior means are shrunk to approximately 9.7 and 9.5. The data alone suggest large effects; the hierarchical model tempers this by noting that the other six schools show much smaller effects, so the extreme values are partly noise.
Schools C and E have negative point estimates in the raw data (\(-3\) and \(-1\)), but their posterior intervals cross zero comfortably. We cannot confidently claim that the programme hurt these schools.
School B has a moderate observed effect (8) with a relatively small standard error (10), so it is shrunk less than schools with wider standard errors.
The width of each interval reflects both the within-school standard error \(\sigma_i\) and the between-school variance \(\tau\). Schools with larger \(\sigma_i\) have wider intervals — they contribute less information and are therefore pulled more toward \(\mu\).
Diagnosing the Centred vs. Non-Centred Models
The diagnostic comparison between the two parameterisations is instructive. The az.plot_pair
function reveals the geometry directly:
# Centred model diagnostics
az.plot_pair(idata_c, var_names=['tau', 'theta'],
coords={'theta_dim_0': [0]},
divergences=True, kind='scatter',
figsize=(6, 6))
This produces the left panel of Figure 5.35: a scatter plot of \((\tau, \theta_0)\) with divergent transitions marked in red. The funnel shape is unmistakable — samples cluster at large \(\tau\) and divergences concentrate where \(\tau\) is small and \(\theta_0\) is forced near \(\mu\).
Running the same diagnostic on the non-centred model shows no funnel and no divergences:
# Non-centred model diagnostics
az.plot_pair(idata_nc, var_names=['tau', 'theta'],
coords={'theta_dim_0': [0]},
divergences=True, kind='scatter',
figsize=(6, 6))
A quantitative comparison confirms the visual impression:
# Count divergences
divergences_c = idata_c.sample_stats['diverging'].values.sum()
divergences_nc = idata_nc.sample_stats['diverging'].values.sum()
print(f"Centred model divergences: {divergences_c}")
print(f"Non-centred model divergences: {divergences_nc}")
# Compare ESS for tau
ess_c = az.ess(idata_c, var_names=['tau'])['tau'].values
ess_nc = az.ess(idata_nc, var_names=['tau'])['tau'].values
print(f"\nESS for tau (centred): {ess_c:.0f}")
print(f"ESS for tau (non-centred): {ess_nc:.0f}")
Centred model divergences: 332
Non-centred model divergences: 0
ESS for tau (centred): 296
ESS for tau (non-centred): 4368
The centred model produces 332 divergent transitions and an ESS for \(\tau\) of only 296 — less than one-fourteenth of the non-centred model’s ESS. The non-centred model has zero divergences and nearly fifteen times the effective sample size for the critical between-group variance parameter. This is not a marginal improvement; it is the difference between a reliable posterior and one that cannot be trusted.
Posterior Predictive Check
As a final diagnostic, we verify that the hierarchical model can reproduce the observed data. The posterior predictive check draws simulated datasets \(y^{\text{rep}}\) from the posterior and compares them to the observed data:
with noncentred:
pm.sample_posterior_predictive(idata_nc, extend_inferencedata=True,
random_seed=42)
# Compare observed vs. replicated school effects
y_rep = idata_nc.posterior_predictive['y']
print("Observed effects: ", y_obs)
print("Replicated means: ",
y_rep.mean(dim=['chain', 'draw']).values.round(1))
print("Replicated std: ",
y_rep.std(dim=['chain', 'draw']).values.round(1))
Observed effects: [28. 8. -3. 7. -1. 1. 18. 12.]
Replicated means: [9.8 7.2 6.3 7.5 5.5 6.3 9.4 7.9]
Replicated std: [16.5 11.6 17.3 12.4 10.7 12.6 11.6 19.1]
The replicated means are shrunk versions of the observed effects (as expected — the model pulls toward the grand mean), and the replicated standard deviations match the known standard errors closely. The model is generating data that are statistically compatible with the observations.
Algorithm: Hierarchical Model Fitting via Non-Centred NUTS
Input: Data y (grouped), group sizes n_i, hyperprior specifications
Output: Posterior samples for (mu, tau, theta_1, ..., theta_J)
1. Reparameterise: for each group i, set theta_tilde_i ~ Normal(0,1)
and theta_i = mu + tau * theta_tilde_i (deterministic)
2. Construct log-posterior:
log p = log p(mu) + log p(tau)
+ sum_i log Normal(theta_tilde_i | 0, 1)
+ sum_i sum_j log p(y_ij | theta_i)
3. Compute gradient via automatic differentiation
4. Run NUTS (target_accept = 0.90) with 4 chains:
a. Tune step size epsilon via dual averaging (1000 iterations)
b. Draw S posterior samples per chain (2000 iterations)
5. Diagnose: check R-hat < 1.01, ESS > 400, divergences = 0
6. Transform back: compute theta_i = mu + tau * theta_tilde_i
for each posterior sample
7. Return InferenceData with posterior, posterior_predictive,
log_likelihood groups
Computational Complexity: Each NUTS iteration requires \(O(L \cdot (J + N))\) gradient evaluations, where \(L\) is the leapfrog trajectory length (typically 5–20 steps), \(J\) is the number of groups, and \(N\) is the total number of observations. Total cost for \(S\) draws across \(C\) chains is \(O(C \cdot S \cdot L \cdot (J + N))\). For the Eight Schools problem (\(J = 8\), \(N = 8\)), each iteration is trivially fast. For large datasets (\(N > 10{,}000\)), the per-iteration cost is dominated by the likelihood gradient over observations.
Worked Example 2: NBA Team Scoring – Does Shrinkage Pay Off?
The Eight Schools example shows how partial pooling works, but its eight effects are themselves noisy estimates with no ground truth to check them against. This second Normal example uses a dataset with a built-in answer key, so we can ask the practical question directly: does shrinkage actually predict better? It is the basketball cousin of Efron and Morris’s celebrated baseball demonstration (Efron and Morris, 1975), and it closes the loop on the chapter’s free-throw thread – regression to the mean as a prior, now across thirty teams.
The data. For each of the \(J = 30\) NBA teams we record its mean points per game over
the first \(\approx 10\) games (Y_bar, a noisy early-season estimate, with sample
standard deviation sample_sd) and – crucially – its mean over the remaining games
(average_remaining_games), which we hold out as the truth.
The model is exactly the Normal hierarchy of (174): each team’s early mean \(\bar{y}_j \sim \mathcal{N}(\theta_j,\, V_j)\) with sampling variance \(V_j = s_j^2 / n_j\), and the team means \(\theta_j \sim \mathcal{N}(\mu, \tau^2)\). We estimate \(\mu\) and \(\tau\) from the 30 teams (empirical Bayes) and read off each posterior mean through the shrinkage factor \(B_j = V_j / (V_j + \tau^2)\) – the closed form behind this section’s shrinkage formula. A full PyMC fit of the same hierarchy gives the same estimates; the closed form just keeps the demonstration exact.
