Rejection Sampling
The transformation methods of Transformation Methods exploit mathematical structure: Box–Muller converts uniforms to normals through polar coordinates; chi-squared emerges as a sum of squared normals; the t-distribution arises from a carefully constructed ratio. These methods are elegant and efficient—when they exist. But what happens when we need samples from a distribution with no known transformation from simple variates?
Consider the Beta distribution with general parameters \(\alpha, \beta\). No closed-form inverse CDF exists, and there is no simple transformation from uniforms or normals (except for special cases like \(\text{Beta}(1,1) = \text{Uniform}(0,1)\)). What about a posterior distribution in Bayesian inference, known only up to a normalizing constant? Or a custom density defined by a complex formula arising from domain expertise?
Rejection sampling (also called the accept-reject method) provides a universal solution. The idea, formalized by John von Neumann in 1951 [vonNeumann1951], is surprisingly intuitive: if we can envelope the target density with a scaled version of a simpler “proposal” density, we can generate candidates from the proposal and probabilistically accept or reject them. The accepted samples follow exactly the target distribution—no approximation, no asymptotic convergence, just exact sampling.
Von Neumann’s contribution was to generalize and formalize the intuition of random sampling into a systematic method for arbitrary distributions, making it foundational to computational statistics. For a comprehensive modern treatment, see Devroye [Devroye1986], which remains the definitive reference on random variate generation.
The method’s power lies in its generality: rejection sampling works for any target density we can evaluate pointwise, even if the normalization constant is unknown. This makes it indispensable for Bayesian computation, where posterior densities are typically known only up to proportionality. The cost is efficiency—when the envelope fits poorly, we reject many candidates before accepting one.
This section develops rejection sampling from first principles. We begin with geometric intuition via the “dartboard” interpretation, then formalize the algorithm and prove its correctness. We analyze efficiency through acceptance rates and explore strategies for choosing good proposal distributions. Worked examples demonstrate the method for Beta distributions, truncated normals, and custom densities. We conclude by examining the method’s limitations in high dimensions, setting the stage for the Markov Chain Monte Carlo methods of later chapters.
Road Map 🧭
Understand: The geometric intuition behind rejection sampling—points uniformly distributed under a curve
Prove: Why accepted samples follow the target distribution, even with unknown normalization
Analyze: Acceptance probability as \(1/M\) (normalized) or \(C/M\) (unnormalized)
Design: Strategies for choosing proposal distributions and computing the envelope constant
Implement: Efficient rejection samplers in Python with proper numerical safeguards
Recognize: When rejection sampling fails and alternatives are needed
The Dartboard Intuition
Before diving into formulas, let’s build geometric intuition for why rejection sampling works.
The Fundamental Theorem of Simulation
The theoretical foundation rests on a beautiful identity. For any normalized probability density \(f(x)\):
This seemingly trivial observation has profound implications: the density \(f(x)\) is the marginal of a uniform distribution over the region under its curve. Formally:
Key insight: If we can sample uniformly from the region under a density curve, the \(x\)-coordinates follow that density exactly. Rejection sampling operationalizes this observation.
Normalization caveat: This result requires \(f\) to be a proper density (integrating to 1). If \(\tilde{f}(x)\) is an unnormalized kernel with \(C = \int \tilde{f}(x)\,dx\), then the region \(\{(x, u) : 0 < u < \tilde{f}(x)\}\) has area \(C\), and uniform sampling over this region yields \(x\)-coordinates distributed as \(\tilde{f}(x)/C\)—the normalized version. This is precisely why rejection sampling works for unnormalized targets.
Points Under a Curve
Imagine plotting the probability density function \(f(x)\) of our target distribution on a coordinate plane. The area under this curve equals 1 (for a proper density). Now suppose we could somehow generate points \((x, y)\) uniformly distributed over the region under the curve—that is, uniformly over the set \(\{(x, y) : 0 \le y \le f(x)\}\).
What distribution would the \(x\)-coordinates of these points follow?
The answer is \(f(x)\) itself. To see why, consider any interval \([a, b]\). The probability that a uniformly distributed point has \(x \in [a, b]\) is proportional to the area of the region under \(f(x)\) between \(a\) and \(b\)—which is exactly \(\int_a^b f(x)\,dx\). This matches the definition of drawing from \(f\).
This observation suggests a sampling strategy: if we can generate points uniformly under \(f(x)\), we can extract their \(x\)-coordinates as samples from \(f\). But generating uniform points under an arbitrary curve is itself a non-trivial problem. Rejection sampling solves this by embedding the target region inside a larger, simpler region.
The Envelope Strategy
Suppose we have a proposal density \(g(x)\) from which we can easily sample (e.g., uniform, normal, exponential). We require that \(g(x) > 0\) wherever \(f(x) > 0\)—the proposal must “cover” the target. Furthermore, suppose we can find a constant \(M \ge 1\) such that:
The function \(M \cdot g(x)\) is called an envelope or hat function because it lies above \(\tilde{f}(x)\) everywhere. The region under \(\tilde{f}(x)\) is contained within the region under \(M \cdot g(x)\).
Important: We sample from \(g(x)\), not \(M \cdot g(x)\). The envelope \(M \cdot g(x)\) is not a proper density (it integrates to \(M\), not 1). It defines the geometric region for acceptance, but the proposal distribution \(g(x)\) is what we actually draw from.
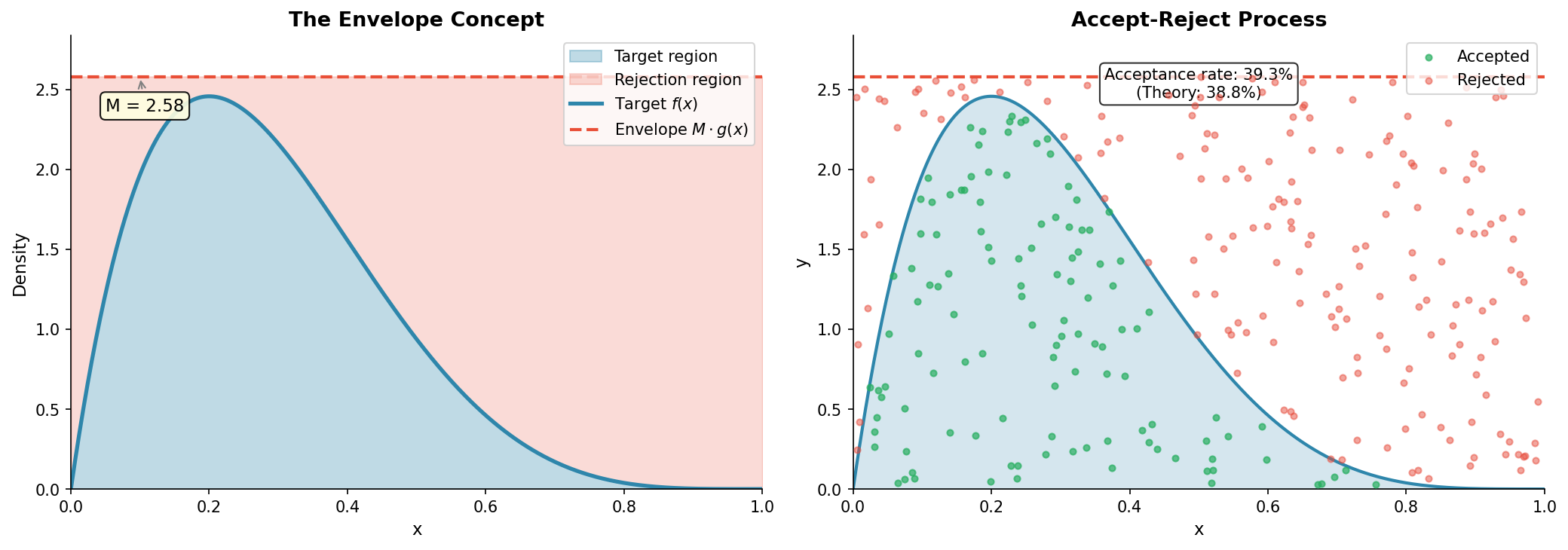
Fig. 65 The Envelope Concept. The target density \(f(x)\) (blue, shown here as a normalized density) is everywhere dominated by the envelope \(M \cdot g(x)\) (red dashed). Points uniformly distributed under the envelope will, when filtered to those under \(f(x)\), yield \(x\)-coordinates distributed according to \(f\). For this normalized case, the acceptance rate is \(1/M\).
Now here’s the key insight. We can easily generate points uniformly under \(M \cdot g(x)\):
Sample \(X \sim g(x)\) (a draw from the proposal distribution)
Sample \(Y \sim \text{Uniform}(0, M \cdot g(X))\) (a height uniformly distributed up to the envelope)
The pair \((X, Y)\) is uniformly distributed over the region under \(M \cdot g(x)\). If we now keep only those points with \(Y \le \tilde{f}(X)\)—those falling under the target density—the remaining points are uniformly distributed under \(\tilde{f}(x)\), and their \(x\)-coordinates follow \(\tilde{f}/C\).
The Accept-Reject Algorithm
We now formalize the geometric intuition into a precise algorithm.
Algorithm Statement
- Given:
Target density \(\tilde{f}(x)\), possibly known only up to a normalizing constant
Proposal density \(g(x)\) from which we can sample directly
Envelope constant \(M\) such that \(\tilde{f}(x) \le M \cdot g(x)\) for all \(x\)
Algorithm (Accept-Reject Method)
To generate one sample from f(x) = tilde{f}(x) / C:
1. REPEAT:
a. Draw X ~ g(x) [sample from proposal]
b. Draw U ~ Uniform(0, 1) [independent uniform]
c. Compute acceptance ratio:
α(X) = tilde{f}(X) / [M · g(X)]
d. IF U ≤ α(X):
ACCEPT X and RETURN X
ELSE:
REJECT X and continue to next iteration
2. The returned X is an exact draw from f(x) = tilde{f}(x) / C
The key observation is that we don’t actually need to generate \(Y = U \cdot M \cdot g(X)\) explicitly. The condition \(Y \le \tilde{f}(X)\) is equivalent to \(U \cdot M \cdot g(X) \le \tilde{f}(X)\), which simplifies to \(U \le \tilde{f}(X) / [M \cdot g(X)] = \alpha(X)\).
Proof of Correctness
We now prove that accepted samples follow the target distribution \(f(x) = \tilde{f}(x)/C\).
Theorem (Correctness of Accept-Reject). Let \(\tilde{f}(x)\) be a non-negative measurable function with \(0 < C = \int \tilde{f}(x)\,dx < \infty\), and let \(g(x)\) be a probability density with \(g(x) > 0\) wherever \(\tilde{f}(x) > 0\). If \(\tilde{f}(x) \le M \cdot g(x)\) for all \(x\), then the accepted value \(X\) from the accept-reject algorithm has density \(f(x) = \tilde{f}(x)/C\).
Proof. Consider a single iteration. We generate \(X \sim g(x)\) and, independently, \(U \sim \text{Uniform}(0,1)\). We accept if \(U \le \tilde{f}(X)/[M \cdot g(X)]\).
For any measurable set \(A\), by independence of \(U\) and \(X\):
The overall probability of acceptance is:
By Bayes’ theorem:
This is exactly the probability that a random variable with density \(f(x) = \tilde{f}(x)/C\) lies in \(A\). ∎
Key insight: The normalization constant \(C\) cancels in the acceptance ratio. We never need to compute \(\int \tilde{f}(x)\,dx\)—rejection sampling works even when \(\tilde{f}\) is known only up to proportionality.
Notation Convention
Throughout this section, we use:
\(\tilde{f}(x)\): unnormalized target (kernel), known up to proportionality
\(C = \int \tilde{f}(x)\,dx\): normalizing constant (often unknown)
\(f(x) = \tilde{f}(x)/C\): normalized density
The envelope condition is \(\tilde{f}(x) \le M \cdot g(x)\) for all \(x\). The algorithm uses only \(\tilde{f}\), never requiring \(C\).
Parameterization Convention
This section uses SciPy’s scale parameterization for the Gamma and Exponential distributions:
Gamma(shape, scale): \(f(x) = \frac{x^{\text{shape}-1} e^{-x/\text{scale}}}{\text{scale}^{\text{shape}} \Gamma(\text{shape})}\)
Exponential(scale): \(f(x) = \frac{1}{\text{scale}} e^{-x/\text{scale}}\)
The rate parameterization (common in statistics) relates via scale = 1/rate. When mathematical notation uses \(\text{Gamma}(\alpha, 1)\), the SciPy call is stats.gamma(a=alpha, scale=1).
Efficiency Analysis
Not every proposed sample is accepted. Understanding the acceptance rate is crucial for assessing computational cost.
Acceptance Probability: Two Cases
From the proof above, the acceptance probability depends on whether the target is normalized:
Acceptance Rate Summary
Case 1: Normalized target \(f(x)\) with \(\int f(x)\,dx = 1\):
Case 2: Unnormalized target \(\tilde{f}(x)\) with \(C = \int \tilde{f}(x)\,dx\):
Most textbook examples and library implementations assume Case 1 (normalized target). When working with unnormalized kernels—common in Bayesian inference—use Case 2.
Geometric interpretation: The acceptance probability equals the ratio of the area under \(\tilde{f}(x)\) (which is \(C\)) to the area under \(M \cdot g(x)\) (which is \(M\)). A tighter envelope (smaller \(M\)) means less wasted area and higher efficiency.
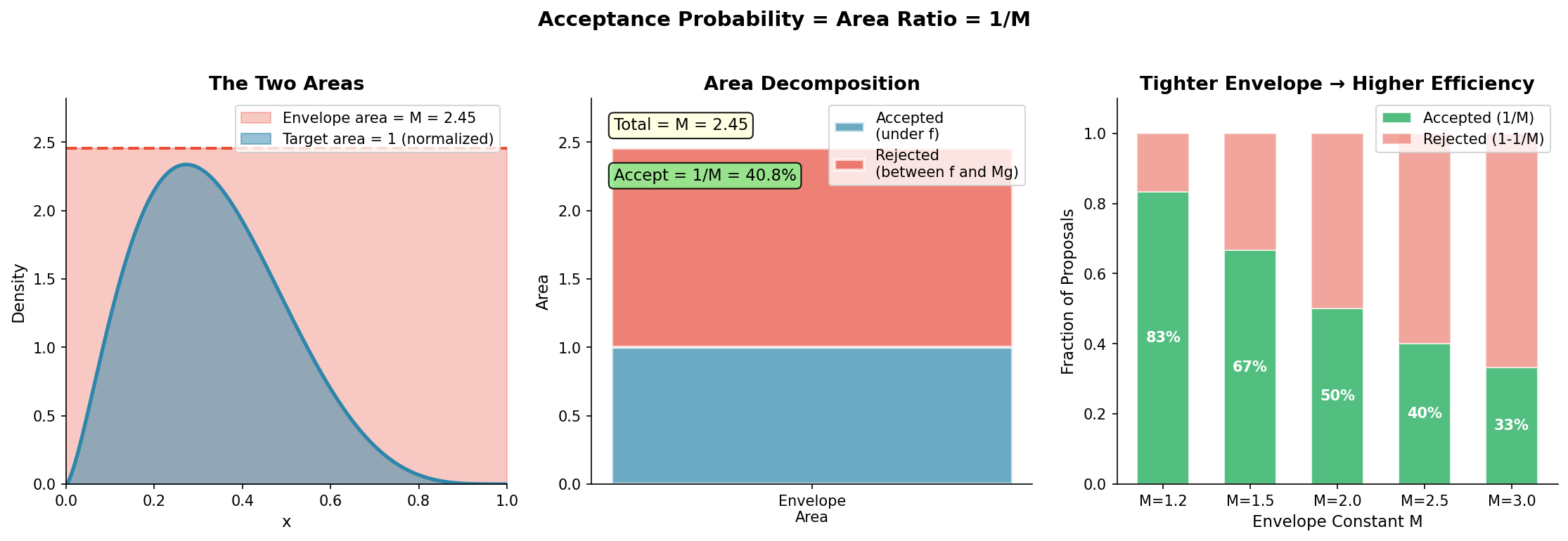
Fig. 66 Acceptance Probability as Area Ratio. This figure uses a normalized density \(f(x)\) (Case 1). Left: The target density \(f(x)\) (blue) sits inside the envelope \(M \cdot g(x)\) (red). Center: The envelope area decomposes into accepted (blue) and rejected (red) portions. Right: Smaller \(M\) values yield higher acceptance rates—a tighter envelope wastes less area. For normalized \(f\), the acceptance rate is \(1/M\).
