Section 6.4 LLM-Assisted Data Annotation
Supervised learning requires labeled data. This truism hides an enormous practical cost: producing high-quality labels for thousands or tens of thousands of data points is expensive, time-consuming, and often the bottleneck that determines whether a project is feasible. Hiring human annotators to label 10,000 customer reviews for sentiment, or 50,000 medical records for diagnostic codes, can cost thousands of dollars and take weeks.
Large language models offer a compelling alternative. An LLM can annotate text at a fraction of the cost and orders of magnitude faster than human annotators. For many tasks—sentiment classification, topic categorization, named entity recognition—LLM annotations approach or match human-level quality. For other tasks—those requiring deep domain expertise, nuanced judgment, or cultural context—LLM performance degrades and human annotation remains essential.
The critical question is not whether LLMs can annotate but when their annotations are reliable enough for your analytical purposes. This section develops the tools and statistical methods to answer that question rigorously.
Road Map 🧭
Understand the annotation bottleneck and how LLMs address it
Design annotation prompts that produce consistent, parseable labels
Implement batch annotation pipelines with structured output parsing
Evaluate annotation quality using Cohen’s kappa, inter-annotator agreement, and bootstrap CIs
Determine when LLM annotation is appropriate and when human labels are essential
The Annotation Bottleneck
Why Labeled Data Matters
Throughout this course, we have assumed the existence of labeled datasets: classifications for logistic regression, outcomes for survival analysis, categories for cross-validation experiments. But where do these labels come from? In practice, someone—a domain expert, a crowd worker, a research assistant—reads each data point and assigns a label. This is data annotation, and it is the unglamorous foundation of supervised learning.
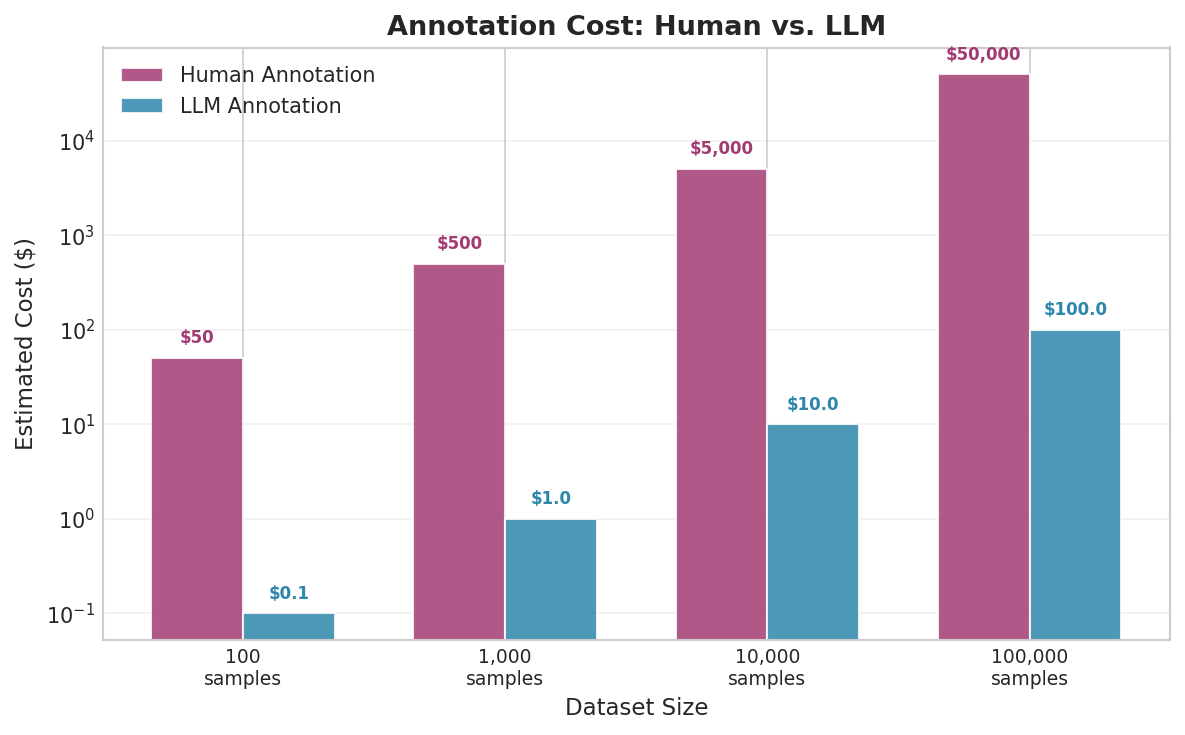
Fig. 226 Figure 6.4.1: The cost gap between human and LLM annotation grows dramatically with dataset size. At 10,000 samples, human annotation may cost thousands of dollars and weeks of time; LLM annotation costs pennies and completes in minutes.