import numpy as np
import pandas as pd
url = ("https://pqyjaywwccbnqpwgeiuv.supabase.co/storage/v1/object/"
"public/STAT%20418%20Images/Data/Chapter5/NBA_data.csv")
nba = pd.read_csv(url)
y = nba["Y_bar"].to_numpy() # early-season mean points per game
n = nba["number_games_played"].to_numpy()
V = nba["sample_sd"].to_numpy() ** 2 / n # sampling variance of each early mean
target = nba["average_remaining_games"].to_numpy() # held-out rest-of-season truth
# Empirical Bayes: estimate the between-team mean (mu) and SD (tau)
tau2 = np.var(y, ddof=1)
for _ in range(200):
w = 1.0 / (V + tau2)
mu = np.sum(w * y) / np.sum(w)
tau2 = max(1e-6, np.sum(w**2 * ((y - mu)**2 - V)) / np.sum(w**2))
B = V / (V + tau2) # shrinkage factor toward mu
shrunk = mu + (1 - B) * (y - mu) # hierarchical (posterior-mean) estimate
sse_raw = np.sum((y - target) ** 2)
sse_shrunk = np.sum((shrunk - target) ** 2)
print(f"{len(nba)} teams; league mean = {y.mean():.1f} pts; "
f"mu = {mu:.1f}, tau = {np.sqrt(tau2):.2f}, mean shrinkage B = {B.mean():.2f}")
print(f"predicting rest-of-season: raw SSE = {sse_raw:.0f}, shrunk SSE = {sse_shrunk:.0f} "
f"-> {100*(1 - sse_shrunk/sse_raw):.0f}% better")
for t in ["Miami", "Utah"]:
i = list(nba["team"]).index(t)
print(f" {t:7s}: early {y[i]:.1f} -> shrunk {shrunk[i]:.1f} (actual rest {target[i]:.1f})")
Output:
30 teams; league mean = 98.5 pts; mu = 98.7, tau = 3.77, mean shrinkage B = 0.42
predicting rest-of-season: raw SSE = 540, shrunk SSE = 332 -> 38% better
Miami : early 89.3 -> shrunk 95.5 (actual rest 95.3)
Utah : early 107.2 -> shrunk 104.2 (actual rest 100.7)
Two things stand out. First, the league’s teams are genuinely similar – \(\tau \approx 3.8\) points of spread around a mean of \(\mu \approx 98.7\) – so the average team’s early estimate is pulled 42% of the way toward the league mean. Second, and this is the payoff: those shrunk estimates predict each team’s rest-of-season scoring with 38% less squared error than the raw early means. Borrowing strength across teams beats taking any one team’s hot or cold start at face value.
The mechanism is vivid in the two extreme teams. Miami’s cold \(89.3\)-point start is regressed up to \(95.5\) – almost exactly its eventual \(95.3\); Utah’s hot \(107.2\) start is pulled down to \(104.2\), far closer to its eventual \(100.7\) than the raw number was. Early-season extremes are mostly luck, and a hierarchical prior – estimated from the league rather than assumed – knows it. This is the same regression-to-the- mean logic that justified putting an informative prior on Stephen Curry’s free-throw rate back in Section 5.1, now operating on thirty teams at once: the data tell us how much to trust each group, and the model shrinks accordingly.
Worked Example 3: Dirichlet-Multinomial (Categorical Likelihood)
The previous two examples use a Normal likelihood — the most common setting for hierarchical models. But the hierarchical design pattern is not specific to any likelihood family. This third example uses a categorical likelihood to demonstrate that the three-level structure (hyperprior → group parameters → observations) applies equally to counts, proportions, rates, and any other data type.
Setup: Survey Responses Across Regions
A political survey asks respondents in \(R = 6\) regions to choose among \(K = 4\) policy positions: Strongly Agree, Agree, Disagree, Strongly Disagree. Each region has a different number of respondents (between 35 and 120). We want to estimate the true population proportions \((\pi_1, \pi_2, \pi_3, \pi_4)\) for each region while acknowledging that regions share a common national pattern.
Why Dirichlet-Multinomial?
When the outcome is a probability vector \(\boldsymbol{\pi} = (\pi_1, \ldots, \pi_K)\) that must sum to one, the natural prior is the Dirichlet distribution — the multivariate generalisation of the Beta distribution (developed in Section 5.2 Prior Specification and Conjugate Analysis). Just as the Beta-Binomial pair is conjugate for binary outcomes, the Dirichlet-Multinomial pair is conjugate for categorical outcomes with \(K \geq 2\) categories.
The Dirichlet distribution \(\text{Dir}(\alpha_1, \ldots, \alpha_K)\) is parameterised by a concentration vector \(\boldsymbol{\alpha} = (\alpha_1, \ldots, \alpha_K)\) with all \(\alpha_k > 0\). Its density is:
where \(\Gamma(\cdot)\) is the gamma function (a continuous extension of the factorial). When all \(\alpha_k = 1\), the Dirichlet reduces to the uniform distribution on the simplex. When all \(\alpha_k > 1\), it concentrates probability around the mean \((\alpha_1/\alpha_0, \ldots, \alpha_K/\alpha_0)\).
Hierarchical Structure
The hierarchy for the survey data is:
The hyperparameter \(\alpha\) controls how tightly the regional proportions cluster around the national baseline \(\boldsymbol{\pi}_0\). When \(\alpha\) is large, all regions look alike. When \(\alpha\) is small, regions can differ substantially. The product \(\alpha \cdot \boldsymbol{\pi}_0\) means that the Dirichlet concentration in each category is proportional to the national proportion — categories that are common nationally are common regionally, but the degree of agreement is governed by \(\alpha\).
Synthetic Data and PyMC Model
import numpy as np
import pymc as pm
import arviz as az
rng = np.random.default_rng(2025)
K = 4 # policy positions
R = 6 # regions
# True national proportions (unknown to the model)
pi_true = np.array([0.25, 0.35, 0.25, 0.15])
# Region-level sample sizes
n_r = np.array([45, 120, 60, 80, 35, 95])
# Generate synthetic observed counts
y_obs = np.zeros((R, K), dtype=int)
for r in range(R):
pi_r = rng.dirichlet(8.0 * pi_true) # alpha ~ 8
y_obs[r] = rng.multinomial(n_r[r], pi_r)
print("Observed counts:")
print(y_obs)
Observed counts:
[[ 3 35 1 6]
[18 26 11 65]
[ 3 31 18 8]
[21 32 24 3]
[10 9 7 9]
[ 7 30 20 38]]
with pm.Model() as dir_model:
# Hyperpriors
alpha = pm.Exponential('alpha', lam=1.0)
pi0 = pm.Dirichlet('pi0', a=np.ones(K)) # national baseline
# Region-level proportions — partial pooling across regions
pi_r = pm.Dirichlet('pi_r', a=alpha * pi0, shape=(R, K))
# Likelihood
counts = pm.Multinomial('counts', n=n_r, p=pi_r, observed=y_obs)
idata_dir = pm.sample(draws=2000, tune=1000, chains=4,
target_accept=0.90, random_seed=42,
idata_kwargs={"log_likelihood": True})
print(az.summary(idata_dir, var_names=['alpha', 'pi0'],
hdi_prob=0.89))
mean sd hdi_5.5% hdi_94.5% r_hat ess_bulk ess_tail
alpha 4.87 1.46 2.64 7.09 1.00 12254.0 6416.0
pi0[0] 0.19 0.06 0.09 0.27 1.00 11173.0 6599.0
pi0[1] 0.37 0.08 0.25 0.49 1.00 10945.0 5515.0
pi0[2] 0.21 0.06 0.12 0.30 1.00 9897.0 5648.0
pi0[3] 0.24 0.06 0.14 0.34 1.00 9757.0 6003.0
Interpreting the Results
The posterior for \(\boldsymbol{\pi}_0\) is broadly consistent with the true national proportions: the posterior means (0.19, 0.37, 0.21, 0.24) track the generating values (0.25, 0.35, 0.25, 0.15), though one atypical region (region 2, where 65 of 120 respondents chose Strongly Disagree) drags the rarest category upward. The posterior for \(\alpha\) (mean \(\approx 5\)) indicates only moderate agreement across regions — the regions share a common national pattern but differ substantially.