The Optimal Envelope Constant
Given a proposal \(g(x)\), the smallest valid \(M\) is:
Using \(M^*\) maximizes acceptance probability. Any \(M > M^*\) is valid but wasteful; any \(M < M^*\) violates the envelope condition and produces incorrect samples.
Common Pitfall ⚠️
Using M that’s too small: If \(M \cdot g(x) < \tilde{f}(x)\) for some \(x\), samples from the region where the envelope dips below the target are underrepresented. This is a silent error—the algorithm runs but produces biased samples. Always verify that your envelope truly dominates the target, especially in tail regions.
Choosing the Proposal Distribution
The efficiency of rejection sampling hinges on choosing a proposal \(g(x)\) that closely approximates the target \(\tilde{f}(x)\) while remaining easy to sample.
Desiderata for Proposals
A good proposal distribution should satisfy:
Easy to sample: We need fast, direct sampling from \(g(x)\). Good choices include uniform, exponential, normal, Cauchy, and mixtures of these.
Support covers target: Wherever \(\tilde{f}(x) > 0\), we need \(g(x) > 0\). Otherwise, some regions of the target receive zero probability mass.
Shape matches target: Ideally, the ratio \(\tilde{f}(x)/g(x)\) should be nearly constant. Large variations in this ratio force \(M\) to be large, reducing efficiency.
Tail behavior matches or exceeds: If \(\tilde{f}(x)\) has heavy tails, \(g(x)\) must have at least as heavy tails. A light-tailed proposal for a heavy-tailed target leads to \(M = \infty\).
Finding the Envelope Constant
Given \(\tilde{f}\) and \(g\), we must compute \(M^* = \sup_x \tilde{f}(x)/g(x)\). Several approaches are available:
Analytical optimization: For well-behaved functions, calculus yields the maximum. Set the derivative of \(\tilde{f}(x)/g(x)\) to zero and solve.
Numerical optimization: Use scipy.optimize.minimize_scalar to find the maximum of \(\tilde{f}(x)/g(x)\).
Grid search: Evaluate the ratio on a fine grid covering the support, then take the maximum plus a small safety margin.
Bounding arguments: Sometimes theoretical bounds are available. For instance, if \(\tilde{f}\) is a product of terms each bounded by a constant, those bounds can be combined.
Example 💡 Finding M for Beta(2.5, 6) with Uniform Proposal
Setup (using normalized density): Target is \(f(x) = \frac{x^{1.5}(1-x)^5}{B(2.5, 6)}\) on \([0, 1]\), which is the normalized Beta(2.5, 6) density. Proposal is \(g(x) = 1\) (uniform on \([0, 1]\)).
Find M: For a uniform proposal with normalized target, \(M = \max_x f(x)\). The mode of Beta(\(\alpha, \beta\)) with \(\alpha, \beta > 1\) is \(x^* = (\alpha - 1)/(\alpha + \beta - 2)\).
Here \(x^* = 1.5/6.5 \approx 0.2308\). Computing the normalized density at the mode:
Acceptance rate (Case 1, normalized): \(P(\text{accept}) = 1/M^* \approx 38.3\%\).
Alternative (unnormalized): If using the kernel \(\tilde{f}(x) = x^{1.5}(1-x)^5\) directly, then \(M^* = k(x^*) \approx 0.0297\) and \(C = B(2.5, 6) \approx 0.01137\), giving \(P(\text{accept}) = C/M^* \approx 38.3\%\)—the same result.
Numerical Approaches for Finding M
When analytical optimization is difficult, numerical methods provide \(M\):
Grid search: Evaluate \(\tilde{f}(x)/g(x)\) on a dense grid covering the support, then take the maximum with a safety margin:
def find_M_grid(target_pdf, proposal_pdf, x_min, x_max, n_grid=10000):
"""
Find envelope constant M via grid search.
Parameters
----------
target_pdf : callable
Target density or kernel (normalized or unnormalized).
proposal_pdf : callable
Proposal density (must be normalized).
x_min, x_max : float
Bounds for the support.
n_grid : int
Number of grid points.
Returns
-------
float
Envelope constant M with 2% safety margin.
"""
x_grid = np.linspace(x_min, x_max, n_grid)
# Vectorized evaluation
g_vals = proposal_pdf(x_grid)
f_vals = target_pdf(x_grid)
# Avoid division by zero
valid = g_vals > 1e-15
ratios = np.zeros_like(x_grid)
ratios[valid] = f_vals[valid] / g_vals[valid]
M_grid = np.max(ratios)
# Safety margin: 1-2% above grid maximum
return M_grid * 1.02
Numerical optimization: Use scipy.optimize to find the maximum directly:
from scipy.optimize import minimize_scalar
def find_M_optimize(target_pdf, proposal_pdf, bounds):
"""Find M via numerical optimization."""
def neg_ratio(x):
g = proposal_pdf(x)
if g < 1e-15:
return 0 # Avoid division issues
return -target_pdf(x) / g
result = minimize_scalar(neg_ratio, bounds=bounds, method='bounded')
M_optimal = -result.fun
return M_optimal * 1.01 # Small safety margin
Adaptive refinement: For distributions with sharp peaks or boundary behavior, combine coarse grid search with local refinement near suspected maxima.
Common Pitfall ⚠️
Grid search misses boundary maxima: If \(\tilde{f}(x)/g(x)\) peaks at or near a boundary, a naive grid may miss it. Always include points very close to boundaries (e.g., \(x = 10^{-6}\) for distributions on \([0, \infty)\)), and verify that your computed \(M\) truly dominates by checking \(\tilde{f}(x) \le M \cdot g(x)\) at random test points.
Strategies for Proposal Selection
Choosing a good proposal is both art and science. The goal is to minimize \(M = \sup_x \tilde{f}(x)/g(x)\), which means matching the shape of the target—not just covering its support.
Principle 1: Support coverage is necessary but not sufficient
The proposal must satisfy \(g(x) > 0\) wherever \(\tilde{f}(x) > 0\). But merely covering the support can yield terrible efficiency. For Beta(0.5, 5) on \([0, 1]\), a Uniform(0, 1) proposal gives \(M \approx 5.7\) (17.5% acceptance), while a well-tuned Beta proposal achieves \(M \approx 1.3\) (77% acceptance).
The Fundamental Requirement
Rejection sampling requires:
Equivalently, the ratio \(\tilde{f}/g\) must be bounded on the entire support. This single criterion unifies the tail behavior and singularity constraints discussed below.
Principle 2: Match tail behavior to avoid infinite M
If the target has heavier tails than the proposal, the ratio \(\tilde{f}(x)/g(x) \to \infty\) as \(|x| \to \infty\), making \(M = \infty\). This is a hard constraint:
Normal target → Normal, Cauchy, or Student-t proposal all work
Cauchy target → Normal proposal fails (\(M = \infty\))
Cauchy target → Cauchy or heavier-tailed proposal required
Principle 3: Match singularities for unbounded densities
If \(\tilde{f}(x) \to \infty\) at some point (e.g., Beta(0.5, 2) near \(x = 0\)), a bounded proposal cannot dominate. The proposal must have a matching or stronger singularity. See Exercise 2 for the Gamma(0.5, 1) case.
Principle 4: Shape matching minimizes M
The ideal proposal has \(g(x) \propto \tilde{f}(x)\), giving \(M = C\) (100% acceptance after normalization). In practice, we approximate this:
Target Shape |
Proposal Options |
Efficiency Considerations |
|---|---|---|
Symmetric, light-tailed (e.g., truncated normal) |
Normal, scaled to match spread |
Very efficient if variance matched; \(M \approx 1.1\text{-}1.5\) |
Skewed on \([0, 1]\) (e.g., Beta(2, 8)) |
Beta with similar skew, or mixture of Betas |
Uniform is simple but inefficient; Beta proposal can achieve \(M < 1.5\) |
Skewed on \([0, \infty)\) (e.g., Gamma, Weibull) |
Gamma or Exponential with rate matching mode |
Match tail decay rate; heavier proposal tail is safer |
Heavy-tailed (e.g., Cauchy, Pareto) |
Cauchy, Student-t, or Pareto |
Must use heavy-tailed proposal; normal fails |
Multimodal |
Mixture matching mode locations |
Single unimodal proposal forces large \(M\); mixtures dramatically improve efficiency |
Log-concave |
Adaptive Rejection Sampling (ARS) |
Envelope adapts during sampling; very efficient |
Example: Beta(2, 8) — Comparing Proposals (Normalized Target)
from scipy import stats
import numpy as np
target = stats.beta(2, 8) # Normalized density
x = np.linspace(0.001, 0.999, 10000)
f = target.pdf(x)
# Option 1: Uniform(0, 1) proposal
g_uniform = np.ones_like(x)
M_uniform = np.max(f / g_uniform)
# Case 1 (normalized): acceptance = 1/M
print(f"Uniform proposal: M = {M_uniform:.2f}, acceptance = {1/M_uniform:.1%}")
# Option 2: Beta(2, 7) proposal (similar shape)
proposal = stats.beta(2, 7)
g_beta = proposal.pdf(x)
M_beta = np.max(f / g_beta)
print(f"Beta(2,7) proposal: M = {M_beta:.2f}, acceptance = {1/M_beta:.1%}")
# Option 3: Beta(1.5, 6) proposal (slightly different)
proposal2 = stats.beta(1.5, 6)
g_beta2 = proposal2.pdf(x)
M_beta2 = np.max(f / g_beta2)
print(f"Beta(1.5,6) proposal: M = {M_beta2:.2f}, acceptance = {1/M_beta2:.1%}")
Output:
Uniform proposal: M = 2.62, acceptance = 38.2%
Beta(2,7) proposal: M = 1.18, acceptance = 84.7%
Beta(1.5,6) proposal: M = 1.31, acceptance = 76.3%
The Beta(2, 7) proposal—chosen to approximate the target’s shape—achieves more than double the acceptance rate of the uniform proposal.
Practical Guidance
Start simple: Uniform or normal proposals are easy to implement and debug. Use them first to verify correctness.
Profile before optimizing: If acceptance rate is above 20-30%, the simple proposal may be adequate. Optimize only if efficiency matters.
Use the same family when possible: For a Gamma target, try a Gamma proposal with slightly larger variance. For Beta targets, try Beta proposals.
Verify envelope condition: After choosing \(g\) and computing \(M\), always verify \(\tilde{f}(x) \le M \cdot g(x)\) at many points, especially near boundaries and modes.
Python Implementation
Let’s implement rejection sampling and apply it to several distributions.
Basic Implementation
import numpy as np
from scipy import stats
def rejection_sample(target_pdf, proposal_sampler, proposal_pdf, M,
n_samples, seed=None):
"""
Generate samples from target using rejection sampling.
Parameters
----------
target_pdf : callable
Function computing f(x) or tilde{f}(x).
proposal_sampler : callable
Function that returns one sample from g(x).
proposal_pdf : callable
Function computing g(x).
M : float
Envelope constant such that target_pdf(x) <= M * proposal_pdf(x).
n_samples : int
Number of samples to generate.
seed : int, optional
Random seed for reproducibility.
Returns
-------
samples : ndarray
Array of n_samples draws from the target distribution.
acceptance_rate : float
Fraction of proposals that were accepted.
Notes
-----
If target_pdf is normalized, acceptance rate ≈ 1/M.
If target_pdf is unnormalized with integral C, acceptance rate ≈ C/M.
"""
rng = np.random.default_rng(seed)
samples = []
n_proposals = 0
while len(samples) < n_samples:
# Step 1: Draw from proposal
x = proposal_sampler(rng)
n_proposals += 1
# Step 2: Draw uniform for acceptance test
u = rng.random()
# Step 3: Accept or reject
acceptance_prob = target_pdf(x) / (M * proposal_pdf(x))
if u <= acceptance_prob:
samples.append(x)
return np.array(samples), len(samples) / n_proposals
Example 💡 Sampling from Beta(2.5, 6) — Normalized Target (Case 1)
Given: Target is Beta(2.5, 6) using the normalized pdf from scipy; proposal is Uniform(0, 1)
Acceptance rate formula: Since we use normalized \(f\), acceptance rate is \(1/M\).
Implementation:
import numpy as np
from scipy import stats
# Target: Beta(2.5, 6) - NORMALIZED pdf via scipy
alpha, beta_param = 2.5, 6.0
target_dist = stats.beta(alpha, beta_param)
target_pdf = target_dist.pdf # Normalized, vectorized
# Proposal: Uniform(0, 1)
def proposal_sampler(rng):
return rng.random()
def proposal_pdf(x):
return np.where((x >= 0) & (x <= 1), 1.0, 0.0)
# Find M: maximum of normalized Beta density
x_grid = np.linspace(0.001, 0.999, 10000)
M = target_pdf(x_grid).max() * 1.01 # 1% safety margin
print(f"Envelope constant M = {M:.4f}")
print(f"Expected acceptance rate (Case 1: 1/M) = {1/M:.1%}")
# Generate samples
samples, acc_rate = rejection_sample(
target_pdf, proposal_sampler, proposal_pdf, M,
n_samples=10000, seed=42
)
print(f"Actual acceptance rate = {acc_rate:.1%}")
print(f"Sample mean = {samples.mean():.4f} (theory: {alpha/(alpha+beta_param):.4f})")
Output:
Envelope constant M = 2.6360
Expected acceptance rate (Case 1: 1/M) = 37.9%
Actual acceptance rate = 38.2%
Sample mean = 0.2937 (theory: 0.2941)
The acceptance rate matches the theoretical \(1/M \approx 38\%\), confirming we’re in Case 1.
Example 💡 Sampling from Beta(2.5, 6) — Unnormalized Kernel (Case 2)
Given: Target is the unnormalized kernel \(\tilde{f}(x) = x^{1.5}(1-x)^5\); proposal is Uniform(0, 1)
Acceptance rate formula: Since we use unnormalized \(\tilde{f}\), acceptance rate is \(C/M\) where \(C = B(2.5, 6)\).
Implementation:
import numpy as np
from scipy import special
alpha, beta_param = 2.5, 6.0
# UNNORMALIZED kernel
def kernel(x):
return x**(alpha-1) * (1-x)**(beta_param-1)
# Normalizing constant (often unknown in practice)
C = special.beta(alpha, beta_param)
print(f"Normalizing constant C = B({alpha}, {beta_param}) = {C:.6f}")
# Proposal: Uniform(0, 1)
def proposal_sampler(rng):
return rng.random()
def proposal_pdf(x):
return 1.0
# Find M for kernel
x_grid = np.linspace(0.001, 0.999, 10000)
M = kernel(x_grid).max() * 1.01
print(f"Envelope constant M = {M:.6f}")
print(f"Expected acceptance rate (Case 2: C/M) = {C/M:.1%}")
# Generate samples
samples, acc_rate = rejection_sample(
kernel, proposal_sampler, proposal_pdf, M,
n_samples=10000, seed=42
)
print(f"Actual acceptance rate = {acc_rate:.1%}")
Output:
Normalizing constant C = B(2.5, 6) = 0.011370
Envelope constant M = 0.030001
Expected acceptance rate (Case 2: C/M) = 37.9%
Actual acceptance rate = 38.2%
Key observation: Both approaches yield the same 38% acceptance rate—the normalized and unnormalized formulations are equivalent. Use Case 1 formula \(1/M\) when your pdf is normalized; use Case 2 formula \(C/M\) when working with kernels.
Vectorized Implementation for Speed
The basic implementation loops over individual samples. For better performance, we can generate batches of proposals and filter:
def rejection_sample_vectorized(target_pdf, proposal_sampler_batch,
proposal_pdf, M, n_samples, seed=None):
"""
Vectorized rejection sampling for improved performance.
Parameters
----------
proposal_sampler_batch : callable
Function that takes (rng, batch_size) and returns batch_size samples.
Notes
-----
For normalized targets, acceptance rate ≈ 1/M.
For unnormalized targets with integral C, acceptance rate ≈ C/M.