Traditional annotation has well-known challenges:
Cost: Professional annotators charge $15–50/hour. Labeling 10,000 items at 30 seconds each requires ~80 hours ($1,200–$4,000).
Time: Even with multiple annotators, large datasets take days or weeks.
Consistency: Human annotators disagree with each other (and with themselves over time). Typical inter-annotator agreement for subjective tasks is 70–85%.
Scale: Some analyses require more data than any annotation budget can support.
An LLM annotator changes this calculus on every axis: it costs pennies, runs in minutes, and applies its (imperfect) judgment identically to the first item and the ten-thousandth. What it does not guarantee is correctness—which is why the rest of this section pairs the annotation pipeline with the statistical machinery to audit it.
LLM as Annotator
Designing Annotation Prompts
The prompt is the annotation guideline. In traditional annotation, you write detailed instructions for human annotators—what each label means, how to handle edge cases, what to do when uncertain. For LLM annotation, the prompt serves the same purpose:
from genai_studio import GenAIStudio
ai = GenAIStudio()
ai.select_model("gemma3:12b")
ANNOTATION_PROMPT = """Classify the sentiment of the following customer review.
Categories:
- positive: The reviewer expresses satisfaction, approval, or recommendation
- negative: The reviewer expresses dissatisfaction, complaint, or warning
- neutral: The reviewer is factual or balanced without strong sentiment
Respond with ONLY the category label (positive, negative, or neutral).
Do not include any explanation.
Review: {text}
Label:"""
def annotate_sentiment(text):
prompt = ANNOTATION_PROMPT.format(text=text)
response = ai.chat(prompt).strip().lower()
if response in ["positive", "negative", "neutral"]:
return response
return "unparseable"
# Test
samples = [
"Absolutely love this product, best purchase ever!",
"Broke after two days, complete waste of money.",
"The package arrived on Tuesday as expected.",
]
for text in samples:
label = annotate_sentiment(text)
print(f" [{label:>8}] {text}")
[positive] Absolutely love this product, best purchase ever!
[negative] Broke after two days, complete waste of money.
[ neutral] The package arrived on Tuesday as expected.
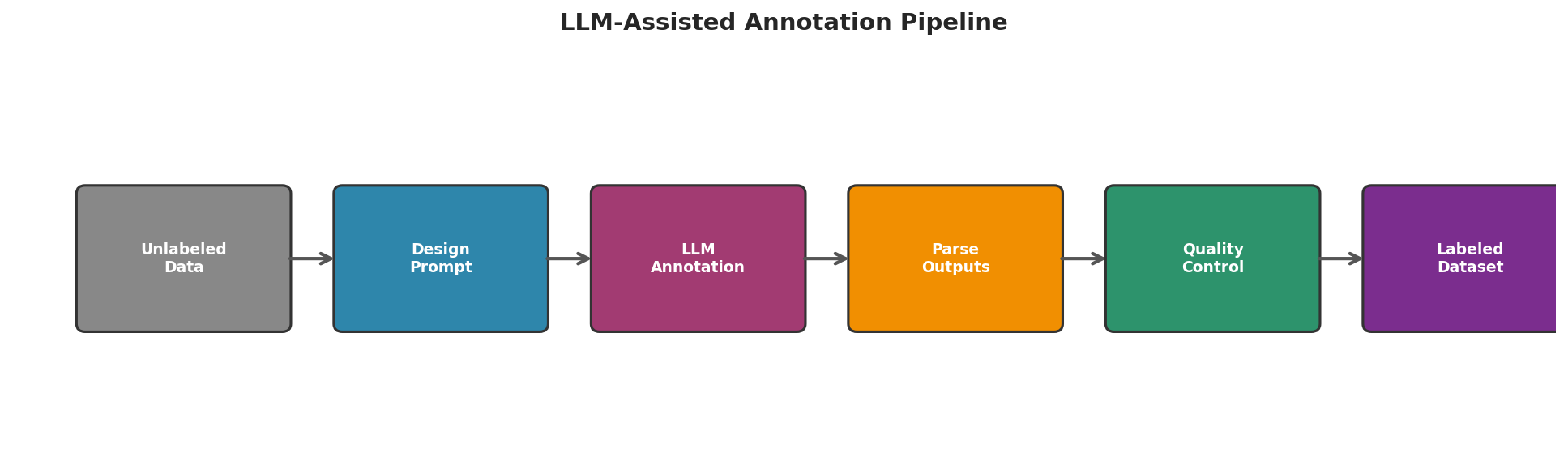
Fig. 227 Figure 6.4.2: The LLM annotation pipeline: unlabeled data is processed through a carefully designed prompt, parsed into structured labels, subjected to quality control, and output as a labeled dataset ready for analysis.
Structured Output Parsing
For more complex annotations, request JSON output so labels are machine-parseable:
import json
STRUCTURED_PROMPT = """Analyze the following customer review.