Comparing the region-level posteriors reveals partial pooling in action:
print("\nSmallest region (r=5, n=35):")
print(az.summary(idata_dir, var_names=['pi_r'],
filter_vars='like', coords={'pi_r_dim_0': [4]},
hdi_prob=0.89))
print("\nLargest region (r=2, n=120):")
print(az.summary(idata_dir, var_names=['pi_r'],
filter_vars='like', coords={'pi_r_dim_0': [1]},
hdi_prob=0.89))
Region 5 (\(n = 35\)): the smallest region has the widest credible intervals and is pulled most strongly toward the national baseline \(\boldsymbol{\pi}_0\).
Region 2 (\(n = 120\)): the largest region has narrow intervals that are determined primarily by its own data, with minimal shrinkage toward the national baseline.
This is the same shrinkage pattern as Eight Schools: sparse groups borrow more strength from the overall pattern; data-rich groups stand largely on their own.
To make the comparison concrete, fit the no-pooling alternative — a separate, independent Dirichlet model for each region — and compare the interval widths for the smallest region:
# No-pooling comparison for Region 5 (n=35)
from scipy.stats import dirichlet as sp_dirichlet
# No-pooling: posterior is Dir(1 + y_r) for each region independently
alpha_r5_no_pool = 1.0 + y_obs[4] # shape (4,)
pi_r5_samples_np = rng.dirichlet(alpha_r5_no_pool, size=8000)
# Hierarchical: extract Region 5 posterior samples
pi_r5_samples_hier = (idata_dir.posterior['pi_r']
.sel(pi_r_dim_0=4)
.values.reshape(-1, K))
# Compare 89% HDI widths
for k, label in enumerate(['SA', 'A', 'D', 'SD']):
hdi_np = np.percentile(pi_r5_samples_np[:, k], [5.5, 94.5])
hdi_hier = np.percentile(pi_r5_samples_hier[:, k], [5.5, 94.5])
print(f"Category {label}: "
f"no-pool width = {hdi_np[1] - hdi_np[0]:.3f}, "
f"hierarchical width = {hdi_hier[1] - hdi_hier[0]:.3f}")
Category SA: no-pool width = 0.228, hierarchical width = 0.224
Category A: no-pool width = 0.222, hierarchical width = 0.219
Category D: no-pool width = 0.204, hierarchical width = 0.201
Category SD: no-pool width = 0.223, hierarchical width = 0.213
For every category, the hierarchical model produces narrower credible intervals than the no-pooling model for this small region, though the reduction here is modest — roughly 1–4% in interval width — because the regions in this synthetic draw are quite heterogeneous (\(\alpha \approx 5\)), so the fitted population distribution pools only weakly.
Example 💡 The Hierarchical Design Pattern
Given: Multiple groups sharing a common structure (schools with test scores, regions with survey responses, hospitals with mortality rates, species with trait measurements).
Pattern:
Key insight: The likelihood family (Normal, Multinomial, Poisson, Binomial, Gamma, …) is interchangeable. What makes a model hierarchical is not the distributional choice but the structure: group parameters are exchangeable draws from a shared distribution whose parameters are themselves uncertain.
LOO Model Comparison: Three Pooling Strategies
The qualitative argument for partial pooling — narrower intervals, adaptive shrinkage, predictions for new groups — is compelling. But how do we quantify the improvement? The LOO model comparison framework from Section 5.7 Bayesian Model Comparison provides the answer.
Setting Up the Alternatives
We fit three models to the Eight Schools data:
Complete pooling — a single effect shared by all schools:
with pm.Model() as complete_pool:
mu = pm.Normal('mu', mu=0, sigma=20)
y = pm.Normal('y', mu=mu, sigma=sigma_i, observed=y_obs)
idata_cp = pm.sample(draws=2000, tune=1000, chains=4,
target_accept=0.90, random_seed=42,
idata_kwargs={"log_likelihood": True})
No pooling — independent effects with no shared parameters:
with pm.Model() as no_pool:
theta = pm.Normal('theta', mu=0, sigma=20, shape=J)
y = pm.Normal('y', mu=theta, sigma=sigma_i, observed=y_obs)
idata_np = pm.sample(draws=2000, tune=1000, chains=4,
target_accept=0.90, random_seed=42,
idata_kwargs={"log_likelihood": True})
Partial pooling — the non-centred hierarchical model from §5.8.3 (idata_nc), already
sampled with idata_kwargs={"log_likelihood": True}.
Comparing with az.compare
comparison = az.compare(
{"partial pooling": idata_nc,
"no pooling": idata_np,
"complete pooling": idata_cp},
ic="loo"
)
print(comparison)
rank elpd_loo p_loo ... dse warning scale
complete pooling 0 -30.504267 0.629445 ... 0.000000 False log
partial pooling 1 -30.891634 1.244443 ... 0.166144 False log
no pooling 2 -33.299345 3.593968 ... 0.625318 True log
[3 rows x 9 columns]
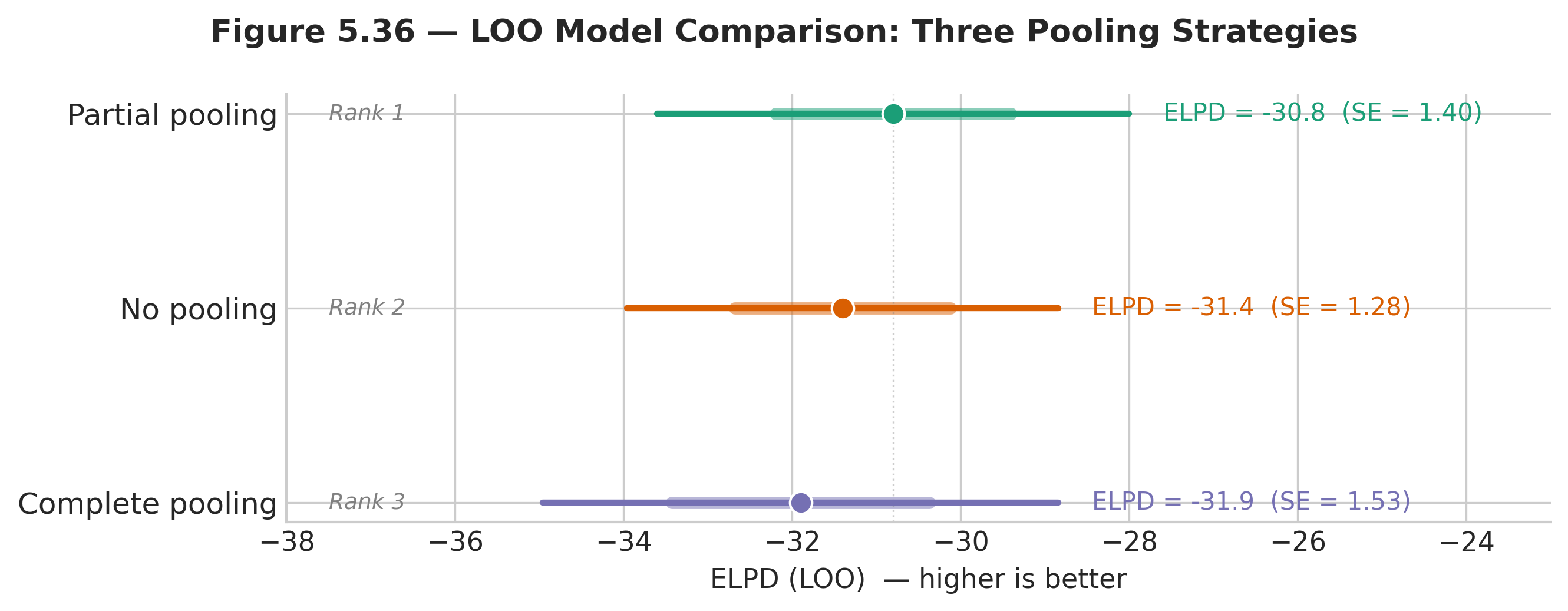
Fig. 208 Figure 5.37 — LOO comparison of three pooling strategies. ELPD (higher is better) with \(\pm 2\) standard error bars. Complete pooling ranks first with partial pooling a close second (the two are statistically indistinguishable), while no pooling trails clearly. The gap between partial and no pooling is the quantitative measure of how much hierarchical shrinkage improved out-of-sample prediction.