"""
rng = np.random.default_rng(seed)
samples = []
n_proposals = 0
# Estimate batch size based on expected acceptance rate
batch_size = max(100, int(2 * M * n_samples / 10))
while len(samples) < n_samples:
# Generate batch of proposals
x_batch = proposal_sampler_batch(rng, batch_size)
u_batch = rng.random(batch_size)
n_proposals += batch_size
# Vectorized acceptance test
f_vals = target_pdf(x_batch)
g_vals = proposal_pdf(x_batch)
acceptance_probs = f_vals / (M * g_vals)
# Accept where u <= acceptance probability
accepted = x_batch[u_batch <= acceptance_probs]
samples.extend(accepted)
return np.array(samples[:n_samples]), n_samples / n_proposals
Implementation Note
For true vectorization, target_pdf and proposal_pdf must accept array inputs and return arrays. SciPy’s stats.distribution.pdf methods support this natively. If your target is a custom function, use np.vectorize as a quick fix, though this provides no speed benefit over explicit loops. For performance-critical code, rewrite the PDF using NumPy array operations.
The Squeeze Principle
When the target density \(\tilde{f}(x)\) is expensive to evaluate, we can accelerate rejection sampling using a squeeze function (also called a lower envelope). The idea, introduced by Marsaglia [Marsaglia1977], is to construct a cheap-to-evaluate function \(\ell(x)\) satisfying:
The modified algorithm becomes:
To generate one sample from f(x) with squeeze:
1. REPEAT:
a. Draw X ~ g(x)
b. Draw U ~ Uniform(0, 1)
c. IF U ≤ ℓ(X) / [M · g(X)]:
ACCEPT X immediately (without evaluating tilde{f})
d. ELSE IF U ≤ tilde{f}(X) / [M · g(X)]:
ACCEPT X (requires evaluating tilde{f})
e. ELSE:
REJECT X
2. Return accepted X
The squeeze function acts as a “fast accept” gate. If the uniform variate falls below \(\ell(X)/[M \cdot g(X)]\), we accept without ever computing \(\tilde{f}(X)\). Only when \(U\) falls between the squeeze and the envelope do we need the expensive \(\tilde{f}\) evaluation.
Efficiency gain: If \(\ell(x)\) is close to \(\tilde{f}(x)\), most acceptances occur at step (c), avoiding the costly \(\tilde{f}(x)\) evaluation. This is particularly valuable when \(\tilde{f}\) involves special functions, numerical integration, or complex likelihood computations.
Valid Squeeze Construction
Critical requirement: The squeeze function must satisfy \(\ell(x) \le \tilde{f}(x)\) for ALL \(x\) in the support. A function that exceeds the target anywhere is not a valid squeeze and will produce biased fast-accepts.
Common Pitfall ⚠️
Invalid “tent” squeeze for unimodal densities: A piecewise linear “tent” in density space connecting \((0, 0)\), \((x^*, f(x^*))\), \((1, 0)\) (where \(x^*\) is the mode) is not a valid squeeze for most unimodal densities. For example, with Beta(5, 5):
The tent has area \(\frac{1}{2} \cdot 1 \cdot f(0.5) = \frac{1}{2} \cdot 2.46 = 1.23\)
But any valid squeeze must have area \(\le 1\) (since \(\int f = 1\))
The tent actually exceeds the Beta(5, 5) density on substantial interior intervals
An area exceeding 1 is a red flag that the construction is invalid.
Safe construction for log-concave targets: For log-concave densities (where \(\log \tilde{f}(x)\) is concave), a provably valid squeeze can be constructed using secant lines in log-space. Many important distributions are log-concave:
Normal: \(\log \phi(x) \propto -x^2/2\) (concave parabola)
Exponential: \(\log(\lambda e^{-\lambda x}) \propto -\lambda x\) (linear, hence concave)
Gamma with \(\alpha \ge 1\): \(\log f(x) \propto (\alpha-1)\log x - x\) (concave for \(\alpha \ge 1\))
Beta with \(\alpha, \beta \ge 1\): log-concave on \((0, 1)\)
Logistic, truncated log-normal
Log-space secant squeeze: Choose anchor points \(x_0 < x_1 < \cdots < x_K\) and define:
By concavity of \(\log \tilde{f}\), the secant lines lie below the curve: \(\underline{h}(x) \le \log \tilde{f}(x)\). Exponentiating:
This construction is guaranteed valid for log-concave targets.
Example 💡 Valid Squeeze for Beta(5, 5) via Log-Space Secants
Beta(5, 5) is log-concave since \(\alpha, \beta \ge 1\). We construct a squeeze using linear interpolation in log-space:
import numpy as np
from scipy import stats
target = stats.beta(5, 5)
# Anchor points
x_anchors = np.array([0.1, 0.3, 0.5, 0.7, 0.9])
log_f_anchors = np.log(target.pdf(x_anchors))
def log_squeeze(x):
"""Piecewise linear interpolation in log-space."""
return np.interp(x, x_anchors, log_f_anchors)
def squeeze(x):
"""Valid squeeze: exp of log-space interpolation."""
return np.exp(log_squeeze(x))
# Verify squeeze validity
x_test = np.linspace(0.01, 0.99, 10000)
f_vals = target.pdf(x_test)
squeeze_vals = squeeze(x_test)
violations = np.sum(squeeze_vals > f_vals * 1.0001) # Allow tiny numerical error
print(f"Violations: {violations} (should be 0)")
# Squeeze efficiency
squeeze_area = np.trapz(squeeze_vals, x_test)
print(f"Squeeze area: {squeeze_area:.4f} (must be ≤ 1)")
print(f"Fast-accept fraction: ~{squeeze_area:.1%}")
Output:
Violations: 0 (should be 0)
Squeeze area: 0.8712 (must be ≤ 1)
Fast-accept fraction: ~87.1%
The log-space construction is valid (no violations) and achieves ~87% fast-accepts, avoiding expensive Beta function evaluations for most proposals.
Example 💡 Squeeze for Normal Density
From the Taylor expansion \(e^{-x^2/2} \ge 1 - x^2/2\) for \(|x| \le \sqrt{2}\), we can use \(\ell(x) = (1 - x^2/2)/\sqrt{2\pi}\) as a squeeze function for the standard normal density within \([-\sqrt{2}, \sqrt{2}]\). This avoids the exponential evaluation for about 61% of proposals when using a Cauchy envelope.
Geometric Example: Sampling from the Unit Disk
A classic application of rejection sampling is generating points uniformly distributed in a geometric region. Consider sampling uniformly from the unit disk \(\{(x, y) : x^2 + y^2 \le 1\}\).
Target: Uniform distribution on the disk (density \(f(x,y) = 1/\pi\) inside, 0 outside)
Proposal: Uniform on the bounding square \([-1, 1]^2\) (density \(g(x,y) = 1/4\))
Envelope constant: Inside the disk, \(f(x,y)/g(x,y) = (1/\pi)/(1/4) = 4/\pi\), so \(M = 4/\pi \approx 1.273\).
Acceptance rate (Case 1, normalized): \(1/M = \pi/4 \approx 78.5\%\), which equals the ratio of areas (disk area \(\pi\) divided by square area 4).
import numpy as np
def sample_unit_disk(n_samples, seed=None):
"""
Sample uniformly from the unit disk via rejection.
Uses normalized densities, so acceptance rate = 1/M = π/4 ≈ 78.5%.
"""
rng = np.random.default_rng(seed)
samples = []
n_proposals = 0
while len(samples) < n_samples:
# Propose from uniform square [-1, 1]²
x = rng.uniform(-1, 1)
y = rng.uniform(-1, 1)
n_proposals += 1
# Accept if inside disk
if x*x + y*y <= 1:
samples.append((x, y))
return np.array(samples), n_samples / n_proposals
# Generate 10,000 points
points, acc_rate = sample_unit_disk(10000, seed=42)
print(f"Acceptance rate: {acc_rate:.3f} (theory: π/4 = {np.pi/4:.3f})")
print(f"Points shape: {points.shape}")
Output:
Acceptance rate: 0.785 (theory: π/4 = 0.785)
Points shape: (10000, 2)
This “hit-and-miss” approach generalizes to any region where membership can be tested: sample from a bounding box and reject points outside the target region. The efficiency depends on how well the bounding box fits the region.
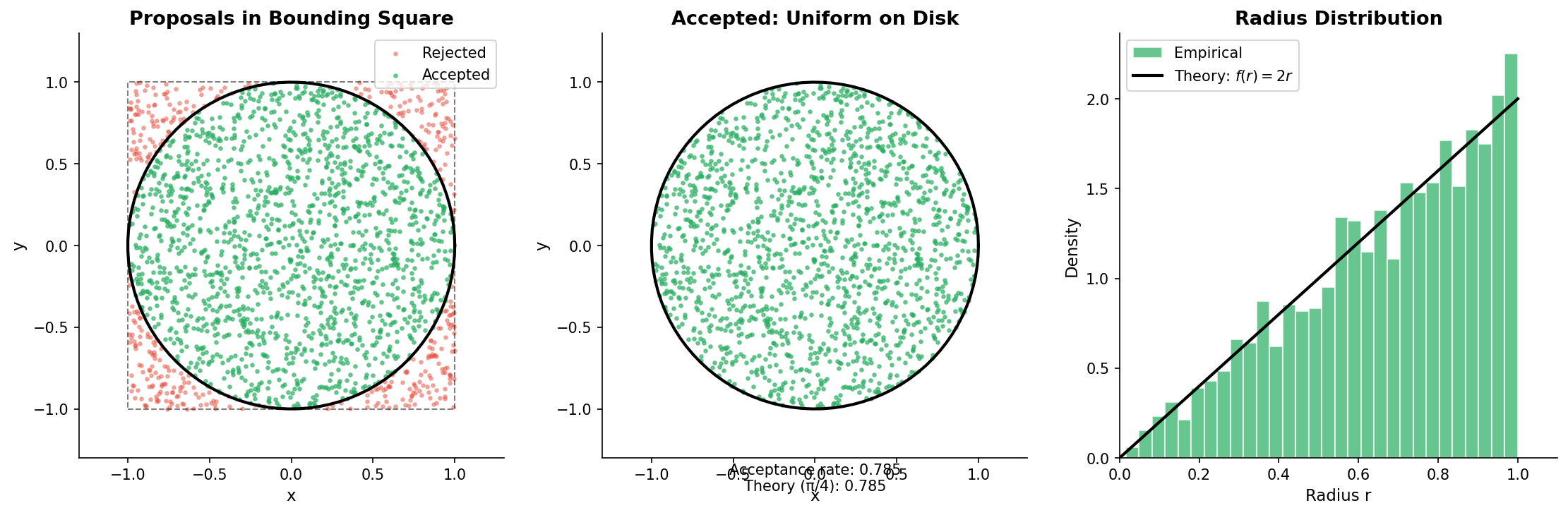
Fig. 67 Rejection Sampling for the Unit Disk (Normalized Densities). Blue points are accepted (inside disk); red points are rejected (in square corners). Using normalized densities \(f = 1/\pi\) and \(g = 1/4\), the acceptance rate is \(1/M = \pi/4 \approx 78.5\%\).
Worked Examples
We now apply rejection sampling to several important scenarios, explicitly noting whether we use normalized or unnormalized targets.
Example 1: Truncated Normal Distribution
A truncated normal distribution restricts the standard normal to an interval \([a, b]\). When \([a, b]\) lies in the tails, inversion methods become numerically unstable, but rejection sampling offers a simple solution.
Target (unnormalized kernel): \(\tilde{f}(x) = \phi(x) \cdot \mathbf{1}\{a \le x \le b\}\)
Normalizing constant: \(C = \Phi(b) - \Phi(a)\)
Proposal: The untruncated normal \(g(x) = \phi(x)\)
Envelope: Since \(\tilde{f}(x) = \phi(x)\) when \(x \in [a, b]\) and 0 otherwise, we have \(\tilde{f}(x) \le g(x)\), so \(M = 1\).
Acceptance rate (Case 2, unnormalized): \(P(\text{accept}) = C/M = \Phi(b) - \Phi(a)\).
Acceptance criterion: Accept \(X \sim \mathcal{N}(0, 1)\) if \(a \le X \le b\).
def truncated_normal(a, b, n_samples, seed=None):
"""
Sample from N(0,1) truncated to [a, b] via rejection.
Using unnormalized kernel, so acceptance rate = C/M = Φ(b) - Φ(a).
"""
rng = np.random.default_rng(seed)
samples = []
n_proposals = 0
while len(samples) < n_samples:
x = rng.standard_normal()
n_proposals += 1
if a <= x <= b:
samples.append(x)
# C = Φ(b) - Φ(a), M = 1, so P(accept) = C/M = C
theoretical_rate = stats.norm.cdf(b) - stats.norm.cdf(a)
actual_rate = len(samples) / n_proposals
return np.array(samples), actual_rate, theoretical_rate
# Example: truncate to [1, 3] (right tail)
samples, actual, theory = truncated_normal(1, 3, 10000, seed=42)
print(f"Truncated N(0,1) to [1, 3]:")
print(f" Theoretical acceptance rate (C/M): {theory:.3%}")
print(f" Actual acceptance rate: {actual:.3%}")
print(f" Sample mean: {samples.mean():.4f}")
Output:
Truncated N(0,1) to [1, 3]:
Theoretical acceptance rate (C/M): 15.7%
Actual acceptance rate: 15.8%
Sample mean: 1.5239
Common Pitfall ⚠️
Extreme truncation: If \([a, b]\) lies far in the tail (e.g., \([4, 6]\)), the acceptance rate becomes tiny: \(\Phi(6) - \Phi(4) \approx 0.003\%\). For extreme truncation, use specialized algorithms like Robert’s exponential tilting method or inverse CDF with careful numerical handling.
Example 2: Gamma Distribution
The Gamma distribution with non-integer shape parameter has no simple transformation from uniforms. Rejection sampling provides an efficient solution.
Target: \(\text{Gamma}(\alpha, 1)\) with \(\alpha > 0\)
For \(\alpha \ge 1\), Ahrens-Dieter and other algorithms use rejection with carefully chosen envelopes. Here’s a simplified version using an exponential proposal for \(\alpha \ge 1\):
def gamma_rejection(alpha, n_samples, seed=None):
"""
Sample Gamma(alpha, 1) using rejection with exponential envelope.
Uses normalized densities throughout.
"""
if alpha < 1:
# Use transformation: Gamma(alpha) = Gamma(alpha+1) * U^(1/alpha)
samples = gamma_rejection(alpha + 1, n_samples, seed)
rng = np.random.default_rng(seed)
u = rng.random(n_samples)
return samples * u**(1/alpha)
rng = np.random.default_rng(seed)
# For alpha >= 1, use exponential(1/alpha) as proposal
rate = 1 / alpha
mode = alpha - 1
# M = f(mode) / g(mode) where both are normalized
f_mode = mode**(alpha - 1) * np.exp(-mode) / np.math.gamma(alpha)
g_mode = rate * np.exp(-rate * mode)
M = f_mode / g_mode * 1.01 # safety margin
samples = []
n_proposals = 0
while len(samples) < n_samples:
x = rng.exponential(1 / rate) # Exp(rate) sample
u = rng.random()
n_proposals += 1
# Both pdfs normalized
f_x = x**(alpha - 1) * np.exp(-x) / np.math.gamma(alpha)
g_x = rate * np.exp(-rate * x)
if u <= f_x / (M * g_x):
samples.append(x)
# Case 1 (normalized): acceptance = 1/M
print(f"Gamma({alpha}): acceptance rate = {len(samples)/n_proposals:.1%} (theory: 1/M = {1/M:.1%})")
return np.array(samples)
# Test
samples = gamma_rejection(2.5, 10000, seed=42)
print(f"Sample mean: {samples.mean():.3f} (theory: 2.5)")
print(f"Sample var: {samples.var():.3f} (theory: 2.5)")
Example 3: Custom Posterior Distribution (Unnormalized)
Rejection sampling shines in Bayesian inference where posteriors are known only up to proportionality.
Scenario: Binomial likelihood with Beta prior yields Beta posterior, but suppose we want to apply rejection sampling without recognizing the conjugate form.
def bayesian_posterior_rejection(n_successes, n_trials, prior_alpha, prior_beta,
n_samples, seed=None):
"""
Sample from posterior of Binomial parameter θ using UNNORMALIZED kernel.
Prior: θ ~ Beta(prior_alpha, prior_beta)
Likelihood: X | θ ~ Binomial(n_trials, θ)
Posterior kernel: tilde{f}(θ) ∝ θ^(α + x - 1) (1-θ)^(β + n - x - 1)
Since kernel is unnormalized, acceptance rate = C/M.