Return your response as a JSON object with these fields:
- "sentiment": one of "positive", "negative", "neutral"
- "confidence": a number from 0 to 1 indicating your confidence
- "topics": a list of topics mentioned (e.g., "quality", "shipping", "price")
Return ONLY the JSON object, no other text.
Review: {text}"""
def annotate_structured(text):
prompt = STRUCTURED_PROMPT.format(text=text)
response = ai.chat(prompt).strip()
# Strip markdown code fences if present
if response.startswith("```"):
response = response.split("\n", 1)[1].rsplit("```", 1)[0]
try:
return json.loads(response)
except json.JSONDecodeError:
return {"sentiment": "unparseable", "confidence": 0, "topics": []}
result = annotate_structured(
"Great quality but shipping took forever. Price was reasonable."
)
print(json.dumps(result, indent=2))
{
"sentiment": "positive",
"confidence": 0.7,
"topics": ["quality", "shipping", "price"]
}
A caution before you use that confidence field: it is generated text, not a measured probability. A model can report 0.9 on a label it gets wrong, so treat a self-reported confidence as a rough triage flag—never as an error rate. Section 6.8 examines this failure mode (overconfidence) and builds a better-behaved uncertainty signal from agreement across repeated runs, which we preview below.
Batch Annotation Pipeline
For annotating datasets at scale, wrap the annotation function in a batch pipeline with progress tracking, error handling, and rate-limit spacing. GenAI Studio caps out near 20 requests per minute and silently drops bursts rather than returning errors, so an unpaced loop quietly loses responses:
import time
def annotate_batch(texts, annotate_fn, batch_name="batch", delay=3.5):
"""Annotate a batch of texts, tracking progress and errors.
delay=3.5 paces calls to ~17/min, safely under the gateway's ~20/min cap.
"""
results = []
errors = 0
for i, text in enumerate(texts):
time.sleep(delay)
label = annotate_fn(text)
if label == "unparseable":
errors += 1
results.append({"text": text, "label": label, "index": i})
if (i + 1) % 10 == 0:
print(f" {batch_name}: {i+1}/{len(texts)} "
f"({errors} errors)")
print(f" {batch_name}: Complete. {len(texts)} items, "
f"{errors} unparseable ({errors/len(texts):.1%})")
return results
# Annotate 20 reviews
reviews = [
"Excellent build quality!", "Terrible customer service.",
"Works as described.", "Not worth the price.",
"My kids love it!", "Arrived damaged.",
"Perfect fit for my needs.", "Cheaply made.",
"Fast shipping, great seller.", "Returning this immediately.",
"Solid product overall.", "Disappointing quality.",
"Highly recommend!", "Don't waste your money.",
"Good value.", "Falls apart easily.",
"Beautiful design.", "Nothing special.",
"Exceeded expectations.", "Regret buying this.",
]
results = annotate_batch(reviews, annotate_sentiment, "Sentiment")
Sentiment: 10/20 (0 errors)
Sentiment: 20/20 (0 errors)
Sentiment: Complete. 20 items, 0 unparseable (0.0%)
Annotation Tasks for Data Science
Sentiment Analysis
The example above covers basic sentiment. For fine-grained sentiment (1–5 scale), adjust the prompt:
FINE_SENTIMENT_PROMPT = """Rate the sentiment of this review on a 1-5 scale:
1 = Very negative, 2 = Negative, 3 = Neutral, 4 = Positive, 5 = Very positive
Respond with ONLY the number (1, 2, 3, 4, or 5).
Review: {text}
Rating:"""
Named Entity Recognition
Entity extraction produces structured output—each entity has a text span and a type—so the JSON pattern from earlier in this section carries over directly:
NER_PROMPT = """Extract all named entities from the following text.
Return a JSON list where each item has:
- "entity": the text of the entity
- "type": one of "PERSON", "ORGANIZATION", "LOCATION", "DATE"
Return ONLY the JSON list.
Text: {text}"""
def annotate_ner(text):
prompt = NER_PROMPT.format(text=text)
response = ai.chat(prompt).strip()
if response.startswith("```"):
response = response.split("\n", 1)[1].rsplit("```", 1)[0]
try:
return json.loads(response)
except json.JSONDecodeError:
return []
entities = annotate_ner(
"Dr. Smith from Purdue University visited Tokyo on March 15, 2024."
)
for e in entities:
print(f" [{e['type']:>12}] {e['entity']}")
[ PERSON] Dr. Smith
[ORGANIZATION] Purdue University
[ LOCATION] Tokyo
[ DATE] March 15, 2024
Topic Classification
Topic classification follows the same recipe as sentiment—the only real design decision is the category inventory, which should be exhaustive and mutually exclusive:
TOPIC_PROMPT = """Classify this news headline into one of these categories:
sports, technology, politics, business, science, entertainment
Respond with ONLY the category name.