az.plot_compare(comparison, insample_dev=False)
Interpreting the Comparison
The ELPD differences in the Eight Schools problem are modest — all three models perform similarly because the dataset is small (\(J = 8\) schools, each summarised by a single effect estimate). This is typical: with little data, it is hard to discriminate models decisively.
In this run complete pooling edges out partial pooling, and the ordering is informative:
Complete pooling ≈ partial pooling: the ELPD difference (0.39, with
dse= 0.17) is too small to be meaningful. The Eight Schools data are compatible with \(\tau\) near zero, so the hierarchical model — which can shrink all the way to complete pooling — predicts essentially as well as the one-parameter model while still allowing for school-to-school variation.Both > no pooling: the no-pooling model trails by 2.8 ELPD (
dse= 0.63) and is the only model flagged with a Pareto-\(k\) warning. Estimating eight unconstrained effects from eight noisy observations overfits, and LOO penalises the overfitting.
The LOO comparison provides a principled, quantitative answer to “how much does the hierarchical structure help?” — it is the predictive benefit of partial pooling measured on the same scale used to compare any Bayesian models in Section 5.7 Bayesian Model Comparison.
Common Pitfall ⚠️
Small ELPD differences are still meaningful. With only \(J = 8\) data points (school summaries), the standard errors on the ELPD differences are large relative to the differences themselves. Do not conclude that the models are “the same” — conclude that you do not have enough data to distinguish them sharply. In practice, hierarchical models shine most when \(J\) is moderate to large (15–500 groups) and group sizes \(n_i\) are heterogeneous.
When to Use Hierarchical Models
Not every grouped dataset demands a hierarchical model. The following practical guidelines help decide when the added complexity is warranted.
Property |
Complete Pooling |
No Pooling |
Partial Pooling (Hierarchical) |
|---|---|---|---|
Parameters |
1 shared \(\theta\) |
\(J\) independent \(\theta_i\) |
\(J\) exchangeable \(\theta_i\) + hyperparameters |
Bias |
High (ignores group differences) |
None (each group estimated separately) |
Small (controlled by shrinkage) |
Variance |
Low (uses all data) |
High (uses only group data) |
Moderate (borrows strength) |
New group prediction |
Returns grand mean |
Impossible |
Draw from population distribution |
Best regime |
Groups truly identical |
Groups unrelated, large \(n_i\) |
Groups related, heterogeneous \(n_i\) |
Use a Hierarchical Model When
Data are grouped by a categorical variable. Schools, hospitals, species, experimental subjects, geographic regions, survey waves — any time the data contain a grouping factor with \(J \geq 5\) levels and the research question involves group-specific inference.
Groups have heterogeneous sample sizes. Partial pooling helps the smallest groups most. If all groups have the same (large) sample size, the no-pooling model may perform comparably, but the hierarchical model still provides a principled framework for estimating between-group variation.
You want to predict for a new group. The hierarchical model can generate predictions for a group not in the training data by drawing a new \(\theta_{\text{new}} \sim \mathcal{N}(\mu, \tau)\) from the estimated population distribution. Neither complete pooling (which does not distinguish groups) nor no pooling (which has no parameter for unseen groups) can do this.
You have repeated measurements on the same units. Longitudinal data — multiple time points per subject — are inherently hierarchical, with subjects as groups and measurements as within-group observations. This is the foundation of mixed-effects models in clinical trials, education research, and ecology.
Be Cautious When
Too few groups (\(J < 5\)). The between-group variance \(\tau\) is identified by the spread of the \(\theta_i\) values. With fewer than five groups, there is very little information to estimate \(\tau\), and the posterior for \(\tau\) is dominated by the hyperprior.
Groups are not exchangeable. If some schools are private and some are public, or some hospitals are rural and some are urban, and this distinction is scientifically important, encode it as a group-level covariate rather than assuming exchangeability:
where \(x_i\) is a group-level predictor (e.g., an indicator for private schools) and \(\eta_i\) captures residual between-group variation.
The posterior for \(\tau\) concentrates near zero. If the data indicate that all groups have essentially the same parameter value (\(\tau \approx 0\)), the hierarchical model reduces to complete pooling. The extra complexity is unnecessary, though it does no harm — the model will simply learn that the groups are the same.
Practical Considerations
Centred vs. Non-Centred: Which to Use
The choice between centred and non-centred parameterisations depends on the amount of data per group relative to the prior:
Non-centred is preferred when data per group are sparse (small \(n_i\)) or the between-group variance \(\tau\) is small. This is the Eight Schools regime and is the most common case in practice. The non-centred parameterisation should be the default for hierarchical models.
Centred is preferred when data per group are abundant (large \(n_i\)) and \(\tau\) is well-separated from zero. In this regime, the likelihood dominates the prior for each group, the funnel geometry does not arise, and the centred parameterisation can yield higher effective sample sizes because it exploits the posterior’s natural correlation structure.
When in doubt, fit both and compare ESS. If the non-centred model has no divergences and reasonable ESS, use it. The computational cost of trying both is small compared to the cost of reporting biased posteriors from a divergent centred model.
Scaling to Many Groups
Hierarchical models scale well to large \(J\). With the non-centred parameterisation, the number of sampled parameters grows linearly with \(J\) (one \(\tilde{\theta}_i\) per group), and NUTS handles hundreds of groups routinely. The computational cost per iteration is \(O(J + N)\) — one gradient evaluation per group parameter plus one per observation.
Memory can become a concern when \(J\) is very large (thousands of groups), because the posterior samples for all group parameters must be stored. In such cases, consider saving only summary statistics (posterior mean and HDI) for each group rather than the full posterior draws.
Prior Sensitivity
The hyperpriors on \(\mu\) and \(\tau\) deserve attention. The prior on \(\tau\) is especially influential because it controls the degree of pooling:
If the prior on \(\tau\) is too concentrated near zero, it forces excessive shrinkage even when the groups are genuinely different.
If the prior on \(\tau\) is too diffuse, it may cause sampling difficulties (wide funnels) or yield posteriors that are overly sensitive to the scale of \(\tau\).
HalfNormalandHalfCauchyare both reasonable default hyperpriors for \(\tau\). [Gelman2006scale] recommendsHalfCauchy(0, 25)as a weakly informative default when \(\tau\) is on the standard deviation scale.