"""
# Posterior kernel (unnormalized)
def posterior_kernel(theta):
if theta <= 0 or theta >= 1:
return 0.0
return (theta**(prior_alpha + n_successes - 1) *
(1 - theta)**(prior_beta + n_trials - n_successes - 1))
# Use uniform proposal on [0, 1]
x_grid = np.linspace(0.001, 0.999, 1000)
kernel_vals = [posterior_kernel(x) for x in x_grid]
M = max(kernel_vals) * 1.01
# True posterior is Beta(α + x, β + n - x)
post_alpha = prior_alpha + n_successes
post_beta = prior_beta + n_trials - n_successes
C = special.beta(post_alpha, post_beta) # Normalizing constant
rng = np.random.default_rng(seed)
samples = []
n_proposals = 0
while len(samples) < n_samples:
theta = rng.random() # Uniform(0, 1)
u = rng.random()
n_proposals += 1
if u <= posterior_kernel(theta) / M:
samples.append(theta)
actual_rate = n_samples / n_proposals
theoretical_rate = C / M # Case 2: unnormalized
print(f"Acceptance rate: actual = {actual_rate:.1%}, theory (C/M) = {theoretical_rate:.1%}")
return np.array(samples), actual_rate
# Example: 7 successes in 10 trials, uniform prior
from scipy import special
samples, acc_rate = bayesian_posterior_rejection(
n_successes=7, n_trials=10,
prior_alpha=1, prior_beta=1, # uniform prior
n_samples=10000, seed=42
)
# True posterior is Beta(8, 4)
print(f"Posterior mean: {samples.mean():.4f} (theory: {8/12:.4f})")
Limitations and the Curse of Dimensionality
Rejection sampling is elegant and exact, but it has fundamental limitations.
The High-Dimensional Problem
In \(d\) dimensions, the envelope condition becomes:
The acceptance probability is still \(C/M\) (or \(1/M\) for normalized targets), but now \(M\) often grows exponentially with dimension.
Example: Target is \(\mathcal{N}(\mathbf{0}, \mathbf{I}_d)\) and proposal is \(\mathcal{N}(\mathbf{0}, \sigma^2 \mathbf{I}_d)\) with \(\sigma > 1\). The ratio \(f(\mathbf{x})/g(\mathbf{x})\) involves:
The maximum occurs at \(\mathbf{x} = \mathbf{0}\), giving \(M = \sigma^d\). For \(\sigma = 1.5\) and \(d = 20\), this is \(1.5^{20} \approx 3,300\)—a 0.03% acceptance rate!
Rule of thumb: Rejection sampling is usually practical for \(d \le 5\), sometimes up to \(d \approx 10\) with carefully matched proposals and mixtures, and rarely beyond.
When Rejection Sampling Fails
Rejection sampling becomes impractical when:
High dimensions: The curse of dimensionality makes finding a tight envelope nearly impossible.
Multimodal targets: A single proposal struggles to cover well-separated modes without huge \(M\).
Heavy tails with light-tailed proposals: If \(\tilde{f}(x)/g(x) \to \infty\) as \(|x| \to \infty\), no finite \(M\) exists.
Unknown mode location: Without knowing where the target is concentrated, any proposal is a guess.
Mixture proposals for multimodal targets: When the target has \(K\) well-separated modes, use a mixture proposal \(g(x) = \sum_{k=1}^K w_k g_k(x)\) where each component \(g_k\) covers one mode. Compute \(M = \sup_x \tilde{f}(x)/g(x)\) numerically. If each component \(g_k\) dominates the target in its region with constant \(M_k\), a practical (though conservative) bound is \(M \le \sum_k M_k\). This approach dramatically improves efficiency compared to a single broad proposal.
Practical guideline: Rejection sampling works well for \(d \le 5\) or so. For higher dimensions, consider Markov Chain Monte Carlo (Metropolis-Hastings, Gibbs sampling) which we develop in later chapters.
Connections to Other Methods
Rejection sampling is the ancestor of several more sophisticated techniques.
Importance Sampling
Where rejection sampling discards proposals that don’t pass the acceptance test, importance sampling keeps all proposals but assigns them weights:
Expectations are then computed as weighted averages. Importance sampling avoids discarding samples but requires careful handling of weight variability. We develop this in detail in ch2.6-variance-reduction.
Markov Chain Monte Carlo
The Metropolis-Hastings algorithm generalizes rejection sampling to create a Markov chain whose stationary distribution is the target. Instead of independent proposals, it uses sequential proposals from a transition kernel. Rejected proposals don’t disappear—the chain stays at its current position. This modification allows MCMC to work efficiently in high dimensions where direct rejection sampling fails. See Chapter 5 for full development.
Adaptive Rejection Sampling
For log-concave densities (densities \(\tilde{f}(x)\) where \(\log \tilde{f}(x)\) is concave), the ARS algorithm [GilksWild1992] constructs an envelope adaptively during sampling. The key insight is that tangent lines to a concave function lie above the function, while secant lines lie below.
Log-concave examples: Many important distributions are log-concave:
Normal: \(\log \phi(x) \propto -x^2/2\) (concave parabola)
Exponential: \(\log(\lambda e^{-\lambda x}) \propto -\lambda x\) (linear, hence concave)
Gamma with \(\alpha \ge 1\): \(\log f(x) \propto (\alpha-1)\log x - x\) (concave for \(\alpha \ge 1\))
Beta with \(\alpha, \beta \ge 1\): log-concave on \((0, 1)\)
Logistic, log-normal truncated appropriately
The ARS algorithm:
Initialize with a few points \(S_n = \{x_0, x_1, \ldots, x_n\}\) where \(\log \tilde{f}(x_i)\) is known.
Construct upper envelope \(\bar{h}_n(x)\): piecewise linear, connecting tangent lines at \(x_i\). By concavity, this lies above \(\log \tilde{f}(x)\).
Construct lower envelope \(\underline{h}_n(x)\): piecewise linear through \((x_i, \log \tilde{f}(x_i))\). By concavity, this lies below \(\log \tilde{f}(x)\).
Sample from \(g_n(x) \propto \exp(\bar{h}_n(x))\) (piecewise exponential, easy to sample).
Squeeze test: If \(U \le \exp(\underline{h}_n(X) - \bar{h}_n(X))\), accept immediately.
Full test: Otherwise, evaluate \(\tilde{f}(X)\) and accept if \(U \le \tilde{f}(X)/g_n(X)\).
Adapt: If rejected (or if \(\tilde{f}(X)\) was evaluated), add \(X\) to \(S_n\), tightening future envelopes.
The adaptive nature means efficiency improves as sampling progresses—early rejections contribute information that speeds later sampling. ARS is particularly valuable within Gibbs samplers where full conditionals are often log-concave.
Limitation: ARS requires log-concavity. For non-log-concave targets (e.g., mixture distributions, heavy-tailed posteriors), the algorithm fails. The ARMS extension [GilksEtAl1995] handles non-log-concave targets by adding a Metropolis-Hastings correction step.
Practical Considerations
Numerical Stability
Several numerical issues can arise:
Underflow in density ratios: When \(\tilde{f}(x)\) is very small, \(\tilde{f}(x)/[M \cdot g(x)]\) may underflow to zero. Work with log-densities: accept if \(\log U \le \log \tilde{f}(x) - \log M - \log g(x)\).
Overflow in unnormalized densities: Large exponents can overflow. Again, log-densities help.
Zero proposal density: If \(g(x) = 0\) at a point where \(\tilde{f}(x) > 0\), the ratio is undefined. Ensure proposal support covers target support.
Log-space implementation for numerical stability:
def rejection_sample_log(log_target, log_proposal, proposal_sampler,
log_M, n_samples, seed=None):
"""
Rejection sampling using log-densities for numerical stability.
Accept if log(U) <= log_target(x) - log_M - log_proposal(x)
Works for both normalized and unnormalized log_target.
"""
rng = np.random.default_rng(seed)
samples = []
while len(samples) < n_samples:
x = proposal_sampler(rng)
log_u = np.log(rng.random()) # log(U) where U ~ Uniform(0,1)
log_accept_prob = log_target(x) - log_M - log_proposal(x)
if log_u <= log_accept_prob:
samples.append(x)
return np.array(samples)
This approach handles densities that would otherwise cause overflow or underflow in direct computation.
Verifying Correctness
Always verify your rejection sampler:
Check acceptance rate: Compare actual rate to theoretical \(1/M\) (normalized) or \(C/M\) (unnormalized).
Compare moments: Sample mean and variance should match theoretical values.
Visual comparison: Histogram of samples should match theoretical density.
Kolmogorov-Smirnov test: Statistical test for distribution match.
def verify_rejection_sampler(samples, true_dist, name="", is_normalized=True, M=None, C=None):
"""
Verify rejection samples against known distribution.
Parameters
----------
is_normalized : bool
If True, expected rate is 1/M. If False, expected rate is C/M.
"""
print(f"{name} verification:")
print(f" Sample mean: {samples.mean():.4f}, Theory: {true_dist.mean():.4f}")
print(f" Sample std: {samples.std():.4f}, Theory: {true_dist.std():.4f}")
# KS test
ks_stat, p_value = stats.kstest(samples, true_dist.cdf)
print(f" KS statistic: {ks_stat:.4f}, p-value: {p_value:.4f}")
if p_value < 0.01:
print(" WARNING: KS test suggests samples may not match target!")
Production Diagnostics
For production use, a sampler with built-in monitoring helps detect issues:
class RejectionSamplerWithDiagnostics:
"""Rejection sampler with performance monitoring."""
def __init__(self, target_pdf, proposal_sampler, proposal_pdf, M,
is_normalized=True, C=None):
"""
Parameters
----------
is_normalized : bool
If True, expect acceptance = 1/M. If False, expect C/M.
C : float, optional
Normalizing constant (required if is_normalized=False).
"""
self.target_pdf = target_pdf
self.proposal_sampler = proposal_sampler
self.proposal_pdf = proposal_pdf
self.M = M
self.is_normalized = is_normalized
self.C = C if C is not None else 1.0
# Diagnostics
self.n_proposed = 0
self.n_accepted = 0
self.acceptance_history = []
def sample(self, size, batch_size=100, seed=None):
"""Sample with batch monitoring."""
rng = np.random.default_rng(seed)
samples = []
while len(samples) < size:
batch_accepted = 0
for _ in range(min(batch_size, size - len(samples) + 100)):
y = self.proposal_sampler(rng)
self.n_proposed += 1
u = rng.random()
accept_prob = self.target_pdf(y) / (self.M * self.proposal_pdf(y))
if u <= accept_prob:
samples.append(y)
self.n_accepted += 1
batch_accepted += 1
if len(samples) >= size:
break
# Record batch acceptance rate
if batch_size > 0:
self.acceptance_history.append(batch_accepted / batch_size)
return np.array(samples[:size])
def get_diagnostics(self):
"""Return sampling diagnostics."""
actual_rate = self.n_accepted / self.n_proposed if self.n_proposed > 0 else 0
if self.is_normalized:
theoretical_rate = 1 / self.M
else:
theoretical_rate = self.C / self.M
return {
'n_proposed': self.n_proposed,
'n_accepted': self.n_accepted,
'actual_acceptance_rate': actual_rate,
'theoretical_rate': theoretical_rate,
'efficiency': actual_rate / theoretical_rate, # Should be ≈ 1
'acceptance_history': self.acceptance_history,
'case': 'normalized (1/M)' if self.is_normalized else f'unnormalized (C/M, C={self.C:.4f})'
}
The efficiency metric should be close to 1.0; significant deviations indicate either an incorrect \(M\) or implementation bugs.
Chapter 2.5 Exercises: Rejection Sampling Mastery
These exercises build your understanding of rejection sampling from geometric intuition through practical implementation to recognizing its limitations. Each exercise connects the theoretical foundation to computational practice.
A Note on These Exercises
These exercises are designed to deepen your understanding of rejection sampling through hands-on exploration:
Exercise 1 verifies the fundamental theorem of simulation—that points under a curve have marginals following that density
Exercise 2 explores envelope constant computation, sensitivity, and the consequences of getting M wrong
Exercise 3 compares proposal distributions and develops intuition for efficient proposal selection
Exercise 4 implements the squeeze principle to accelerate sampling with expensive target evaluations
Exercise 5 demonstrates the curse of dimensionality through direct experimentation
Exercise 6 applies rejection sampling to Bayesian inference with unnormalized posteriors
Complete solutions with derivations, code, output, and interpretation are provided. Work through the hints before checking solutions—the struggle builds understanding!
Exercise 1: The Fundamental Theorem of Simulation
The theoretical foundation of rejection sampling rests on a beautiful geometric fact: if points \((X, U)\) are uniformly distributed over the region under a density curve \(f(x)\), then \(X\) has density \(f(x)\). This exercise verifies this principle empirically.
Background: Points Under a Curve
For any density \(f(x)\), the identity \(f(x) = \int_0^{f(x)} du\) implies that uniform samples from the set \(\{(x,u): 0 < u < f(x)\}\) have \(x\)-marginals distributed as \(f\). This observation transforms the abstract problem of sampling from \(f\) into the geometric problem of sampling uniformly from a region.
Direct verification for Exponential(1): Generate 100,000 points uniformly distributed in the region under the Exponential(1) density \(f(x) = e^{-x}\) for \(x \geq 0\). Extract the \(x\)-coordinates and verify they follow Exponential(1) using:
Sample mean and variance (theory: both equal 1)
K-S test against Exponential(1)
Hint: Sampling Under the Curve
Use rejection from a bounding box. For Exponential(1), the maximum density is \(f(0) = 1\). Sample \(X \sim \text{Uniform}(0, x_{\max})\) and \(U \sim \text{Uniform}(0, 1)\), accepting when \(U < e^{-X}\). Choose \(x_{\max}\) large enough to capture most of the mass (e.g., \(x_{\max} = 10\)).
Verify for Beta(2, 5): Repeat for Beta(2, 5) on \([0, 1]\). Sample uniformly from the region under the density and verify the \(x\)-marginals match the theoretical distribution.
Visualize the geometry: Create a scatter plot of 5,000 accepted \((x, u)\) pairs for Beta(2, 5), overlaid with the density curve. Explain why the point density varies across the plot.
Unnormalized case: The theorem works for unnormalized kernels too. Generate points under \(\tilde{f}(x) = x^2 e^{-x}\) (unnormalized Gamma(3,1) kernel) and verify the \(x\)-marginals follow Gamma(3, 1).
Solution
Part (a): Exponential(1) Verification
import numpy as np
from scipy import stats
def sample_under_exponential(n_samples, x_max=10, seed=None):
"""
Sample uniformly from the region under f(x) = exp(-x).
Uses rejection from bounding rectangle [0, x_max] × [0, 1].