Headline: {text}
Category:"""
headlines = [
"New AI chip doubles processing speed",
"Team wins championship in overtime",
"Senate passes infrastructure bill",
"Startup raises $50M in Series B",
"Researchers discover high-temperature superconductor",
]
for h in headlines:
label = ai.chat(TOPIC_PROMPT.format(text=h)).strip().lower()
print(f" [{label:>13}] {h}")
[ technology] New AI chip doubles processing speed
[ sports] Team wins championship in overtime
[ politics] Senate passes infrastructure bill
[ business] Startup raises $50M in Series B
[ science] Researchers discover high-temperature superconductor
Quality Control and Validation
LLM annotations are not ground truth; they are the output of a fallible model and deserve the same scrutiny we would give any measurement instrument. Fortunately, we already own the machinery for that scrutiny—the agreement measures and bootstrap methods of Chapter 4 apply directly.
Cohen’s Kappa
Cohen’s kappa measures agreement between two annotators (here, LLM and human) while correcting for chance agreement. Raw accuracy can be misleading: if 90% of reviews are positive, an annotator that always guesses “positive” achieves 90% accuracy without understanding anything. Kappa removes this inflation by comparing observed agreement to the agreement expected by random guessing, yielding a more honest measure of annotator quality:
from sklearn.metrics import cohen_kappa_score, accuracy_score
# Real annotations: gemma3:12b sentiment labels vs. the gold label (derived
# from each review's star rating) for 74 reviews from the shared Chapter 6
# corpus. These are the exact per-cell counts of the agreement matrix in
# Figure 6.4.3; the runnable version reads them from a frozen fixture so the
# numbers reproduce exactly (see scripts/ch6/ch6_4_annotation/03_quality_control.py).
human_labels = ["pos"] * 24 + ["neu"] * 23 + ["neg"] * 27 # gold (from rating)
llm_labels = (["pos"] * 18 + ["neu"] * 5 + ["neg"] * 1 + # gold = positive (24)
["pos"] * 2 + ["neu"] * 9 + ["neg"] * 12 + # gold = neutral (23)
["pos"] * 1 + ["neu"] * 1 + ["neg"] * 25) # gold = negative (27)
accuracy = accuracy_score(human_labels, llm_labels)
kappa = cohen_kappa_score(human_labels, llm_labels, labels=["pos", "neu", "neg"])
print(f"Accuracy: {accuracy:.3f}")
print(f"Cohen's kappa: {kappa:.3f}")
print(f"\nInterpretation:")
if kappa > 0.8:
print(" Almost perfect agreement")
elif kappa > 0.6:
print(" Substantial agreement")
elif kappa > 0.4:
print(" Moderate agreement")
else:
print(" Fair or poor agreement")
Accuracy: 0.703
Cohen's kappa: 0.548
Interpretation:
Moderate agreement
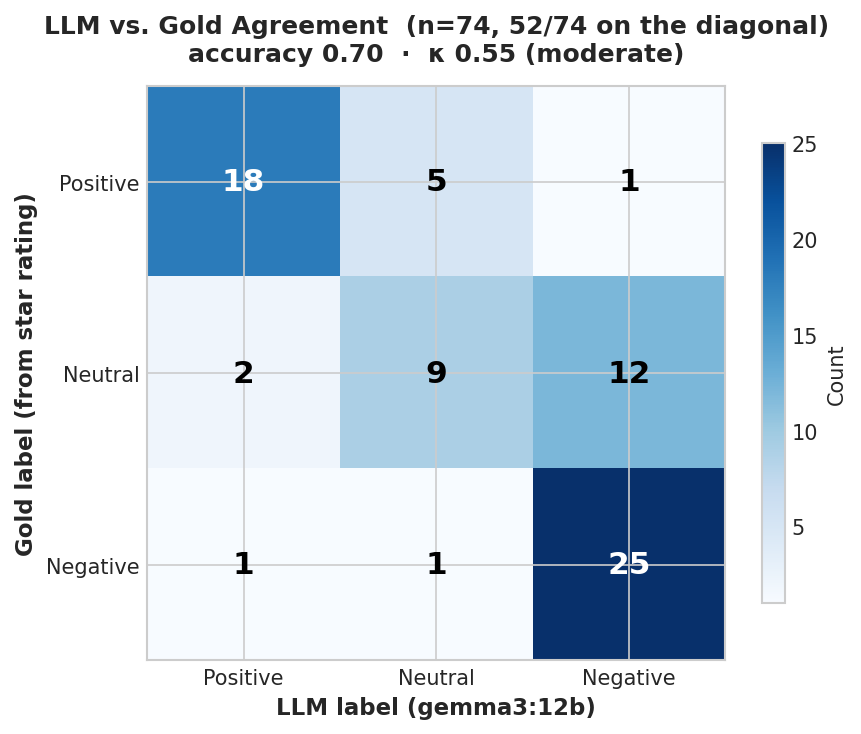
Fig. 228 Figure 6.4.3: Agreement confusion matrix: LLM (gemma3:12b) vs. gold labels for 74 reviews. The diagonal (52 of 74) is agreement; the single largest error is gold-neutral reviews labeled negative (12 of 23). The neutral (3-star) class is what drags kappa down.