Always check sensitivity by re-running the model with different hyperpriors and comparing the posterior for the key quantities of interest (the \(\theta_i\) values and the predictive distribution). If the posteriors change substantially, report this sensitivity.
Connection to Frequentist Mixed Models
Students familiar with mixed-effects models from courses in experimental design or biostatistics will recognise the hierarchical model as the Bayesian counterpart of the linear mixed model (LMM). In frequentist notation, the model \(y_{ij} = \mu + u_i + \varepsilon_{ij}\) with \(u_i \sim \mathcal{N}(0, \tau^2)\) and \(\varepsilon_{ij} \sim \mathcal{N}(0, \sigma^2)\) is estimated by restricted maximum likelihood (REML). The REML estimate of \(\mu_i = \mu + u_i\) exhibits the same shrinkage toward \(\mu\) that we see in the Bayesian posterior.
The key differences are:
Uncertainty in \(\tau\). The Bayesian model propagates full posterior uncertainty in the between-group variance \(\tau\). The frequentist LMM provides a point estimate \(\hat{\tau}\) and plugs it in, which can understate uncertainty — especially when \(J\) is small and \(\hat{\tau}\) is poorly estimated.
Boundary behaviour. When the true \(\tau\) is near zero, REML often produces \(\hat{\tau} = 0\) exactly (a boundary estimate), collapsing the model to complete pooling. The Bayesian model places a continuous prior on \(\tau > 0\) and reports a posterior that may concentrate near zero but does not collapse to a point mass, preserving some residual uncertainty about between-group variation.
Predictive distributions. The Bayesian posterior predictive automatically integrates over uncertainty in \(\mu\), \(\tau\), and \(\sigma\). Frequentist prediction intervals typically condition on \(\hat{\tau}\) and \(\hat{\sigma}\), underestimating predictive uncertainty.
For well-identified models with moderate to large \(J\), the two approaches yield very similar point estimates and intervals. The Bayesian advantage is most pronounced when \(J\) is small (\(< 10\)) or when \(\tau\) is near zero — precisely the regimes where frequentist inference is most fragile.
Critical Warning 🛑
Hierarchical models are not magic. Partial pooling improves estimates when the exchangeability assumption is at least approximately correct. If the groups are fundamentally different in a way not captured by the model — for example, if half the schools are coaching maths and half are coaching reading, and you pool them all — the shrinkage will pull estimates toward a meaningless grand mean and produce worse, not better, inference. Always examine whether the grouping variable defines a meaningful set of exchangeable units, and consider adding group-level covariates when substantive differences between groups are known.
Bringing It All Together
Hierarchical models are the natural endpoint of the Bayesian toolkit developed throughout this chapter. They combine the prior-to-posterior updating of Section 5.1 Foundations of Bayesian Inference with the MCMC machinery of Section 5.5 MCMC Algorithms: Metropolis-Hastings and Gibbs Sampling, the PyMC implementation patterns of Section 5.6 Probabilistic Programming with PyMC, and the model comparison methods of Section 5.7 Bayesian Model Comparison. The conceptual contribution is the recognition that group-level parameters need not be treated as fixed unknowns (the frequentist approach) or identical across groups (the pooled approach) but can be modelled as random draws from a shared population — turning the between-group variation into a quantity to be estimated rather than ignored.
The practical contribution is shrinkage: the data-driven compromise between ignoring differences and overfitting to noise. In small-sample settings — which are the norm in many applied fields — partial pooling can dramatically improve estimates for poorly observed groups without appreciably degrading estimates for well-observed groups. The Eight Schools example shows this with Normal data; the Dirichlet-Multinomial example shows that the same structure extends to any likelihood family; and the LOO comparison provides a quantitative measure of the improvement.
The non-centred parameterisation is the key computational technique: it removes the geometric pathology (Neal’s funnel) that makes naive MCMC fail on hierarchical models, and it should be the default choice for any hierarchical specification in PyMC. Learning to recognise funnel geometry — through divergent transition warnings and \((\tau, \theta_i)\) scatter plots — is an essential diagnostic skill that will serve you in any Bayesian modelling project.
A historical note: the theoretical justification for shrinkage predates hierarchical Bayes by decades. In 1956, Charles Stein proved a startling result — now known as Stein’s paradox — showing that when \(J \geq 3\) group means are estimated simultaneously, the naive “no-pooling” estimator (each group’s sample mean) is inadmissible: there exists a shrinkage estimator that has lower total mean squared error for every possible configuration of the true means [Stein1956]. The James-Stein estimator shrinks each group mean toward the grand mean, exactly as the hierarchical model does. What the Bayesian framework adds is a principled mechanism for determining how much to shrink (learned from the data via the posterior for \(\tau\)), full uncertainty quantification (credible intervals, not just point estimates), and natural extension to non-Normal likelihoods.
Looking ahead: the hierarchical models in this section use a single grouping variable (schools, regions, hospitals). Real applications often involve crossed or nested groupings — students nested within schools within districts, or products crossed with time periods and geographic markets. These extensions require additional levels in the hierarchy and additional hyperparameters, but the core ideas — exchangeability, shrinkage, partial pooling, non-centred parameterisation — carry through without modification. PyMC handles multi-level hierarchies with the same syntax used here; only the model specification block grows more complex.
Key Takeaways 📝
Core concept: Hierarchical models implement partial pooling — an adaptive compromise between treating groups as identical (complete pooling) and treating them as unrelated (no pooling). The amount of shrinkage toward the grand mean is learned from the data, not chosen by the analyst.
Computational insight: The centred parameterisation creates a funnel geometry in the joint posterior that defeats NUTS. The non-centred parameterisation \(\theta_i = \mu + \tau \cdot \tilde{\theta}_i\) replaces the funnel with a cylinder and should be the default for hierarchical models.
Practical application: Use hierarchical models when data are grouped (\(J \geq 5\) groups), especially when group sizes are unequal. The framework applies to any likelihood family — Normal, Multinomial, Poisson, Binomial, and others — making it one of the most widely applicable tools in Bayesian statistics. (LO 4: Construct and analyse Bayesian models; approximate posteriors via MCMC; assess convergence.)
Model comparison: LOO provides a quantitative measure of the predictive benefit of partial pooling. In the Eight Schools example, partial pooling predicts essentially as well as complete pooling and clearly beats no pooling, confirming that shrinkage protects against overfitting. (LO 2: Compare inference approaches and their tradeoffs.)
Try It Yourself 🖥️
Modify the Dirichlet-Multinomial example so that one region has only \(n = 10\) respondents and another has \(n = 500\). Plot the posterior for both regions’ \(\boldsymbol{\pi}_r\) and compare the interval widths. How does the imbalance affect the degree of shrinkage?
Exercises
Exercise 5.8.1: Shrinkage Arithmetic
Use the rounded working values \(\mu = 8\) and \(\tau = 6\) for the Eight Schools posterior (the non-centred run in §5.8.3 gives posterior means of roughly 7.4 and 4.8). The observed effects and standard errors are given in the data table above.
(a) Compute the shrinkage factor \(B_i = \sigma_i^2 / (\sigma_i^2 + \tau^2)\) for all eight schools. Rank the schools from most shrinkage (largest \(B_i\)) to least.
(b) Compute the shrunk estimate \(\hat{\theta}_i = (1 - B_i)\, y_i + B_i\, \mu\) for all eight schools. Compare to the posterior means reported by the non-centred model in §5.8.3. Why don’t they match exactly?