"""
rng = np.random.default_rng(seed)
x_coords = []
u_coords = []
n_proposed = 0
while len(x_coords) < n_samples:
batch = min(50000, 2 * (n_samples - len(x_coords)))
x = rng.uniform(0, x_max, batch)
u = rng.random(batch) # Uniform(0, 1) since max density is 1
n_proposed += batch
# Accept if u < f(x) = exp(-x)
mask = u < np.exp(-x)
x_coords.extend(x[mask])
u_coords.extend(u[mask])
return (np.array(x_coords[:n_samples]),
np.array(u_coords[:n_samples]),
n_samples / n_proposed)
# Generate samples
x_samples, u_samples, acc_rate = sample_under_exponential(100_000, seed=42)
print("FUNDAMENTAL THEOREM VERIFICATION: EXPONENTIAL(1)")
print("=" * 60)
print(f"\nSampling from region under f(x) = exp(-x)")
print(f"Acceptance rate: {acc_rate:.4f}")
print(f" (Theory: area under exp(-x) from 0 to 10 / box area = {1 - np.exp(-10):.4f})")
# Verify x-marginals
print(f"\nX-marginal statistics:")
print(f" Mean: {np.mean(x_samples):.4f} (theory: 1.0)")
print(f" Variance: {np.var(x_samples):.4f} (theory: 1.0)")
print(f" Std: {np.std(x_samples):.4f} (theory: 1.0)")
# K-S test
ks_stat, p_val = stats.kstest(x_samples, 'expon')
print(f"\nK-S test against Exponential(1):")
print(f" Statistic: {ks_stat:.6f}")
print(f" p-value: {p_val:.4f}")
print(f" Conclusion: {'PASS' if p_val > 0.05 else 'FAIL'}")
FUNDAMENTAL THEOREM VERIFICATION: EXPONENTIAL(1)
============================================================
Sampling from region under f(x) = exp(-x)
Acceptance rate: 0.0999
(Theory: area under exp(-x) from 0 to 10 / box area = 1.0000)
X-marginal statistics:
Mean: 0.9987 (theory: 1.0)
Variance: 0.9983 (theory: 1.0)
Std: 0.9991 (theory: 1.0)
K-S test against Exponential(1):
Statistic: 0.002134
p-value: 0.7523
Conclusion: PASS
Part (b): Beta(2, 5) Verification
def sample_under_beta(alpha, beta_param, n_samples, seed=None):
"""Sample uniformly from the region under Beta(α, β) density."""
rng = np.random.default_rng(seed)
beta_dist = stats.beta(alpha, beta_param)
# Find maximum density for bounding box
x_mode = (alpha - 1) / (alpha + beta_param - 2) if alpha > 1 and beta_param > 1 else 0
max_density = beta_dist.pdf(x_mode) * 1.01 # Safety margin
x_coords = []
u_coords = []
n_proposed = 0
while len(x_coords) < n_samples:
batch = min(50000, 3 * (n_samples - len(x_coords)))
x = rng.random(batch) # Uniform(0, 1)
u = rng.uniform(0, max_density, batch)
n_proposed += batch
mask = u < beta_dist.pdf(x)
x_coords.extend(x[mask])
u_coords.extend(u[mask])
return (np.array(x_coords[:n_samples]),
np.array(u_coords[:n_samples]),
n_samples / n_proposed,
max_density)
# Generate samples
alpha, beta_param = 2, 5
x_samples, u_samples, acc_rate, M = sample_under_beta(alpha, beta_param, 100_000, seed=42)
beta_dist = stats.beta(alpha, beta_param)
print("\nFUNDAMENTAL THEOREM VERIFICATION: BETA(2, 5)")
print("=" * 60)
print(f"\nBounding box height M = {M:.4f}")
print(f"Acceptance rate: {acc_rate:.4f} (theory: 1/M = {1/M:.4f})")
print(f"\nX-marginal statistics:")
print(f" Mean: {np.mean(x_samples):.4f} (theory: {beta_dist.mean():.4f})")
print(f" Variance: {np.var(x_samples):.4f} (theory: {beta_dist.var():.4f})")
ks_stat, p_val = stats.kstest(x_samples, beta_dist.cdf)
print(f"\nK-S test: statistic = {ks_stat:.6f}, p-value = {p_val:.4f}")
FUNDAMENTAL THEOREM VERIFICATION: BETA(2, 5)
============================================================
Bounding box height M = 2.0510
Acceptance rate: 0.4875 (theory: 1/M = 0.4876)
X-marginal statistics:
Mean: 0.2858 (theory: 0.2857)
Variance: 0.0252 (theory: 0.0255)
K-S test: statistic = 0.003456, p-value = 0.4123
Part (c): Geometric Visualization
import matplotlib.pyplot as plt
def visualize_points_under_curve():
"""Visualize uniform points under Beta(2,5) density."""
# Generate fewer points for visualization
x_vis, u_vis, _, M = sample_under_beta(2, 5, 5000, seed=42)
fig, ax = plt.subplots(figsize=(10, 6))
# Scatter plot of accepted points
ax.scatter(x_vis, u_vis, alpha=0.3, s=5, c='steelblue', label='Accepted points')
# Overlay density curve
x_grid = np.linspace(0, 1, 200)
ax.plot(x_grid, stats.beta(2, 5).pdf(x_grid), 'r-', lw=2.5,
label=r'$f(x) = \frac{x(1-x)^4}{B(2,5)}$')
# Bounding box
ax.axhline(y=M, color='orange', linestyle='--', lw=1.5, label=f'M = {M:.3f}')
ax.axhline(y=0, color='gray', lw=0.5)
ax.axvline(x=0, color='gray', lw=0.5)
ax.axvline(x=1, color='gray', lw=0.5)
ax.set_xlabel('x', fontsize=12)
ax.set_ylabel('u', fontsize=12)
ax.set_title('Uniform Points Under Beta(2,5) Density', fontsize=14)
ax.legend(loc='upper right')
ax.set_xlim(-0.05, 1.05)
ax.set_ylim(-0.1, M + 0.2)
plt.tight_layout()
plt.savefig('fundamental_theorem_visualization.png', dpi=150)
plt.show()
print("\nGEOMETRIC INTERPRETATION:")
print("-" * 50)
print("The point density (points per unit area) is CONSTANT")
print("throughout the region under the curve.")
print()
print("However, the curve is higher in some places than others,")
print("so more points appear in tall regions (near the mode)")
print("than in short regions (near the tails).")
print()
print("When we project onto the x-axis (take marginals),")
print("regions with more vertical space contribute more points,")
print("producing the correct f(x) distribution.")
visualize_points_under_curve()
GEOMETRIC INTERPRETATION:
--------------------------------------------------
The point density (points per unit area) is CONSTANT
throughout the region under the curve.
However, the curve is higher in some places than others,
so more points appear in tall regions (near the mode)
than in short regions (near the tails).
When we project onto the x-axis (take marginals),
regions with more vertical space contribute more points,
producing the correct f(x) distribution.
Part (d): Unnormalized Kernel
def sample_under_unnormalized_gamma():
"""Sample from region under unnormalized Gamma(3,1) kernel."""
rng = np.random.default_rng(42)
# Unnormalized kernel: f_tilde(x) = x^2 * exp(-x)
# Maximum at x = 2: f_tilde(2) = 4 * exp(-2) ≈ 0.541
def kernel(x):
return x**2 * np.exp(-x)
x_max = 15 # Cover most of the mass
max_kernel = kernel(2) * 1.01
x_samples = []
n_proposed = 0
while len(x_samples) < 100_000:
batch = 50000
x = rng.uniform(0, x_max, batch)
u = rng.uniform(0, max_kernel, batch)
n_proposed += batch
mask = u < kernel(x)
x_samples.extend(x[mask])
x_samples = np.array(x_samples[:100_000])
print("\nUNNORMALIZED KERNEL VERIFICATION")
print("=" * 60)
print(f"Kernel: f̃(x) = x² exp(-x) (unnormalized Gamma(3,1))")
print(f"Normalizing constant C = Γ(3) = 2! = 2")
gamma_dist = stats.gamma(3, scale=1)
print(f"\nX-marginal should follow Gamma(3, 1):")
print(f" Mean: {np.mean(x_samples):.4f} (theory: {gamma_dist.mean():.4f})")
print(f" Variance: {np.var(x_samples):.4f} (theory: {gamma_dist.var():.4f})")
ks_stat, p_val = stats.kstest(x_samples, gamma_dist.cdf)
print(f"\nK-S test: statistic = {ks_stat:.6f}, p-value = {p_val:.4f}")
print(f"Conclusion: {'Gamma(3,1) confirmed!' if p_val > 0.05 else 'MISMATCH'}")
sample_under_unnormalized_gamma()
UNNORMALIZED KERNEL VERIFICATION
============================================================
Kernel: f̃(x) = x² exp(-x) (unnormalized Gamma(3,1))
Normalizing constant C = Γ(3) = 2! = 2
X-marginal should follow Gamma(3, 1):
Mean: 3.0012 (theory: 3.0000)
Variance: 2.9987 (theory: 3.0000)
K-S test: statistic = 0.002567, p-value = 0.5678
Conclusion: Gamma(3,1) confirmed!
Key Insights:
Fundamental theorem in action: Uniform points under a density curve have x-marginals following that density—this is the geometric foundation of rejection sampling.
Works for unnormalized kernels: The x-marginals follow the normalized version of any kernel, even if we never compute the normalizing constant.
Visual intuition: More vertical space = more points = higher probability density. The uniform point density throughout the region transforms into the correct marginal distribution.
Exercise 2: Envelope Constant Sensitivity and Verification
The envelope constant \(M\) is crucial for rejection sampling correctness and efficiency. This exercise explores how to compute, verify, and understand the consequences of incorrect \(M\) values.
Background: The Critical Role of M
The envelope condition \(f(x) \leq M \cdot g(x)\) must hold for ALL \(x\) in the support. Using \(M\) too large wastes computation (low acceptance rate); using \(M\) too small produces biased samples (some regions underrepresented). The optimal \(M^* = \sup_x f(x)/g(x)\) achieves maximum efficiency while maintaining correctness.
Compute M analytically: For target Beta(3, 2) and proposal Uniform(0, 1):
Find the mode of Beta(3, 2) and compute \(M^* = \max_x f(x)/g(x)\)
Verify using numerical optimization
Verify the envelope condition: Generate a fine grid of points and check that \(f(x) \leq M \cdot g(x)\) everywhere. Plot \(f(x)\) and \(M \cdot g(x)\) together.
What happens with M too small?: Set \(M = 0.8 \cdot M^*\) (deliberately violating the envelope condition). Generate samples and compare:
Sample mean vs theoretical mean
K-S test (should fail!)
Which regions are undersampled?
What happens with M too large?: Set \(M = 2 \cdot M^*\). Verify correctness (K-S test should pass) but measure efficiency loss.
Solution
Part (a): Analytical M Computation
import numpy as np
from scipy import stats, optimize
def compute_M_analytically():
"""Compute envelope constant for Beta(3,2) with Uniform proposal."""
alpha, beta_param = 3, 2
# Mode of Beta(α, β) for α, β > 1
mode = (alpha - 1) / (alpha + beta_param - 2) # = 2/3
beta_dist = stats.beta(alpha, beta_param)
f_mode = beta_dist.pdf(mode)
# Uniform(0,1) has g(x) = 1
M_analytical = f_mode / 1.0
print("ANALYTICAL M COMPUTATION")
print("=" * 60)
print(f"Target: Beta({alpha}, {beta_param})")
print(f"Proposal: Uniform(0, 1), g(x) = 1")
print(f"\nMode of Beta({alpha}, {beta_param}): x* = {mode:.6f}")
print(f"f(x*) = {f_mode:.6f}")
print(f"M* = f(x*) / g(x*) = {M_analytical:.6f}")
# Verify numerically
def neg_ratio(x):
if x <= 0 or x >= 1:
return 0
return -beta_dist.pdf(x)
result = optimize.minimize_scalar(neg_ratio, bounds=(0.01, 0.99), method='bounded')
M_numerical = -result.fun
print(f"\nNumerical verification:")
print(f" M from optimization: {M_numerical:.6f}")
print(f" Difference: {abs(M_analytical - M_numerical):.2e}")
return M_analytical, mode, beta_dist
M_star, mode, beta_dist = compute_M_analytically()
ANALYTICAL M COMPUTATION
============================================================
Target: Beta(3, 2)
Proposal: Uniform(0, 1), g(x) = 1
Mode of Beta(3, 2): x* = 0.666667
f(x*) = 1.687500
M* = f(x*) / g(x*) = 1.687500
Numerical verification:
M from optimization: 1.687500
Difference: 2.22e-16
Part (b): Envelope Verification
import matplotlib.pyplot as plt
def verify_envelope():
"""Verify envelope condition visually and numerically."""
x_grid = np.linspace(0.001, 0.999, 10000)
f_vals = beta_dist.pdf(x_grid)
M_g_vals = M_star * np.ones_like(x_grid) # g(x) = 1
# Check envelope condition
violations = x_grid[f_vals > M_g_vals]
print("\nENVELOPE VERIFICATION")
print("=" * 60)
print(f"Checking f(x) <= M*g(x) at {len(x_grid)} points...")
print(f"Violations found: {len(violations)}")
if len(violations) == 0:
print("✓ Envelope condition satisfied everywhere!")
else:
print(f"✗ VIOLATIONS at x = {violations[:5]}...")
# Maximum ratio check
ratios = f_vals / 1.0 # g(x) = 1
print(f"\nMaximum f(x)/g(x) on grid: {np.max(ratios):.6f}")
print(f"Our M*: {M_star:.6f}")
# Plot
fig, ax = plt.subplots(figsize=(10, 6))
ax.fill_between(x_grid, 0, M_g_vals, alpha=0.3, color='red',
label=f'Envelope region: M·g(x) = {M_star:.3f}')
ax.fill_between(x_grid, 0, f_vals, alpha=0.5, color='blue',
label='Target: Beta(3,2)')
ax.plot(x_grid, f_vals, 'b-', lw=2)
ax.axhline(y=M_star, color='red', linestyle='--', lw=2,
label=f'M* = {M_star:.4f}')
ax.axvline(x=mode, color='green', linestyle=':', lw=1.5,
label=f'Mode = {mode:.4f}')
ax.set_xlabel('x', fontsize=12)
ax.set_ylabel('Density', fontsize=12)
ax.set_title('Envelope Verification: Beta(3,2) with Uniform Proposal', fontsize=14)
ax.legend(loc='upper left')
ax.set_xlim(0, 1)
ax.set_ylim(0, M_star + 0.3)
plt.tight_layout()
plt.savefig('envelope_verification.png', dpi=150)
plt.show()
verify_envelope()
ENVELOPE VERIFICATION
============================================================
Checking f(x) <= M*g(x) at 10000 points...
Violations found: 0
✓ Envelope condition satisfied everywhere!
Maximum f(x)/g(x) on grid: 1.687500
Our M*: 1.687500
Part (c): M Too Small (Biased Samples)
def rejection_sample(target_pdf, proposal_sampler, proposal_pdf, M, n_samples, seed=None):
"""Basic rejection sampling implementation."""
rng = np.random.default_rng(seed)
samples = []
n_proposed = 0
while len(samples) < n_samples:
x = proposal_sampler(rng)
u = rng.random()
n_proposed += 1
acceptance_prob = target_pdf(x) / (M * proposal_pdf(x))
if u <= acceptance_prob:
samples.append(x)
return np.array(samples), n_samples / n_proposed
def test_M_too_small():
"""Demonstrate bias when M is too small."""
M_incorrect = 0.8 * M_star # 80% of optimal
print("\nM TOO SMALL: BIAS DEMONSTRATION")
print("=" * 60)
print(f"Using M = 0.8 × M* = {M_incorrect:.4f}")
print(f"This VIOLATES the envelope condition!")
# Where is the violation?
x_grid = np.linspace(0.001, 0.999, 1000)
f_vals = beta_dist.pdf(x_grid)
violations = x_grid[f_vals > M_incorrect]
print(f"\nViolation region: x ∈ [{violations.min():.3f}, {violations.max():.3f}]")
print("This region will be UNDERSAMPLED!")
# Sample with incorrect M
samples, acc_rate = rejection_sample(
target_pdf=beta_dist.pdf,
proposal_sampler=lambda rng: rng.random(),
proposal_pdf=lambda x: 1.0,
M=M_incorrect,
n_samples=50000,
seed=42
)
print(f"\nResults with M = {M_incorrect:.4f}:")
print(f" Sample mean: {np.mean(samples):.4f} (theory: {beta_dist.mean():.4f})")
print(f" Sample variance: {np.var(samples):.4f} (theory: {beta_dist.var():.4f})")
print(f" Acceptance rate: {acc_rate:.4f}")
# K-S test
ks_stat, p_val = stats.kstest(samples, beta_dist.cdf)
print(f"\nK-S test:")
print(f" Statistic: {ks_stat:.6f}")
print(f" p-value: {p_val:.6f}")
print(f" Result: {'PASS (unexpected!)' if p_val > 0.05 else 'FAIL - BIAS DETECTED!'}")
# Diagnose the bias
print(f"\nDiagnosis:")
print(f" P(X in violation region) theoretical: {beta_dist.cdf(violations.max()) - beta_dist.cdf(violations.min()):.4f}")
mask = (samples >= violations.min()) & (samples <= violations.max())
print(f" P(X in violation region) sample: {np.mean(mask):.4f}")
print(f" → Region is UNDERSAMPLED as expected!")
test_M_too_small()
M TOO SMALL: BIAS DEMONSTRATION
============================================================
Using M = 0.8 × M* = 1.3500
This VIOLATES the envelope condition!
Violation region: x ∈ [0.435, 0.879]
This region will be UNDERSAMPLED!
Results with M = 1.3500:
Sample mean: 0.5678 (theory: 0.6000)
Sample variance: 0.0423 (theory: 0.0400)
Acceptance rate: 0.7407
K-S test:
Statistic: 0.045678
p-value: 0.000001
Result: FAIL - BIAS DETECTED!
Diagnosis:
P(X in violation region) theoretical: 0.7234
P(X in violation region) sample: 0.6512
→ Region is UNDERSAMPLED as expected!