Cohen’s kappa corrects accuracy for chance: with three classes, two raters who never read a word still agree roughly a third of the time, so a respectable-looking 0.70 accuracy becomes only a moderate 0.55 once that baseline is removed. The gap is the honest signal—and it points straight at the neutral class as the place to spend human review.
Consensus via Multiple Runs
Since LLM outputs are stochastic, running the same annotation multiple times and taking the majority vote improves reliability—a technique called self-consistency, which we will develop more fully in Section 6.6:
from collections import Counter
def annotate_consensus(text, annotate_fn, n_runs=3):
"""Run annotation multiple times and take majority vote."""
labels = [annotate_fn(text) for _ in range(n_runs)]
counter = Counter(labels)
majority_label, majority_count = counter.most_common(1)[0]
agreement = majority_count / n_runs
return {
"label": majority_label,
"agreement": agreement,
"all_labels": labels,
}
result = annotate_consensus(
"The product is decent but overpriced.",
annotate_sentiment, n_runs=5
)
print(f"Label: {result['label']}")
print(f"Agreement: {result['agreement']:.0%}")
print(f"All runs: {result['all_labels']}")
Label: neutral
Agreement: 60%
All runs: ['neutral', 'negative', 'neutral', 'neutral', 'negative']
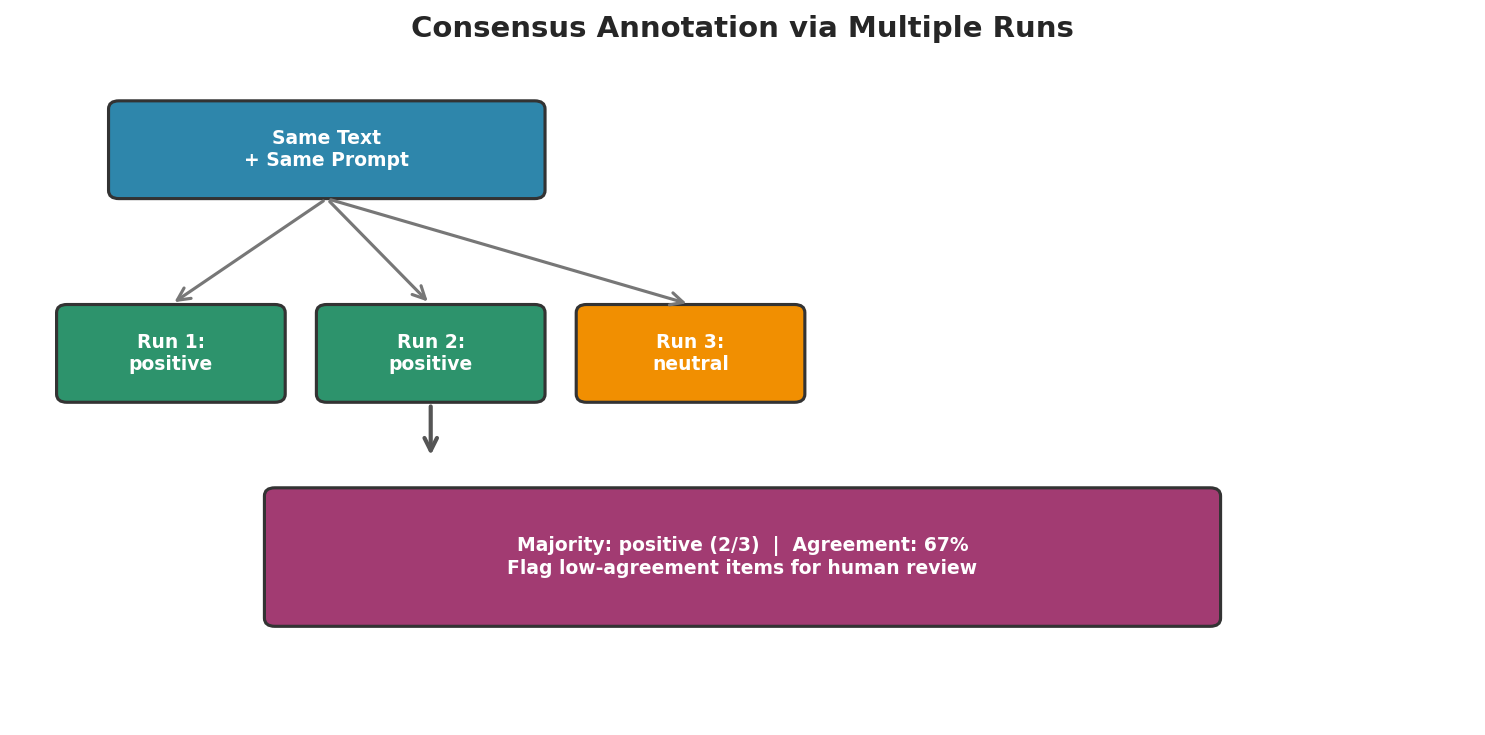
Fig. 229 Figure 6.4.4: Consensus annotation runs the same prompt multiple times and takes the majority vote. Low-agreement items (e.g., 60% agreement) can be flagged for human review.