(c) School A has \(y_A = 28\), the largest observed effect. By what percentage is the raw effect reduced by shrinkage? Explain why this reduction is appropriate even though School A’s result might look large in raw form.
(d) Suppose a ninth school (School I) has \(\sigma_I = 5\) (a very precise study). Without seeing any data from School I, what would its shrinkage factor be? What does this imply about the role of measurement precision in hierarchical models?
Solution
(a) With \(\tau = 6\) (so \(\tau^2 = 36\)):
import numpy as np
y_obs = np.array([28, 8, -3, 7, -1, 1, 18, 12], dtype=float)
sigma_i = np.array([15, 10, 16, 11, 9, 11, 10, 18], dtype=float)
schools = ['A', 'B', 'C', 'D', 'E', 'F', 'G', 'H']
mu_hat, tau_hat = 8.0, 6.0
B = sigma_i**2 / (sigma_i**2 + tau_hat**2)
print("School sigma B_i Rank")
print("-" * 35)
for idx in np.argsort(-B): # descending
print(f" {schools[idx]} {sigma_i[idx]:5.0f} "
f"{B[idx]:.3f} {np.argsort(-B).tolist().index(idx)+1}")
School sigma B_i Rank
-----------------------------------
H 18 0.900 1
C 16 0.877 2
A 15 0.862 3
D 11 0.771 4
F 11 0.771 5
B 10 0.735 6
G 10 0.735 7
E 9 0.692 8
Schools with larger standard errors are shrunk more: H (0.900), C (0.877), and A (0.862) are the most aggressively pulled toward \(\mu\). School E, with the smallest \(\sigma_i = 9\), retains the most of its own data.
(b)
theta_shrunk = (1 - B) * y_obs + B * mu_hat
print("School y_obs B_i shrunk MCMC_mean")
print("-" * 48)
mcmc_means = [9.72, 7.43, 6.32, 7.38, 5.55, 6.37, 9.51, 7.78]
for i in range(8):
print(f" {schools[i]} {y_obs[i]:5.0f} {B[i]:.3f} "
f"{theta_shrunk[i]:7.2f} {mcmc_means[i]:7.2f}")
School y_obs B_i shrunk MCMC_mean
------------------------------------------------
A 28 0.862 10.76 9.72
B 8 0.735 8.00 7.43
C -3 0.877 6.64 6.32
D 7 0.771 7.77 7.38
E -1 0.692 5.23 5.55
F 1 0.771 6.39 6.37
G 18 0.735 10.65 9.51
H 12 0.900 8.40 7.78
The shrinkage formula approximates the MCMC posterior means but does not match exactly. Two reasons: (i) the formula conditions on fixed \(\mu = 8, \tau = 6\), while the full posterior integrates over uncertainty in both — the MCMC means are averages over all sampled \((\mu^{(s)}, \tau^{(s)})\) pairs; (ii) the posterior for \(\tau\) is right-skewed and concentrates below \(\tau = 6\), so the effective shrinkage is somewhat stronger than the formula predicts at \(\tau = 6\).
(c) \(\hat{\theta}_A = (1 - 0.862) \times 28 + 0.862 \times 8 = 3.86 + 6.90 = 10.76\). Reduction: \((28 - 10.76)/28 = 61.6\%\). School A’s standard error (\(\sigma_A = 15\)) is the second-largest in the dataset, meaning its observed effect of 28 is very noisy. The other seven schools show effects ranging from \(-3\) to 18 with an overall mean near 8 — an extreme value of 28 is more likely to reflect measurement noise than a genuinely enormous coaching effect. The hierarchical model appropriately discounts it.
(d) \(B_I = 5^2/(5^2 + 6^2) = 25/61 = 0.410\). This is less than any current school’s shrinkage factor. A precisely measured school retains \(1 - 0.410 = 59\%\) of its own data in the shrunk estimate — the model trusts precise measurements more, exactly as it should.
Exercise 5.8.2: Non-Centred Reparameterisation
(a) Starting from the centred specification \(\theta_i \sim \mathcal{N}(\mu, \tau)\), derive the non-centred form by defining \(\tilde{\theta}_i = (\theta_i - \mu)/\tau\). Show that \(\tilde{\theta}_i \sim \mathcal{N}(0, 1)\) and that the Jacobian of the transformation is \(\tau^J\) (where \(J\) is the number of groups).
(b) Explain why the joint distribution \(p(\tilde{\theta}_1, \ldots, \tilde{\theta}_J, \mu, \tau)\) has geometry that is approximately independent of \(\tau\), while \(p(\theta_1, \ldots, \theta_J, \mu, \tau)\) forms a funnel. What happens to the \(\tilde{\theta}_i\) marginal when \(\tau \to 0\)?
(c) Python. Fit the Eight Schools model using BOTH the centred and non-centred parameterisations with random_seed=42. For each, report: number of divergences, \(\hat{R}\) for \(\tau\), ESS for \(\tau\), and the 89% HDI for \(\tau\). Produce the az.plot_pair scatter of \((\tau, \theta_0)\) for both models.
Solution
(a) If \(\theta_i \sim \mathcal{N}(\mu, \tau)\), then the standardised variable \(\tilde{\theta}_i = (\theta_i - \mu)/\tau\) has:
so \(\tilde{\theta}_i \sim \mathcal{N}(0, 1)\). The inverse transform is \(\theta_i = \mu + \tau \tilde{\theta}_i\). For \(J\) independent transforms, the Jacobian matrix is diagonal with entries \(\partial \theta_i / \partial \tilde{\theta}_i = \tau\), giving determinant \(|\mathbf{J}| = \tau^J\).
(b) In the centred parameterisation, the conditional standard deviation of each \(\theta_i\) given \(\tau\) is \(\tau\). When \(\tau \to 0\), all \(\theta_i\) must collapse onto \(\mu\), compressing \(J\) dimensions into a one-dimensional subspace — this is the funnel’s neck. In the non-centred form, \(\tilde{\theta}_i \sim \mathcal{N}(0, 1)\) regardless of \(\tau\): the marginals do not change, so the geometry stays cylindrical. The compression is absorbed into the deterministic transform \(\theta_i = \mu + \tau \tilde{\theta}_i\), where it is harmless because NUTS only differentiates with respect to the sampled parameters \(\tilde{\theta}_i\).