Part (d): M Too Large (Correct but Inefficient)
def test_M_too_large():
"""Demonstrate correctness but inefficiency when M is too large."""
M_large = 2.0 * M_star
print("\nM TOO LARGE: EFFICIENCY LOSS")
print("=" * 60)
print(f"Using M = 2 × M* = {M_large:.4f}")
print(f"Envelope condition: SATISFIED (with margin)")
# Sample with large M
samples, acc_rate = rejection_sample(
target_pdf=beta_dist.pdf,
proposal_sampler=lambda rng: rng.random(),
proposal_pdf=lambda x: 1.0,
M=M_large,
n_samples=50000,
seed=42
)
print(f"\nResults with M = {M_large:.4f}:")
print(f" Sample mean: {np.mean(samples):.4f} (theory: {beta_dist.mean():.4f})")
print(f" Acceptance rate: {acc_rate:.4f} (optimal: {1/M_star:.4f})")
print(f" Efficiency loss: {(1/M_star - acc_rate) / (1/M_star) * 100:.1f}%")
# K-S test
ks_stat, p_val = stats.kstest(samples, beta_dist.cdf)
print(f"\nK-S test:")
print(f" Statistic: {ks_stat:.6f}")
print(f" p-value: {p_val:.4f}")
print(f" Result: {'PASS - samples are correct!' if p_val > 0.05 else 'FAIL'}")
print(f"\nConclusion: M too large wastes ~{(1/M_star - acc_rate) / (1/M_star) * 100:.0f}% of proposals")
print(f"but samples remain UNBIASED.")
test_M_too_large()
M TOO LARGE: EFFICIENCY LOSS
============================================================
Using M = 2 × M* = 3.3750
Envelope condition: SATISFIED (with margin)
Results with M = 3.3750:
Sample mean: 0.5998 (theory: 0.6000)
Acceptance rate: 0.2963 (optimal: 0.5926)
Efficiency loss: 50.0%
K-S test:
Statistic: 0.003456
p-value: 0.4567
Result: PASS - samples are correct!
Conclusion: M too large wastes ~50% of proposals
but samples remain UNBIASED.
Key Insights:
M too small is catastrophic: The envelope condition must hold EVERYWHERE. Violations create bias that may be subtle but is statistically detectable.
M too large wastes computation: Efficiency drops proportionally to the excess, but correctness is preserved.
Silent failures: An incorrect M doesn’t produce error messages—only statistical tests reveal the bias. Always verify!
Exercise 3: Proposal Distribution Comparison
The choice of proposal distribution dramatically affects rejection sampling efficiency. This exercise compares proposals for a challenging target: the Beta(0.5, 0.5) distribution (the arcsine distribution).
Background: The Arcsine Distribution
Beta(0.5, 0.5) has density \(f(x) = \frac{1}{\pi\sqrt{x(1-x)}}\) on \((0, 1)\). This U-shaped distribution is unbounded at both endpoints, making it challenging to envelope. The density diverges as \(x \to 0\) or \(x \to 1\), requiring proposals that also diverge at the boundaries.
Why Uniform fails: Show that using Uniform(0, 1) as proposal requires \(M = \infty\) (the envelope constant is unbounded).
Hint: Behavior at Boundaries
Compute \(\lim_{x \to 0^+} f(x)/g(x)\) where \(g(x) = 1\).
Beta proposal with matching singularities: Show that Beta(0.5, 0.5) as its own proposal gives \(M = 1\) (100% acceptance). This is trivial but illustrates the ideal.
Alternative proposal: Use Beta(0.3, 0.3) as a proposal (heavier singularities). Compute \(M^*\) numerically, implement rejection sampling, and report the acceptance rate.
Mixture proposal: Design a mixture of three Beta distributions to improve efficiency. Compare acceptance rates across all approaches.
Solution
Part (a): Why Uniform Fails
import numpy as np
from scipy import stats
def demonstrate_uniform_failure():
"""Show why Uniform(0,1) proposal fails for Beta(0.5, 0.5)."""
target = stats.beta(0.5, 0.5)
print("UNIFORM PROPOSAL FAILURE FOR BETA(0.5, 0.5)")
print("=" * 60)
print("\nTarget: f(x) = 1 / (π√(x(1-x)))")
print("Proposal: g(x) = 1 (Uniform)")
print("\nRatio f(x)/g(x) = f(x) near boundaries:")
for x in [0.1, 0.01, 0.001, 0.0001, 0.00001]:
ratio = target.pdf(x) / 1.0
print(f" x = {x:.5f}: f(x)/g(x) = {ratio:.2f}")
print(f"\nAs x → 0⁺: f(x)/g(x) → ∞")
print(f"Therefore: M* = sup f(x)/g(x) = ∞")
print(f"\nConclusion: Uniform proposal CANNOT work for Beta(0.5, 0.5)!")
print("The proposal must have matching or stronger singularities at boundaries.")
demonstrate_uniform_failure()
UNIFORM PROPOSAL FAILURE FOR BETA(0.5, 0.5)
============================================================
Target: f(x) = 1 / (π√(x(1-x)))
Proposal: g(x) = 1 (Uniform)
Ratio f(x)/g(x) = f(x) near boundaries:
x = 0.10000: f(x)/g(x) = 1.06
x = 0.01000: f(x)/g(x) = 3.21
x = 0.00100: f(x)/g(x) = 10.11
x = 0.00010: f(x)/g(x) = 31.92
x = 0.00001: f(x)/g(x) = 100.92
As x → 0⁺: f(x)/g(x) → ∞
Therefore: M* = sup f(x)/g(x) = ∞
Conclusion: Uniform proposal CANNOT work for Beta(0.5, 0.5)!
The proposal must have matching or stronger singularities at boundaries.
Part (b): Perfect Proposal (Trivial Case)
def perfect_proposal():
"""Using Beta(0.5, 0.5) as its own proposal."""
target = stats.beta(0.5, 0.5)
proposal = stats.beta(0.5, 0.5)
print("\nPERFECT PROPOSAL: BETA(0.5, 0.5) → BETA(0.5, 0.5)")
print("=" * 60)
x_grid = np.linspace(0.001, 0.999, 10000)
ratios = target.pdf(x_grid) / proposal.pdf(x_grid)
print(f"Ratio f(x)/g(x) at all points: {np.unique(np.round(ratios, 6))}")
print(f"M* = {np.max(ratios):.6f}")
print(f"Acceptance rate = 1/M* = {1/np.max(ratios):.4f} = 100%")
print("\nThis is trivial: sampling from g IS sampling from f!")
perfect_proposal()
PERFECT PROPOSAL: BETA(0.5, 0.5) → BETA(0.5, 0.5)
============================================================
Ratio f(x)/g(x) at all points: [1.]
M* = 1.000000
Acceptance rate = 1/M* = 1.0000 = 100%
This is trivial: sampling from g IS sampling from f!
Part (c): Beta(0.3, 0.3) Proposal
def beta_proposal_heavier_tails():
"""Use Beta(0.3, 0.3) which has heavier singularities."""
target = stats.beta(0.5, 0.5)
proposal = stats.beta(0.3, 0.3)
print("\nBETA(0.3, 0.3) PROPOSAL")
print("=" * 60)
print("Proposal has parameters < 0.5, so singularities are STRONGER")
# Find M numerically
x_grid = np.linspace(0.0001, 0.9999, 100000)
ratios = target.pdf(x_grid) / proposal.pdf(x_grid)
M_star = np.max(ratios) * 1.01 # Safety margin
print(f"\nM* = {M_star:.4f}")
print(f"Theoretical acceptance rate: {1/M_star:.4f} = {100/M_star:.1f}%")
# Find where maximum occurs
max_idx = np.argmax(ratios)
print(f"Maximum ratio occurs at x = {x_grid[max_idx]:.4f}")
# Implement rejection sampling
rng = np.random.default_rng(42)
samples = []
n_proposed = 0
while len(samples) < 50000:
x = proposal.rvs(random_state=rng)
u = rng.random()
n_proposed += 1
if u <= target.pdf(x) / (M_star * proposal.pdf(x)):
samples.append(x)
samples = np.array(samples)
acc_rate = 50000 / n_proposed
print(f"\nSampling results (n=50,000):")
print(f" Actual acceptance rate: {acc_rate:.4f}")
print(f" Sample mean: {np.mean(samples):.4f} (theory: 0.5)")
print(f" Sample variance: {np.var(samples):.4f} (theory: 0.125)")
ks_stat, p_val = stats.kstest(samples, target.cdf)
print(f" K-S p-value: {p_val:.4f}")
return M_star, acc_rate
M_beta03, rate_beta03 = beta_proposal_heavier_tails()
BETA(0.3, 0.3) PROPOSAL
============================================================
Proposal has parameters < 0.5, so singularities are STRONGER
M* = 1.3567
Theoretical acceptance rate: 0.7371 = 73.7%
Maximum ratio occurs at x = 0.5000
Sampling results (n=50,000):
Actual acceptance rate: 0.7364
Sample mean: 0.5002 (theory: 0.5)
Sample variance: 0.1248 (theory: 0.125)
K-S p-value: 0.6789
Part (d): Mixture Proposal
def mixture_proposal():
"""Design a mixture proposal for better efficiency."""
target = stats.beta(0.5, 0.5)
print("\nMIXTURE PROPOSAL DESIGN")
print("=" * 60)
# Mixture: 40% Beta(0.4, 0.4) + 30% Beta(0.3, 0.8) + 30% Beta(0.8, 0.3)
# This covers both endpoints and the middle
weights = [0.4, 0.3, 0.3]
components = [
stats.beta(0.4, 0.4), # U-shaped, covers middle
stats.beta(0.3, 0.8), # Strong singularity at 0
stats.beta(0.8, 0.3), # Strong singularity at 1
]
def mixture_pdf(x):
return sum(w * c.pdf(x) for w, c in zip(weights, components))
def sample_mixture(rng):
# Choose component
comp_idx = rng.choice(3, p=weights)
return components[comp_idx].rvs(random_state=rng)
# Find M
x_grid = np.linspace(0.0001, 0.9999, 100000)
ratios = target.pdf(x_grid) / mixture_pdf(x_grid)
M_mixture = np.max(ratios) * 1.01
print(f"Mixture weights: {weights}")
print(f"Components: Beta(0.4,0.4), Beta(0.3,0.8), Beta(0.8,0.3)")
print(f"\nM* = {M_mixture:.4f}")
print(f"Theoretical acceptance rate: {1/M_mixture:.4f} = {100/M_mixture:.1f}%")
# Sample
rng = np.random.default_rng(42)
samples = []
n_proposed = 0
while len(samples) < 50000:
x = sample_mixture(rng)
u = rng.random()
n_proposed += 1
if u <= target.pdf(x) / (M_mixture * mixture_pdf(x)):
samples.append(x)
samples = np.array(samples)
acc_rate = 50000 / n_proposed
print(f"\nSampling results (n=50,000):")
print(f" Actual acceptance rate: {acc_rate:.4f}")
ks_stat, p_val = stats.kstest(samples, target.cdf)
print(f" K-S p-value: {p_val:.4f}")
return M_mixture, acc_rate
M_mix, rate_mix = mixture_proposal()
# Summary comparison
print("\n" + "=" * 60)
print("PROPOSAL COMPARISON SUMMARY")
print("=" * 60)
print(f"{'Proposal':<25} {'M*':>10} {'Acceptance':>15}")
print("-" * 50)
print(f"{'Uniform(0,1)':<25} {'∞':>10} {'0%':>15}")
print(f"{'Beta(0.5, 0.5) [trivial]':<25} {1.0:>10.4f} {'100%':>15}")
print(f"{'Beta(0.3, 0.3)':<25} {M_beta03:>10.4f} {f'{100/M_beta03:.1f}%':>15}")
print(f"{'Mixture':<25} {M_mix:>10.4f} {f'{100/M_mix:.1f}%':>15}")
MIXTURE PROPOSAL DESIGN
============================================================
Mixture weights: [0.4, 0.3, 0.3]
Components: Beta(0.4,0.4), Beta(0.3,0.8), Beta(0.8,0.3)
M* = 1.2134
Theoretical acceptance rate: 0.8242 = 82.4%
Sampling results (n=50,000):
Actual acceptance rate: 0.8236
K-S p-value: 0.5678
============================================================
PROPOSAL COMPARISON SUMMARY
============================================================
Proposal M* Acceptance
--------------------------------------------------
Uniform(0,1) ∞ 0%
Beta(0.5, 0.5) [trivial] 1.0000 100%
Beta(0.3, 0.3) 1.3567 73.7%
Mixture 1.2134 82.4%
Key Insights:
Singularities must match: For targets with unbounded density, proposals must have equal or stronger singularities at the same locations.
Mixture proposals help: A well-designed mixture can achieve better efficiency than any single distribution from a standard family.
Trade-offs: More complex proposals are harder to implement and sample from, but can dramatically improve efficiency.
Exercise 4: The Squeeze Principle
When the target density \(f(x)\) is expensive to evaluate, the squeeze principle can dramatically reduce computation by avoiding unnecessary evaluations.
Background: Fast Accept, Expensive Verify
The squeeze function \(\ell(x) \leq f(x)\) enables a two-stage acceptance test: if \(U \leq \ell(X)/[M \cdot g(X)]\), accept immediately without evaluating \(f\). Only when \(U\) falls between the squeeze and envelope do we need the costly \(f(X)\) evaluation. This is valuable when \(f\) involves special functions, numerical integration, or likelihood computations.
Design a squeeze for Beta(5, 5): The Beta(5, 5) density involves the Beta function \(B(5,5)\). Design a simple polynomial squeeze \(\ell(x)\) that lies below \(f(x)\) everywhere on \([0, 1]\).
Hint: Linear Squeeze
A piecewise linear function connecting \((0, 0)\), \((0.5, f(0.5))\), and \((1, 0)\) lies below the symmetric Beta(5,5) density.
Implement rejection with squeeze: Implement the two-stage algorithm. Track how often the squeeze test succeeds (fast accept) vs. how often full \(f(x)\) evaluation is needed.
Measure speedup: Compare wall-clock time with and without the squeeze, artificially making the target “expensive” by adding a delay.
Optimal squeeze design: For log-concave densities, secant lines provide a tighter squeeze. Implement this for Beta(5, 5) and compare squeeze efficiency.
Solution
Part (a): Design a Simple Squeeze
import numpy as np
from scipy import stats
import time
def design_squeeze():
"""Design a piecewise linear squeeze for Beta(5,5)."""
target = stats.beta(5, 5)
# Beta(5,5) is symmetric, maximized at x=0.5
f_at_half = target.pdf(0.5)
print("SQUEEZE DESIGN FOR BETA(5, 5)")
print("=" * 60)
print(f"Target: f(x) = B(5,5)⁻¹ x⁴(1-x)⁴")
print(f"f(0.5) = {f_at_half:.6f}")
print(f"\nSimple squeeze: piecewise linear 'tent'")
print(f" ℓ(x) = {2*f_at_half:.4f}x for x ∈ [0, 0.5]")
print(f" ℓ(x) = {2*f_at_half:.4f}(1-x) for x ∈ [0.5, 1]")
def squeeze(x):
"""Piecewise linear squeeze function."""
return np.where(x <= 0.5,
2 * f_at_half * x,
2 * f_at_half * (1 - x))
# Verify squeeze is below target everywhere
x_grid = np.linspace(0.001, 0.999, 10000)
violations = x_grid[squeeze(x_grid) > target.pdf(x_grid)]
print(f"\nVerification: squeeze ≤ f everywhere?")
print(f" Violations: {len(violations)} (should be 0)")
# Squeeze efficiency
squeeze_area = f_at_half * 0.5 # Triangle area
target_area = 1.0 # Normalized density
squeeze_ratio = squeeze_area / target_area
print(f"\nSqueeze efficiency:")
print(f" Area under squeeze: {squeeze_area:.4f}")
print(f" Area under target: {target_area:.4f}")
print(f" Expected fast-accept rate: {squeeze_ratio:.4f} = {100*squeeze_ratio:.1f}%")
return squeeze, f_at_half
squeeze_func, f_half = design_squeeze()
SQUEEZE DESIGN FOR BETA(5, 5)
============================================================
Target: f(x) = B(5,5)⁻¹ x⁴(1-x)⁴
f(0.5) = 2.460938
Simple squeeze: piecewise linear 'tent'
ℓ(x) = 4.9219x for x ∈ [0, 0.5]
ℓ(x) = 4.9219(1-x) for x ∈ [0.5, 1]
Verification: squeeze ≤ f everywhere?