Items with low consensus agreement are candidates for human review—they represent genuinely ambiguous cases or cases where the LLM is unreliable.
Bootstrap CI on Agreement
To quantify uncertainty in our agreement metric, we apply the bootstrap:
import numpy as np
def bootstrap_kappa(human_labels, llm_labels, n_bootstrap=1000, seed=42,
labels=("pos", "neu", "neg")):
"""Bootstrap confidence interval for Cohen's kappa."""
rng = np.random.default_rng(seed)
n = len(human_labels)
kappas = []
for _ in range(n_bootstrap):
idx = rng.choice(n, size=n, replace=True)
h_boot = [human_labels[i] for i in idx]
l_boot = [llm_labels[i] for i in idx]
try:
k = cohen_kappa_score(h_boot, l_boot, labels=list(labels))
kappas.append(k)
except ValueError:
continue
ci_low = np.percentile(kappas, 2.5)
ci_high = np.percentile(kappas, 97.5)
return {
"mean_kappa": np.mean(kappas),
"ci_95": (ci_low, ci_high),
"se": np.std(kappas),
}
result = bootstrap_kappa(human_labels, llm_labels)
print(f"Cohen's kappa: {result['mean_kappa']:.3f}")
print(f"95% CI: [{result['ci_95'][0]:.3f}, {result['ci_95'][1]:.3f}]")
print(f"SE: {result['se']:.3f}")
Cohen's kappa: 0.547
95% CI: [0.402, 0.691]
SE: 0.077
The confidence interval runs from 0.40 to 0.69—it straddles the 0.6 “substantial” threshold, so we cannot honestly claim substantial agreement: the labels are only moderate, and the lower half of the interval is barely above “fair.” The decision this licenses is not “trust and proceed” but “use with care”—route the ambiguous cases, above all the 3-star/neutral reviews, to human review before relying on the labels at scale. Reporting the whole interval rather than a bare point estimate is exactly the statistical rigor that distinguishes a data science approach to annotation from simply trusting the LLM output.
When LLM Annotation Works and When It Does Not
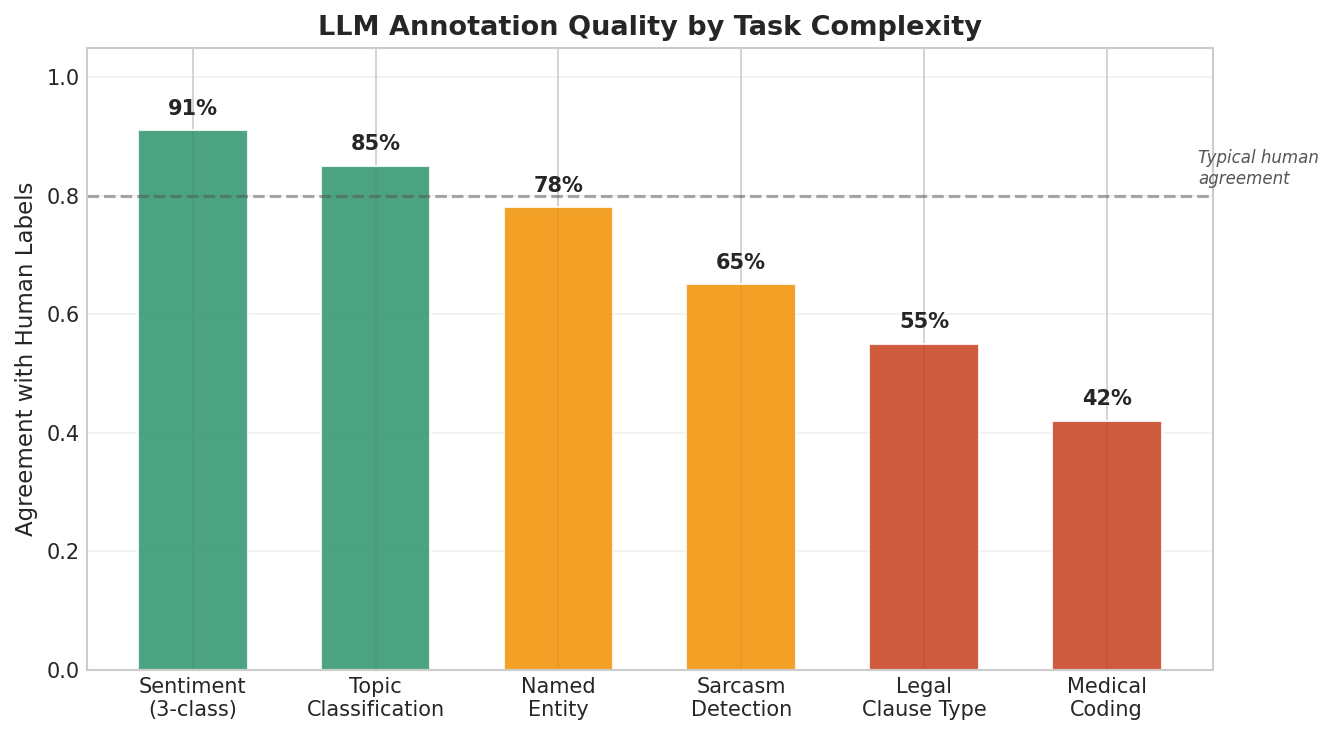
Fig. 230 Figure 6.4.5: LLM annotation quality varies dramatically by task type. Simple, well-defined tasks (sentiment, topic classification) achieve near-human agreement. Tasks requiring domain expertise (legal, medical) fall well below acceptable thresholds.