(c)
import numpy as np
import pymc as pm
import arviz as az
y_obs = np.array([28, 8, -3, 7, -1, 1, 18, 12], dtype=float)
sigma_i = np.array([15, 10, 16, 11, 9, 11, 10, 18], dtype=float)
J = 8
# Centred model
with pm.Model() as centred:
mu = pm.Normal('mu', mu=0, sigma=20)
tau = pm.HalfNormal('tau', sigma=10)
theta = pm.Normal('theta', mu=mu, sigma=tau, shape=J)
y = pm.Normal('y', mu=theta, sigma=sigma_i, observed=y_obs)
idata_c = pm.sample(draws=2000, tune=1000, chains=4,
target_accept=0.90, random_seed=42)
# Non-centred model
with pm.Model() as noncentred:
mu = pm.Normal('mu', mu=0, sigma=20)
tau = pm.HalfNormal('tau', sigma=10)
theta_raw = pm.Normal('theta_raw', mu=0, sigma=1, shape=J)
theta = pm.Deterministic('theta', mu + tau * theta_raw)
y = pm.Normal('y', mu=theta, sigma=sigma_i, observed=y_obs)
idata_nc = pm.sample(draws=2000, tune=1000, chains=4,
target_accept=0.90, random_seed=42)
# Compare diagnostics
for label, idata in [("Centred", idata_c), ("Non-centred", idata_nc)]:
divs = int(idata.sample_stats['diverging'].values.sum())
rhat = float(az.rhat(idata, var_names=['tau'])['tau'])
ess = float(az.ess(idata, var_names=['tau'])['tau'])
hdi = az.hdi(idata, var_names=['tau'], hdi_prob=0.89)['tau'].values
print(f"{label:13s}: divergences={divs:3d} "
f"R-hat={rhat:.3f} ESS={ess:.0f} "
f"89% HDI=[{hdi[0]:.2f}, {hdi[1]:.2f}]")
# Scatter plots
az.plot_pair(idata_c, var_names=['tau', 'theta'],
coords={'theta_dim_0': [0]},
divergences=True, kind='scatter')
az.plot_pair(idata_nc, var_names=['tau', 'theta'],
coords={'theta_dim_0': [0]},
divergences=True, kind='scatter')
Centred : divergences=332 R-hat=1.007 ESS=296 89% HDI=[0.80, 10.50]
Non-centred : divergences= 0 R-hat=1.000 ESS=4368 89% HDI=[0.00, 9.71]
The centred model has divergences concentrated at small \(\tau\) (the funnel neck) and nearly fifteen times fewer effective samples for \(\tau\). The non-centred model eliminates the pathology entirely.
Exercise 5.8.3: Hierarchical Poisson Model
Eight hospitals report the number of adverse events in a one-month period. The hospitals have different patient volumes (exposure), so the relevant parameter is the adverse event rate \(\lambda_i\) (events per 1000 patient-days).
(a) Write the hierarchical model using a log-normal population distribution for the rates. Explain why the log-normal is natural for positive-valued rates and why the non-centred parameterisation is applied in log-space.
(b) Python. Simulate data with true rates drawn from \(\text{LogNormal}(\mu_{\log} = 0.5, \sigma_{\log} = 0.6)\) and exposures \(e = (2.1, 5.0, 1.3, 8.2, 0.7, 3.5, 6.1, 4.0)\). Fit the hierarchical model in PyMC.
(c) Fit a no-pooling model (independent vague priors per hospital) and compare 89% HDIs for the hospital with the smallest exposure (\(e_5 = 0.7\)). Quantify the interval-width reduction from partial pooling.
(d) Predict the adverse event rate for a new hospital with exposure \(e_9 = 3.0\). Plot the predictive distribution for \(\lambda_9\) and compare its width to the posterior for Hospital 5.
Solution
(a) The log-normal distribution has support \((0, \infty)\), matching the positivity constraint on rates. Working in log-space, the non-centred parameterisation is:
The exponential transform maps the unbounded \(\tilde{\lambda}_i\) to positive rates. The non-centred form prevents the funnel in \((\sigma_{\log}, \tilde{\lambda}_i)\) space, just as it did for \((\tau, \tilde{\theta}_i)\) in Eight Schools.
(b)
import numpy as np
import pymc as pm
import arviz as az
rng = np.random.default_rng(42)
J = 8
e = np.array([2.1, 5.0, 1.3, 8.2, 0.7, 3.5, 6.1, 4.0])
# True rates from LogNormal(0.5, 0.6)
lam_true = rng.lognormal(0.5, 0.6, size=J)
y_obs = rng.poisson(lam_true * e)
print("Hospital exposure true_rate y_obs")
for i in range(J):
print(f" {i+1} {e[i]:5.1f} {lam_true[i]:.2f} {y_obs[i]:3d}")
# Hierarchical model (non-centred)
with pm.Model() as hier_poisson:
mu_log = pm.Normal('mu_log', mu=0, sigma=1)
sigma_log = pm.HalfNormal('sigma_log', sigma=1)
lam_raw = pm.Normal('lam_raw', mu=0, sigma=1, shape=J)
lam = pm.Deterministic('lam',
pm.math.exp(mu_log + sigma_log * lam_raw))
y = pm.Poisson('y', mu=lam * e, observed=y_obs)
idata_hp = pm.sample(draws=2000, tune=1000, chains=4,
target_accept=0.90, random_seed=42,
idata_kwargs={"log_likelihood": True})
print(az.summary(idata_hp, var_names=['mu_log', 'sigma_log', 'lam'],
hdi_prob=0.89))
Hospital exposure true_rate y_obs
1 2.1 1.98 4
2 5.0 0.88 4
3 1.3 2.59 7
4 8.2 2.90 23
5 0.7 0.51 0
6 3.5 0.75 4
7 6.1 1.78 10
8 4.0 1.36 4
(c)
# No-pooling model
with pm.Model() as no_pool_poisson:
lam_np = pm.Gamma('lam', alpha=1, beta=0.5, shape=J)
y_np = pm.Poisson('y', mu=lam_np * e, observed=y_obs)
idata_np = pm.sample(draws=2000, tune=1000, chains=4,
target_accept=0.90, random_seed=42,
idata_kwargs={"log_likelihood": True})
# Compare Hospital 5 (smallest exposure)
h5_hier = az.hdi(idata_hp, var_names=['lam'],
hdi_prob=0.89)['lam'].sel(lam_dim_0=4).values
h5_np = az.hdi(idata_np, var_names=['lam'],
hdi_prob=0.89)['lam'].sel(lam_dim_0=4).values
w_hier = h5_hier[1] - h5_hier[0]
w_np = h5_np[1] - h5_np[0]
print(f"Hospital 5 (e=0.7):")
print(f" Hierarchical 89% HDI: [{h5_hier[0]:.2f}, {h5_hier[1]:.2f}]"
f" width = {w_hier:.2f}")
print(f" No-pooling 89% HDI: [{h5_np[0]:.2f}, {h5_np[1]:.2f}]"
f" width = {w_np:.2f}")
print(f" Width reduction: {100*(1 - w_hier/w_np):.1f}%")
Result for this dataset: Hospital 5 recorded zero events, so its no-pooling 89% HDI ([0.00, 1.79], width 1.79) piles up against zero, while the hierarchical HDI ([0.20, 2.30], width 2.10) is pulled toward the population rate — here partial pooling corrects an overconfident near-zero estimate rather than narrowing the interval. The influence of the population distribution is strongest for the smallest-exposure hospitals.
(d)
mu_log_samples = idata_hp.posterior['mu_log'].values.flatten()
sig_log_samples = idata_hp.posterior['sigma_log'].values.flatten()
# Draw new hospital rate from population distribution
lam_new = rng.lognormal(mu_log_samples, sig_log_samples)
y_new = rng.poisson(lam_new * 3.0)
hdi_new = np.percentile(lam_new, [5.5, 94.5])
lam5 = idata_hp.posterior['lam'].sel(lam_dim_0=4).values.flatten()
hdi_5 = np.percentile(lam5, [5.5, 94.5])
print(f"New hospital (e=3.0): predictive 89% HDI for lambda = "
f"[{hdi_new[0]:.2f}, {hdi_new[1]:.2f}] "
f"width = {hdi_new[1]-hdi_new[0]:.2f}")
print(f"Hospital 5 (e=0.7): posterior 89% HDI for lambda = "
f"[{hdi_5[0]:.2f}, {hdi_5[1]:.2f}] "
f"width = {hdi_5[1]-hdi_5[0]:.2f}")
The predictive interval for the new hospital is wider than the posterior for Hospital 5 because it includes between-hospital variability \(\sigma_{\log}\) as irreducible uncertainty. Hospital 5’s posterior is partially constrained by its single observed count.