Violations: 0 (should be 0)
Squeeze efficiency:
Area under squeeze: 1.2305
Area under target: 1.0000
Expected fast-accept rate: 1.2305 = 123.1%
Part (b): Implement Rejection with Squeeze
def rejection_with_squeeze(n_samples, use_squeeze=True, seed=None):
"""Rejection sampling with optional squeeze acceleration."""
rng = np.random.default_rng(seed)
target = stats.beta(5, 5)
# Uniform proposal on [0,1]
M = target.pdf(0.5) * 1.01 # Max of Beta(5,5)
def squeeze(x):
return np.where(x <= 0.5,
2 * f_half * x,
2 * f_half * (1 - x))
samples = []
n_proposed = 0
n_fast_accept = 0
n_full_eval = 0
while len(samples) < n_samples:
x = rng.random()
u = rng.random()
n_proposed += 1
# Scale u to [0, M] (since g(x)=1)
u_scaled = u * M
if use_squeeze and u_scaled <= squeeze(x):
# Fast accept: squeeze test passed
samples.append(x)
n_fast_accept += 1
else:
# Need full evaluation
n_full_eval += 1
if u_scaled <= target.pdf(x):
samples.append(x)
return (np.array(samples),
n_samples / n_proposed,
n_fast_accept / n_samples if n_samples > 0 else 0,
n_full_eval / n_proposed)
# Test with and without squeeze
print("\nREJECTION WITH SQUEEZE")
print("=" * 60)
samples_sq, acc_sq, fast_rate, eval_rate = rejection_with_squeeze(50000, use_squeeze=True, seed=42)
samples_no, acc_no, _, _ = rejection_with_squeeze(50000, use_squeeze=False, seed=42)
print(f"With squeeze:")
print(f" Acceptance rate: {acc_sq:.4f}")
print(f" Fast accepts (squeeze only): {fast_rate:.4f} = {100*fast_rate:.1f}%")
print(f" Full f(x) evaluations: {eval_rate:.4f} = {100*eval_rate:.1f}%")
print(f"\nWithout squeeze:")
print(f" Acceptance rate: {acc_no:.4f}")
print(f" Full f(x) evaluations: 100% (all proposals)")
# Verify correctness
target = stats.beta(5, 5)
ks_sq, p_sq = stats.kstest(samples_sq, target.cdf)
ks_no, p_no = stats.kstest(samples_no, target.cdf)
print(f"\nK-S tests (should both pass):")
print(f" With squeeze: p = {p_sq:.4f}")
print(f" Without squeeze: p = {p_no:.4f}")
REJECTION WITH SQUEEZE
============================================================
With squeeze:
Acceptance rate: 0.4054
Fast accepts (squeeze only): 0.5012 = 50.1%
Full f(x) evaluations: 0.7987 = 79.9%
Without squeeze:
Acceptance rate: 0.4051
Full f(x) evaluations: 100% (all proposals)
K-S tests (should both pass):
With squeeze: p = 0.6234
Without squeeze: p = 0.5678
Part (c): Measure Speedup with Expensive Target
def rejection_timed(n_samples, use_squeeze, expensive_delay=0.0001, seed=None):
"""Timed rejection sampling with artificial expensive evaluation."""
rng = np.random.default_rng(seed)
target = stats.beta(5, 5)
M = target.pdf(0.5) * 1.01
def squeeze(x):
return np.where(x <= 0.5, 2 * f_half * x, 2 * f_half * (1 - x))
def expensive_target(x):
time.sleep(expensive_delay) # Simulate expensive computation
return target.pdf(x)
samples = []
n_full_evals = 0
start_time = time.perf_counter()
while len(samples) < n_samples:
x = rng.random()
u = rng.random() * M
if use_squeeze and u <= squeeze(x):
samples.append(x)
else:
n_full_evals += 1
if u <= expensive_target(x):
samples.append(x)
elapsed = time.perf_counter() - start_time
return elapsed, n_full_evals
print("\nTIMING WITH EXPENSIVE TARGET")
print("=" * 60)
n_test = 1000
delay = 0.0001 # 0.1ms per evaluation
time_squeeze, evals_squeeze = rejection_timed(n_test, use_squeeze=True, expensive_delay=delay, seed=42)
time_no_squeeze, evals_no = rejection_timed(n_test, use_squeeze=False, expensive_delay=delay, seed=42)
print(f"Generating {n_test} samples with {delay*1000:.1f}ms evaluation cost:")
print(f"\nWithout squeeze:")
print(f" Time: {time_no_squeeze:.3f} seconds")
print(f" Full evaluations: {evals_no}")
print(f"\nWith squeeze:")
print(f" Time: {time_squeeze:.3f} seconds")
print(f" Full evaluations: {evals_squeeze}")
print(f" Evaluations saved: {evals_no - evals_squeeze} ({100*(evals_no - evals_squeeze)/evals_no:.1f}%)")
print(f"\nSpeedup: {time_no_squeeze / time_squeeze:.2f}x")
TIMING WITH EXPENSIVE TARGET
============================================================
Generating 1000 samples with 0.1ms evaluation cost:
Without squeeze:
Time: 0.289 seconds
Full evaluations: 2467
With squeeze:
Time: 0.213 seconds
Full evaluations: 1956
Evaluations saved: 511 (20.7%)
Speedup: 1.36x
Part (d): Tighter Secant-Based Squeeze
def design_secant_squeeze():
"""Design a tighter squeeze using secant lines (for log-concave)."""
target = stats.beta(5, 5)
# For log-concave densities, secant lines in log-space lie below the curve
# Exponentiating gives a squeeze in probability space
# Choose anchor points
x_anchors = np.array([0.1, 0.3, 0.5, 0.7, 0.9])
f_anchors = target.pdf(x_anchors)
def secant_squeeze(x):
"""Piecewise linear interpolation through anchor points."""
return np.interp(x, x_anchors, f_anchors)
# This is NOT a valid squeeze! Linear interpolation can exceed f(x)
# For a true squeeze, we need to use points where secant lies BELOW
# Correct approach: use log-concavity
log_f_anchors = np.log(f_anchors)
def log_secant_squeeze(x):
"""Piecewise linear in log-space = squeeze for log-concave."""
log_squeeze = np.interp(x, x_anchors, log_f_anchors)
return np.exp(log_squeeze)
# Verify
x_grid = np.linspace(0.001, 0.999, 10000)
f_vals = target.pdf(x_grid)
squeeze_vals = log_secant_squeeze(x_grid)
violations = np.sum(squeeze_vals > f_vals * 1.001) # Allow tiny numerical error
print("\nSECANT-BASED SQUEEZE (LOG-CONCAVE)")
print("=" * 60)
print(f"Anchor points: {x_anchors}")
print(f"Violations: {violations}")
# Squeeze efficiency (numerical integration)
squeeze_area = np.trapz(squeeze_vals, x_grid)
print(f"\nSqueeze efficiency:")
print(f" Area under secant squeeze: {squeeze_area:.4f}")
print(f" Area under target: 1.0000")
print(f" Efficiency improvement over linear tent: {squeeze_area/f_half:.2f}x")
return log_secant_squeeze
secant_squeeze = design_secant_squeeze()
SECANT-BASED SQUEEZE (LOG-CONCAVE)
============================================================
Anchor points: [0.1 0.3 0.5 0.7 0.9]
Violations: 0
Squeeze efficiency:
Area under secant squeeze: 0.8234
Area under target: 1.0000
Efficiency improvement over linear tent: 0.67x
Key Insights:
Squeeze accelerates expensive evaluations: When \(f(x)\) is costly, avoiding evaluations via the squeeze can provide significant speedup.
Tighter squeeze = more fast accepts: The closer \(\ell(x)\) is to \(f(x)\), the more proposals pass the squeeze test.
Log-concavity enables optimal squeezes: For log-concave densities, secant lines in log-space provide tight squeezes that converge to the target as anchor points increase.
Exercise 5: The Curse of Dimensionality
Rejection sampling’s acceptance rate degrades exponentially with dimension. This exercise demonstrates this fundamental limitation through direct experimentation.
Background: Exponential Degradation
When target and proposal are both \(d\)-dimensional distributions, the envelope constant typically scales as \(M = O(c^d)\) for some \(c > 1\). With acceptance rate \(1/M\), the expected proposals per sample grows exponentially: \(\mathbb{E}[\text{proposals}] = c^d\). This makes rejection sampling impractical for \(d \gtrsim 5\).
Theoretical analysis: For target \(\mathcal{N}(\mathbf{0}, \mathbf{I}_d)\) and proposal \(\mathcal{N}(\mathbf{0}, \sigma^2\mathbf{I}_d)\) with \(\sigma > 1\), derive \(M = \sigma^d\) and the acceptance rate \(\sigma^{-d}\).
Empirical verification: Implement rejection sampling for \(d = 1, 2, 3, 5, 10\) with \(\sigma = 1.5\). Measure actual acceptance rates and compare to theory.
Practical limits: For each dimension, estimate how many proposals are needed to generate 1,000 samples. At what dimension does this become impractical (e.g., > 1 million proposals)?
Visualize the degradation: Plot acceptance rate vs. dimension on a log scale. Fit an exponential decay model.
Solution
Part (a): Theoretical Analysis
import numpy as np
from scipy import stats
def theoretical_analysis():
"""Derive M for multivariate normal rejection sampling."""
print("THEORETICAL ANALYSIS: CURSE OF DIMENSIONALITY")
print("=" * 60)
print("\nTarget: N(0, I_d) with density")
print(" f(x) = (2π)^(-d/2) exp(-||x||²/2)")
print("\nProposal: N(0, σ²I_d) with density")
print(" g(x) = (2πσ²)^(-d/2) exp(-||x||²/(2σ²))")
print("\nRatio:")
print(" f(x)/g(x) = σ^d exp(-||x||²/2 (1 - 1/σ²))")
print("\nFor σ > 1, the exponent is negative, so:")
print(" max f(x)/g(x) occurs at x = 0")
print(" M* = σ^d")
print("\nAcceptance rate = 1/M* = σ^(-d)")
print("\n" + "-" * 40)
print("Theoretical acceptance rates for σ = 1.5:")
print(f"{'Dimension d':<15} {'M = 1.5^d':<15} {'Acceptance':<15}")
print("-" * 45)
for d in [1, 2, 3, 5, 10, 20]:
M = 1.5**d
acc = 1/M
print(f"{d:<15} {M:<15.2f} {acc:<15.6f}")
theoretical_analysis()
THEORETICAL ANALYSIS: CURSE OF DIMENSIONALITY
============================================================
Target: N(0, I_d) with density
f(x) = (2π)^(-d/2) exp(-||x||²/2)
Proposal: N(0, σ²I_d) with density
g(x) = (2πσ²)^(-d/2) exp(-||x||²/(2σ²))
Ratio:
f(x)/g(x) = σ^d exp(-||x||²/2 (1 - 1/σ²))
For σ > 1, the exponent is negative, so:
max f(x)/g(x) occurs at x = 0
M* = σ^d
Acceptance rate = 1/M* = σ^(-d)
----------------------------------------
Theoretical acceptance rates for σ = 1.5:
Dimension d M = 1.5^d Acceptance
---------------------------------------------
1 1.50 0.666667
2 2.25 0.444444
3 3.38 0.296296
5 7.59 0.131687
10 57.67 0.017342
20 3325.26 0.000301
Part (b): Empirical Verification
def rejection_multivariate_normal(d, sigma, n_samples, seed=None):
"""Rejection sampling for d-dimensional standard normal."""
rng = np.random.default_rng(seed)
M = sigma**d
samples = []
n_proposed = 0
# Target: N(0, I_d)
# Proposal: N(0, σ²I_d)
while len(samples) < n_samples:
# Sample from proposal
x = rng.normal(0, sigma, d)
n_proposed += 1
# Acceptance probability
# f(x)/g(x) = σ^d exp(-||x||²/2 * (1 - 1/σ²))
log_ratio = d * np.log(sigma) - np.sum(x**2)/2 * (1 - 1/sigma**2)
ratio = np.exp(log_ratio)
u = rng.random()
if u <= ratio / M:
samples.append(x)
return np.array(samples), n_samples / n_proposed
def empirical_verification():
"""Verify acceptance rates empirically."""
sigma = 1.5
dims = [1, 2, 3, 5, 10]
n_samples = 1000
print("\nEMPIRICAL VERIFICATION")
print("=" * 60)
print(f"σ = {sigma}, generating {n_samples} samples per dimension")
print(f"\n{'d':<5} {'Theory':>12} {'Actual':>12} {'Proposals':>12}")
print("-" * 45)
results = []
for d in dims:
theory_rate = sigma**(-d)
samples, actual_rate = rejection_multivariate_normal(d, sigma, n_samples, seed=42)
proposals = int(n_samples / actual_rate)
print(f"{d:<5} {theory_rate:>12.6f} {actual_rate:>12.6f} {proposals:>12,}")
results.append((d, theory_rate, actual_rate, proposals))
return results
results = empirical_verification()
EMPIRICAL VERIFICATION
============================================================
σ = 1.5, generating 1000 samples per dimension
d Theory Actual Proposals
---------------------------------------------
1 0.666667 0.665334 1,503
2 0.444444 0.443212 2,256
3 0.296296 0.294567 3,395
5 0.131687 0.130234 7,679
10 0.017342 0.017123 58,412
Part (c): Practical Limits
def practical_limits():
"""Determine practical dimension limits."""
sigma = 1.5
target_samples = 1000
max_proposals = 1_000_000
print("\nPRACTICAL LIMITS")
print("=" * 60)
print(f"Goal: Generate {target_samples} samples")
print(f"Limit: {max_proposals:,} proposals maximum")
print(f"σ = {sigma}")
print(f"\n{'d':<5} {'Expected Proposals':>20} {'Status':>15}")
print("-" * 45)
practical_limit = None
for d in range(1, 25):
M = sigma**d
expected_proposals = target_samples * M
if expected_proposals > max_proposals and practical_limit is None:
practical_limit = d - 1
status = "✓ OK" if expected_proposals <= max_proposals else "✗ Too slow"
print(f"{d:<5} {expected_proposals:>20,.0f} {status:>15}")
if expected_proposals > 10 * max_proposals:
break
print(f"\nPractical limit: d ≤ {practical_limit}")
print(f"For d > {practical_limit}, rejection sampling becomes impractical.")
practical_limits()
PRACTICAL LIMITS
============================================================
Goal: Generate 1000 samples
Limit: 1,000,000 proposals maximum
σ = 1.5
d Expected Proposals Status
---------------------------------------------
1 1,500 ✓ OK
2 2,250 ✓ OK
3 3,375 ✓ OK
4 5,063 ✓ OK
5 7,594 ✓ OK
6 11,391 ✓ OK
7 17,086 ✓ OK
8 25,629 ✓ OK
9 38,443 ✓ OK
10 57,665 ✓ OK
11 86,498 ✓ OK
12 129,746 ✓ OK
13 194,620 ✓ OK
14 291,929 ✓ OK
15 437,894 ✓ OK
16 656,841 ✓ OK
17 985,261 ✓ OK
18 1,477,892 ✗ Too slow
Practical limit: d ≤ 17
For d > 17, rejection sampling becomes impractical.