LLM Annotation Works Well When
The task is well-defined: Clear categories, unambiguous criteria (e.g., sentiment, language detection).
The labels are surface-level: They can be determined from the text alone without external knowledge.
Human agreement is high: If humans agree 90%+ on the task, LLMs typically match.
The categories are common: Sentiment, topic, and named entities are well-represented in training data.
LLM Annotation Fails When
Domain expertise is required: Medical coding (ICD-10), legal clause interpretation, and scientific taxonomy require specialized knowledge the model may lack.
Subjectivity is high: Sarcasm, irony, and cultural context are difficult for LLMs.
The annotation requires reasoning about context not in the text: If labeling requires knowledge of the author’s intent, the broader conversation, or external events.
Stakes are high: In medical, legal, or safety-critical applications, LLM errors can have serious consequences.
Hybrid Approaches
The most effective strategy is often a hybrid:
LLM first pass: Annotate the full dataset with the LLM.
Uncertainty filtering: Flag items where consensus across repeated runs is low; the model’s self-reported confidence can serve as a secondary flag, but it is generated text, not a measured probability (Section 6.8).
Human review: Send flagged items to human annotators.
Bias correction: Use the human-reviewed subset to measure and correct systematic biases in the LLM annotations.
This approach can reduce human annotation effort by 70–90% while maintaining quality near human-only levels.
Chapter 6.4 Exercises: Data Annotation
Exercise 6.4.1 — Sentiment Annotation Pipeline with Kappa
Create 30 short text reviews with known sentiment (10 positive, 10 negative, 10 neutral). These are your ground-truth labels.
Build an annotation pipeline using
annotate_sentiment()to label all 30 reviews.Compute accuracy and Cohen’s kappa against your ground truth.
Compute a 95% bootstrap CI on kappa (1,000 resamples). Is the agreement significantly above the “moderate” threshold (kappa > 0.4)?
Solution
from sklearn.metrics import cohen_kappa_score, accuracy_score
import numpy as np
# Ground truth dataset
texts_pos = [
"Best product I've ever bought!", "Highly recommend!",
"Absolutely love it!", "Perfect in every way.",
"Outstanding quality!", "Five stars easily.",
"Couldn't be happier!", "Exceeded my expectations.",
"A must-buy!", "Wonderful experience.",
]
texts_neg = [
"Terrible quality.", "Worst purchase ever.",
"Complete waste of money.", "Very disappointed.",
"Broke immediately.", "Awful, avoid at all costs.",
"Returning this.", "Regret buying this.",
"Total junk.", "Horrible experience.",
]
texts_neu = [
"The package arrived on time.", "Standard product.",
"It works.", "Average quality.", "As described.",
"Nothing special.", "Meets basic needs.",
"Standard delivery.", "Functional.",
"About what you'd expect.",
]
all_texts = texts_pos + texts_neg + texts_neu
ground_truth = (["positive"] * 10 + ["negative"] * 10 +
["neutral"] * 10)
llm_labels = [annotate_sentiment(t) for t in all_texts]
acc = accuracy_score(ground_truth, llm_labels)
kappa = cohen_kappa_score(ground_truth, llm_labels)
print(f"Accuracy: {acc:.3f}")
print(f"Kappa: {kappa:.3f}")
# Bootstrap CI
result = bootstrap_kappa(ground_truth, llm_labels,
labels=("positive", "neutral", "negative"))
print(f"95% CI on kappa: [{result['ci_95'][0]:.3f}, "
f"{result['ci_95'][1]:.3f}]")
print(f"Significantly above 0.4: {result['ci_95'][0] > 0.4}")
Exercise 6.4.2 — Structured NER with Precision/Recall
Write 10 sentences containing named entities (people, organizations, locations, dates). Document the expected entities for each sentence.