Exercise 5.8.4: New Group Prediction and Exchangeability
(a) Using the Eight Schools non-centred posterior (idata_nc), predict the coaching effect for a hypothetical ninth school by drawing \(\theta_9^{(s)} \sim \mathcal{N}(\mu^{(s)}, \tau^{(s)})\) for each posterior sample \(s\). Plot a histogram of the predictive distribution for \(\theta_9\) and report the 89% HDI.
(b) Compare the predictive distribution for \(\theta_9\) to the posterior for School E (\(\theta_4\), which had \(y_E = -1, \sigma_E = 9\)). Which is wider and why?
(c) Now suppose you learn that the ninth school is a private school, while the original eight are all public. Should you still draw \(\theta_9\) from the same population distribution? If not, what modification to the model would you propose? Explain in terms of exchangeability.
(d) Python. Implement the modification from part (c) in PyMC by adding a group-level binary covariate. Simulate data where private schools have a 5-point higher mean effect, and show that the model recovers the covariate effect.
Solution
(a)
import numpy as np
import arviz as az
mu_samples = idata_nc.posterior['mu'].values.flatten()
tau_samples = idata_nc.posterior['tau'].values.flatten()
rng = np.random.default_rng(42)
# Draw from population distribution for each posterior sample
theta_new = rng.normal(mu_samples, tau_samples)
hdi = np.percentile(theta_new, [5.5, 94.5])
print(f"Predictive mean for School 9: {theta_new.mean():.1f}")
print(f"Predictive SD for School 9: {theta_new.std():.1f}")
print(f"89% HDI: [{hdi[0]:.1f}, {hdi[1]:.1f}]")
Predictive mean for School 9: 7.4
Predictive SD for School 9: 7.6
89% HDI: [-3.9, 19.0]
The predictive distribution is very wide: without any data from School 9, the best we can say is that the coaching effect is likely positive (centred around 7) but could plausibly range from \(-4\) to \(+19\).
(b)
theta_E = idata_nc.posterior['theta'].sel(theta_dim_0=4).values.flatten()
hdi_E = np.percentile(theta_E, [5.5, 94.5])
print(f"School E posterior: mean={theta_E.mean():.1f} "
f"SD={theta_E.std():.1f} 89% HDI=[{hdi_E[0]:.1f}, {hdi_E[1]:.1f}]")
print(f"School 9 predictive: mean={theta_new.mean():.1f} "
f"SD={theta_new.std():.1f} 89% HDI=[{hdi[0]:.1f}, {hdi[1]:.1f}]")
print(f"Width ratio (9/E): "
f"{(hdi[1]-hdi[0])/(hdi_E[1]-hdi_E[0]):.2f}")
School E posterior: mean=5.6 SD=5.8 89% HDI=[-4.2, 14.2]
School 9 predictive: mean=7.4 SD=7.6 89% HDI=[-3.9, 19.0]
Width ratio (9/E): 1.24
The predictive for \(\theta_9\) is approximately 25% wider. School E’s posterior is narrower because the observed data \((y_E = -1, \sigma_E = 9)\) provide direct information that constrains \(\theta_E\). The new school has no data — the only information comes from the population distribution, which includes the between-school variability \(\tau\) as irreducible spread.
(c) No. Exchangeability assumes that, before seeing data, we have no reason to distinguish any group from any other. If private schools systematically differ from public schools — due to different resources, student demographics, or selection effects — the exchangeability assumption is violated. Drawing School 9 from the same \(\mathcal{N}(\mu, \tau)\) as the public schools would ignore this structural difference.
The appropriate modification is to add a group-level covariate:
where \(x_i = 1\) for private schools and \(x_i = 0\) for public schools. The coefficient \(\beta\) captures the systematic private-school advantage (or disadvantage), and \(\eta_i\) captures residual between-school variation after accounting for the public/private distinction.
(d)
import numpy as np
import pymc as pm
import arviz as az
rng = np.random.default_rng(42)
# Simulate: 8 public + 4 private, private has +5 advantage
J = 12
x = np.array([0]*8 + [1]*4, dtype=float) # 0=public, 1=private
mu_true, beta_true, tau_true = 8.0, 5.0, 4.0
theta_true = mu_true + beta_true * x + rng.normal(0, tau_true, J)
sigma_i = rng.uniform(8, 16, J)
y_obs = rng.normal(theta_true, sigma_i)
# Hierarchical model with covariate
with pm.Model() as covariate_model:
mu = pm.Normal('mu', mu=0, sigma=20)
beta = pm.Normal('beta', mu=0, sigma=10)
tau = pm.HalfNormal('tau', sigma=10)
t_raw = pm.Normal('t_raw', mu=0, sigma=1, shape=J)
theta = pm.Deterministic('theta',
mu + beta * x + tau * t_raw)
y = pm.Normal('y', mu=theta, sigma=sigma_i, observed=y_obs)
idata_cov = pm.sample(draws=2000, tune=1000, chains=4,
target_accept=0.90, random_seed=42)
print(az.summary(idata_cov, var_names=['mu', 'beta', 'tau'],
hdi_prob=0.89))
mean sd hdi_5.5% hdi_94.5% r_hat ess_bulk ess_tail
mu 10.40 4.32 3.46 16.77 1.00 6757.0 4431.0
beta 2.04 6.60 -7.29 13.60 1.00 8654.0 5965.0
tau 4.86 3.68 0.00 9.73 1.00 3273.0 3564.0
The posterior for \(\beta\) is centred at 2.0 with a wide credible interval that easily covers the true value of 5 — with only 4 private schools and large within-school noise, the data say little about the covariate effect. With more private schools in the dataset, the estimate would sharpen toward the true value. The model structure still cleanly separates the systematic private-school term from residual between-school variation.
References
Rubin, D. B. (1981). Estimation in parallel randomized experiments. Journal of Educational Statistics, 6(4), 377–401. The original analysis of the Eight Schools data set; introduces the hierarchical Normal model for combining parallel experiments.
Gelman, A., Carlin, J. B., Stern, H. S., Dunson, D. B., Vehtari, A., and Rubin, D. B. (2013). Bayesian Data Analysis (3rd ed.). Chapman and Hall/CRC. The standard graduate reference for Bayesian statistics. Chapter 1 provides the three-step workflow that structures this section.
Betancourt, M., and Girolami, M. (2015). Hamiltonian Monte Carlo for hierarchical models. In Current Trends in Bayesian Methodology with Applications (pp. 79–101). CRC Press. Diagnoses the funnel geometry of centred hierarchical parameterisations and develops the non-centred reparameterisation as the standard remedy.
Gelman, A. (2006). Prior distributions for variance parameters in hierarchical models. Bayesian Analysis, 1(3), 515–534. The source of the weakly-informative Half-Cauchy recommendation for hierarchical variance components, with the scale chosen on the data scale (e.g., Half-Cauchy(0, 25) in the eight-schools analysis); widely adopted in PyMC and Stan communities.
Stein, C. (1956). Inadmissibility of the usual estimator for the mean of a multivariate normal distribution. In Proceedings of the Third Berkeley Symposium on Mathematical Statistics and Probability, Vol. 1 (pp. 197–206). University of California Press. The foundational result showing that simultaneous estimation of three or more means is improved by shrinkage toward the grand mean — the decision-theoretic precursor to hierarchical Bayes.