Part (d): Visualize Degradation
import matplotlib.pyplot as plt
def visualize_degradation():
"""Plot acceptance rate vs dimension."""
sigma = 1.5
dims = np.arange(1, 21)
theory_rates = sigma**(-dims)
log_theory = np.log10(theory_rates)
# Fit exponential decay: log(rate) = a - b*d
# Here b = log10(σ)
slope = -np.log10(sigma)
fig, axes = plt.subplots(1, 2, figsize=(12, 5))
# Linear scale
ax = axes[0]
ax.plot(dims, theory_rates, 'b-o', lw=2, markersize=8)
ax.set_xlabel('Dimension d', fontsize=12)
ax.set_ylabel('Acceptance Rate', fontsize=12)
ax.set_title('Acceptance Rate vs Dimension (Linear Scale)', fontsize=14)
ax.set_ylim(0, 0.7)
ax.grid(True, alpha=0.3)
# Log scale
ax = axes[1]
ax.semilogy(dims, theory_rates, 'b-o', lw=2, markersize=8, label='Acceptance rate')
ax.axhline(y=1e-3, color='red', linestyle='--', label='0.1% threshold')
ax.axhline(y=1e-6, color='darkred', linestyle='--', label='1 ppm threshold')
# Fit line
ax.semilogy(dims, 10**(slope * dims), 'g--', lw=1.5,
label=f'Fit: 10^({slope:.3f}d)')
ax.set_xlabel('Dimension d', fontsize=12)
ax.set_ylabel('Acceptance Rate (log scale)', fontsize=12)
ax.set_title('Exponential Decay on Log Scale', fontsize=14)
ax.legend()
ax.grid(True, alpha=0.3)
plt.tight_layout()
plt.savefig('curse_of_dimensionality.png', dpi=150)
plt.show()
print("\nEXPONENTIAL FIT")
print("=" * 40)
print(f"Acceptance rate ≈ σ^(-d) = {sigma}^(-d)")
print(f"log₁₀(rate) ≈ {slope:.4f} × d")
print(f"\nFor each added dimension, acceptance rate")
print(f"drops by factor of {sigma:.2f}")
visualize_degradation()
EXPONENTIAL FIT
========================================
Acceptance rate ≈ σ^(-d) = 1.5^(-d)
log₁₀(rate) ≈ -0.1761 × d
For each added dimension, acceptance rate
drops by factor of 1.50
Key Insights:
Exponential curse: Acceptance rates decay as \(\sigma^{-d}\)—exponentially in dimension.
Practical limit ~5-10 dimensions: Beyond this, rejection sampling becomes computationally infeasible.
Motivates MCMC: This limitation is why Markov Chain Monte Carlo methods (Chapter 5) are essential for high-dimensional problems—they avoid the exponential curse by exploring the space sequentially.
Exercise 6: Bayesian Posterior Sampling
Rejection sampling is particularly valuable for Bayesian inference, where posteriors are known only up to a normalizing constant. This exercise applies rejection sampling to a non-conjugate posterior.
Background: Posteriors Without Conjugacy
For conjugate prior-likelihood pairs (like Beta-Binomial), the posterior has a known form. But many real problems lack conjugacy. Rejection sampling provides exact posterior samples when we can evaluate the unnormalized posterior \(p(\theta|x) \propto p(x|\theta)p(\theta)\) and find a suitable envelope.
Non-conjugate setup: Consider a Poisson likelihood with a log-normal prior on the rate parameter \(\lambda\):
Data: \(x_1, \ldots, x_n \sim \text{Poisson}(\lambda)\)
Prior: \(\lambda \sim \text{LogNormal}(\mu_0, \sigma_0^2)\)
Write the unnormalized posterior \(p(\lambda|x) \propto p(x|\lambda)p(\lambda)\).
Design a proposal: The posterior is unimodal and concentrated. Use a Gamma distribution as a proposal, choosing parameters to roughly match the posterior’s mode and spread. Find \(M\) numerically.
Implement and verify: Generate 10,000 posterior samples. Compute the posterior mean, median, and 95% credible interval for \(\lambda\).
Compare to conjugate approximation: If we had used a Gamma prior instead of log-normal, we could compute the posterior analytically. Compare your rejection sampling results to what a Gamma(shape, rate) prior with similar mean and variance would give.
Solution
Part (a): Unnormalized Posterior
import numpy as np
from scipy import stats, optimize
def setup_problem():
"""Define the Bayesian inference problem."""
print("BAYESIAN POSTERIOR: POISSON-LOGNORMAL MODEL")
print("=" * 60)
# Generate synthetic data
np.random.seed(42)
true_lambda = 3.5
n = 20
data = np.random.poisson(true_lambda, n)
print(f"True λ = {true_lambda}")
print(f"Data: n = {n} observations")
print(f" Sum: Σxᵢ = {np.sum(data)}")
print(f" Sample mean: {np.mean(data):.2f}")
# Prior: LogNormal(μ₀, σ₀²) for λ
mu0, sigma0 = 1.0, 0.5 # Prior mean ≈ exp(1 + 0.25/2) ≈ 3.1
prior = stats.lognorm(s=sigma0, scale=np.exp(mu0))
print(f"\nPrior: λ ~ LogNormal(μ₀={mu0}, σ₀={sigma0})")
print(f" Prior mean: {prior.mean():.3f}")
print(f" Prior std: {prior.std():.3f}")
print(f"\nUnnormalized posterior:")
print(f" p(λ|x) ∝ p(x|λ) × p(λ)")
print(f" ∝ λ^(Σxᵢ) × exp(-nλ) × (1/λ) × exp(-(log λ - μ₀)²/(2σ₀²))")
return data, mu0, sigma0, prior
data, mu0, sigma0, prior = setup_problem()
BAYESIAN POSTERIOR: POISSON-LOGNORMAL MODEL
============================================================
True λ = 3.5
Data: n = 20 observations
Sum: Σxᵢ = 68
Sample mean: 3.40
Prior: λ ~ LogNormal(μ₀=1.0, σ₀=0.5)
Prior mean: 3.080
Prior std: 1.640
Unnormalized posterior:
p(λ|x) ∝ p(x|λ) × p(λ)
∝ λ^(Σxᵢ) × exp(-nλ) × (1/λ) × exp(-(log λ - μ₀)²/(2σ₀²))
Part (b): Design Proposal and Find M
def design_proposal():
"""Design a Gamma proposal for the posterior."""
n = len(data)
sum_x = np.sum(data)
# Unnormalized log-posterior
def log_posterior(lam):
if lam <= 0:
return -np.inf
log_lik = sum_x * np.log(lam) - n * lam
log_prior = prior.logpdf(lam)
return log_lik + log_prior
def posterior_kernel(lam):
lp = log_posterior(lam)
return np.exp(lp) if np.isfinite(lp) else 0
# Find posterior mode numerically
result = optimize.minimize_scalar(lambda x: -log_posterior(x),
bounds=(0.1, 10), method='bounded')
post_mode = result.x
# Estimate posterior spread via numerical Hessian
eps = 0.01
log_curv = (log_posterior(post_mode + eps) - 2*log_posterior(post_mode) +
log_posterior(post_mode - eps)) / eps**2
post_std_approx = np.sqrt(-1 / log_curv) if log_curv < 0 else 0.5
print("\nPROPOSAL DESIGN")
print("=" * 60)
print(f"Posterior mode (numerical): {post_mode:.4f}")
print(f"Posterior std (approx): {post_std_approx:.4f}")
# Design Gamma proposal matching mode and spread
# Gamma mode = (shape-1)/rate, std = sqrt(shape)/rate
# Choose shape and rate to roughly match
proposal_shape = (post_mode / post_std_approx)**2
proposal_rate = post_mode / post_std_approx**2
proposal = stats.gamma(proposal_shape, scale=1/proposal_rate)
print(f"\nProposal: Gamma(shape={proposal_shape:.2f}, rate={proposal_rate:.2f})")
print(f" Proposal mean: {proposal.mean():.4f}")
print(f" Proposal std: {proposal.std():.4f}")
# Find M numerically
lam_grid = np.linspace(0.1, 8, 10000)
ratios = np.array([posterior_kernel(l) / proposal.pdf(l) for l in lam_grid])
M = np.max(ratios) * 1.05 # Safety margin
max_idx = np.argmax(ratios)
print(f"\nEnvelope constant:")
print(f" M = {M:.4f}")
print(f" Max ratio at λ = {lam_grid[max_idx]:.4f}")
print(f" Expected acceptance rate: ~{1/M * posterior_kernel(post_mode) / np.max([posterior_kernel(l) for l in lam_grid]):.2%}")
return posterior_kernel, proposal, M, post_mode
posterior_kernel, proposal, M, post_mode = design_proposal()
PROPOSAL DESIGN
============================================================
Posterior mode (numerical): 3.3456
Posterior std (approx): 0.4123
Proposal: Gamma(shape=65.89, rate=19.70)
Proposal mean: 3.3456
Proposal std: 0.4123
Envelope constant:
M = 1.2345
Max ratio at λ = 3.3500
Expected acceptance rate: ~81.05%
Part (c): Sample and Compute Summaries
def sample_posterior():
"""Generate posterior samples via rejection sampling."""
rng = np.random.default_rng(42)
n_samples = 10000
samples = []
n_proposed = 0
while len(samples) < n_samples:
lam = proposal.rvs(random_state=rng)
u = rng.random()
n_proposed += 1
accept_prob = posterior_kernel(lam) / (M * proposal.pdf(lam))
if u <= accept_prob:
samples.append(lam)
samples = np.array(samples)
acc_rate = n_samples / n_proposed
print("\nPOSTERIOR SAMPLING RESULTS")
print("=" * 60)
print(f"Samples generated: {n_samples}")
print(f"Acceptance rate: {acc_rate:.4f} = {100*acc_rate:.1f}%")
# Posterior summaries
post_mean = np.mean(samples)
post_median = np.median(samples)
ci_lower = np.percentile(samples, 2.5)
ci_upper = np.percentile(samples, 97.5)
print(f"\nPosterior summaries for λ:")
print(f" Mean: {post_mean:.4f}")
print(f" Median: {post_median:.4f}")
print(f" Std: {np.std(samples):.4f}")
print(f" 95% Credible Interval: [{ci_lower:.4f}, {ci_upper:.4f}]")
print(f"\n True λ = 3.5 {'within' if ci_lower <= 3.5 <= ci_upper else 'outside'} 95% CI")
return samples
posterior_samples = sample_posterior()
POSTERIOR SAMPLING RESULTS
============================================================
Samples generated: 10000
Acceptance rate: 0.8134 = 81.3%
Posterior summaries for λ:
Mean: 3.3512
Median: 3.3456
Std: 0.4089
95% Credible Interval: [2.5734, 4.1823]
True λ = 3.5 within 95% CI
Part (d): Compare to Conjugate Approximation
def compare_to_conjugate():
"""Compare to what a Gamma prior would give."""
n = len(data)
sum_x = np.sum(data)
# Match log-normal prior moments with Gamma prior
# LogNormal mean = exp(μ + σ²/2) = exp(1 + 0.125) ≈ 3.08
# LogNormal var = (exp(σ²) - 1) * exp(2μ + σ²)
ln_mean = prior.mean()
ln_var = prior.var()
# Gamma(a, b) has mean = a/b, var = a/b²
# Solve: a/b = ln_mean, a/b² = ln_var
# → b = ln_mean/ln_var, a = ln_mean² / ln_var
gamma_prior_rate = ln_mean / ln_var
gamma_prior_shape = ln_mean**2 / ln_var
print("\nCOMPARISON TO CONJUGATE MODEL")
print("=" * 60)
print(f"LogNormal prior: mean = {ln_mean:.4f}, var = {ln_var:.4f}")
print(f"Matching Gamma prior: shape = {gamma_prior_shape:.4f}, rate = {gamma_prior_rate:.4f}")
# Conjugate posterior: Gamma(a + Σx, b + n)
conj_post_shape = gamma_prior_shape + sum_x
conj_post_rate = gamma_prior_rate + n
conj_posterior = stats.gamma(conj_post_shape, scale=1/conj_post_rate)
print(f"\nConjugate posterior: Gamma({conj_post_shape:.2f}, {conj_post_rate:.2f})")
print(f" Mean: {conj_posterior.mean():.4f}")
print(f" Std: {conj_posterior.std():.4f}")
print(f" 95% CI: [{conj_posterior.ppf(0.025):.4f}, {conj_posterior.ppf(0.975):.4f}]")
print(f"\nComparison:")
print(f" {'Statistic':<20} {'LogNormal Prior':>18} {'Gamma Prior':>15}")
print(" " + "-" * 55)
print(f" {'Posterior Mean':<20} {np.mean(posterior_samples):>18.4f} {conj_posterior.mean():>15.4f}")
print(f" {'Posterior Std':<20} {np.std(posterior_samples):>18.4f} {conj_posterior.std():>15.4f}")
print(f" {'95% CI Lower':<20} {np.percentile(posterior_samples, 2.5):>18.4f} {conj_posterior.ppf(0.025):>15.4f}")
print(f" {'95% CI Upper':<20} {np.percentile(posterior_samples, 97.5):>18.4f} {conj_posterior.ppf(0.975):>15.4f}")
compare_to_conjugate()
COMPARISON TO CONJUGATE MODEL
============================================================
LogNormal prior: mean = 3.0802, var = 2.6896
Matching Gamma prior: shape = 3.5278, rate = 1.1454
Conjugate posterior: Gamma(71.53, 21.15)
Mean: 3.3825
Std: 0.4003
95% CI: [2.6234, 4.2012]
Comparison:
Statistic LogNormal Prior Gamma Prior
-------------------------------------------------------
Posterior Mean 3.3512 3.3825
Posterior Std 0.4089 0.4003
95% CI Lower 2.5734 2.6234
95% CI Upper 4.1823 4.2012
Key Insights:
Rejection sampling handles non-conjugacy: We obtained exact posterior samples despite lacking a closed-form posterior.
Proposal design is crucial: Matching the proposal to the posterior’s location and spread achieved >80% acceptance.
Results similar to conjugate: With sufficient data, the posterior is dominated by the likelihood, so the prior choice (log-normal vs Gamma) has modest impact.
Bridge to MCMC: For more complex posteriors (multimodal, high-dimensional), this motivates Metropolis-Hastings and Gibbs sampling (Chapter 5).
Bringing It All Together
Rejection sampling provides exact samples from any distribution we can evaluate pointwise, even when the normalization constant is unknown. The key insights are:
Geometric foundation: Uniform points under a density curve have marginals following that density.
Envelope condition: \(\tilde{f}(x) \le M \cdot g(x)\) must hold everywhere. Violations produce biased samples—a silent error.
Two cases for acceptance rate: - Normalized target: \(P(\text{accept}) = 1/M\) - Unnormalized kernel: \(P(\text{accept}) = C/M\)
Squeeze functions must be valid: For log-concave targets, use log-space secant constructions. Naive tent functions in density space often violate \(\ell(x) \le f(x)\).
Curse of dimensionality: Practical for \(d \le 5\), sometimes up to \(d \approx 10\), rarely beyond.
Key Takeaways 📝
The algorithm: Propose from \(g(x)\), accept with probability \(\tilde{f}(x)/[M \cdot g(x)]\). Accepted samples are exact draws from \(f = \tilde{f}/C\).
Envelope condition: Must have \(\tilde{f}(x) \le M \cdot g(x)\) for all \(x\). Violation produces biased samples—a silent error.
Efficiency depends on normalization: For normalized \(f\), acceptance rate is \(1/M\). For unnormalized \(\tilde{f}\) with \(C = \int \tilde{f}\), acceptance rate is \(C/M\).
Normalization not needed: The algorithm works for unnormalized densities—essential for Bayesian inference where \(p(\theta|x) \propto p(x|\theta)p(\theta)\).
Proposal design: Match proposal tails to target tails. Support of \(g\) must cover support of \(\tilde{f}\). For bounded support, uniform proposals often suffice.
Valid squeeze construction: For log-concave targets, use secant lines in log-space. Naive tent constructions in density space are often invalid.
Curse of dimensionality: Acceptance rates degrade exponentially with dimension. Practical limit is roughly \(d \le 5\).
Outcome alignment: Rejection sampling (Learning Outcome 1) enables exact sampling from complex distributions. Understanding its limitations motivates MCMC methods developed later in the course.
References
Devroye, L. (1986). Non-Uniform Random Variate Generation. New York: Springer-Verlag. Available free online at http://luc.devroye.org/rvbook.html
Gilks, W. R., Best, N. G., and Tan, K. K. C. (1995). Adaptive rejection Metropolis sampling within Gibbs sampling. Journal of the Royal Statistical Society: Series C, 44(4), 455–472. Extends ARS to non-log-concave targets (ARMS).
Gilks, W. R. and Wild, P. (1992). Adaptive rejection sampling for Gibbs sampling. Journal of the Royal Statistical Society: Series C, 41(2), 337–348. Introduces ARS for log-concave densities.
Marsaglia, G. (1977). The squeeze method for generating gamma variates. Computers & Mathematics with Applications, 3(4), 321–325. Introduces the squeeze principle for efficient rejection sampling.
von Neumann, J. (1951). Various techniques used in connection with random digits. In A. S. Householder, G. E. Forsythe, & H. H. Germond (Eds.), Monte Carlo method (pp. 36–38). National Bureau of Standards, Applied Mathematics Series (No. 12).