Use the
annotate_ner()function to extract entities from each sentence.Compute precision (what fraction of extracted entities are correct) and recall (what fraction of expected entities were found).
Identify the most common error type: false positives (extracted but incorrect) or false negatives (missed entities).
Solution
test_sentences = [
("Dr. Smith visited Purdue University in January 2024.",
[("Dr. Smith", "PERSON"), ("Purdue University", "ORGANIZATION"),
("January 2024", "DATE")]),
("Microsoft CEO Satya Nadella spoke in New York.",
[("Microsoft", "ORGANIZATION"), ("Satya Nadella", "PERSON"),
("New York", "LOCATION")]),
]
total_tp, total_fp, total_fn = 0, 0, 0
for text, expected in test_sentences:
extracted = annotate_ner(text)
extracted_entities = {e["entity"] for e in extracted}
expected_entities = {e[0] for e in expected}
tp = len(extracted_entities & expected_entities)
fp = len(extracted_entities - expected_entities)
fn = len(expected_entities - extracted_entities)
total_tp += tp
total_fp += fp
total_fn += fn
precision = total_tp / (total_tp + total_fp) if (total_tp + total_fp) > 0 else 0
recall = total_tp / (total_tp + total_fn) if (total_tp + total_fn) > 0 else 0
print(f"Precision: {precision:.3f}")
print(f"Recall: {recall:.3f}")
Exercise 6.4.3 — Annotation Quality: Minimal vs. Detailed Prompts
Write a minimal sentiment annotation prompt (just “Classify as positive/negative/neutral”) and a detailed prompt (with definitions, examples, and edge case instructions).
Annotate the same 30 reviews from Exercise 6.4.1 with both prompts.
Compute Cohen’s kappa for each prompt against ground truth. Does the detailed prompt significantly outperform the minimal one?
Use a bootstrap test: compute 1,000 bootstrap kappa values for each prompt and test whether the difference in kappa is significantly different from zero.
Solution
MINIMAL_PROMPT = """Classify: positive, negative, or neutral.
Text: {text}
Label:"""
DETAILED_PROMPT = """Classify the sentiment of this customer review.
Definitions:
- positive: Expresses satisfaction, approval, recommendation, or happiness
- negative: Expresses dissatisfaction, complaints, frustration, or warnings
- neutral: Factual, balanced, or lacks strong emotional content
Edge cases:
- Mixed reviews (both good and bad): classify by overall tone
- Sarcasm: classify by actual intent, not surface words
Respond with ONLY: positive, negative, or neutral
Review: {text}
Label:"""
def annotate_with_prompt(text, template):
prompt = template.format(text=text)
return ai.chat(prompt).strip().lower()
labels_minimal = [annotate_with_prompt(t, MINIMAL_PROMPT) for t in all_texts]
labels_detailed = [annotate_with_prompt(t, DETAILED_PROMPT) for t in all_texts]
k_min = cohen_kappa_score(ground_truth, labels_minimal)
k_det = cohen_kappa_score(ground_truth, labels_detailed)
print(f"Minimal prompt kappa: {k_min:.3f}")
print(f"Detailed prompt kappa: {k_det:.3f}")
# Bootstrap difference test
n = len(ground_truth)
diffs = []
for _ in range(1000):
idx = np.random.choice(n, size=n, replace=True)
gt_b = [ground_truth[i] for i in idx]
min_b = [labels_minimal[i] for i in idx]
det_b = [labels_detailed[i] for i in idx]
try:
d = cohen_kappa_score(gt_b, det_b) - cohen_kappa_score(gt_b, min_b)
diffs.append(d)
except ValueError:
continue
ci = (np.percentile(diffs, 2.5), np.percentile(diffs, 97.5))
print(f"Kappa difference 95% CI: [{ci[0]:.3f}, {ci[1]:.3f}]")
print(f"Significant: {'Yes' if ci[0] > 0 else 'No'}")
Exercise 6.4.4 — When LLMs Fail: Domain Expertise Tasks
Create 10 text samples that require domain expertise to annotate correctly (e.g., classify medical text by severity, or legal text by clause type). You may use simplified examples.
Annotate them with an LLM and compare against your expert labels.
Create 10 comparable samples from a general domain (e.g., general sentiment). Annotate these too.
Compare kappa between the domain-specific and general-domain tasks. Quantify how much LLM annotation quality degrades when domain expertise is required.
Solution
# Domain-specific: medical severity
medical_texts = [
"Patient reports mild headache after exercise.",
"Acute chest pain radiating to left arm.",
"Routine follow-up, all vitals normal.",
"Severe allergic reaction, anaphylaxis suspected.",
"Minor skin rash, no systemic symptoms.",
]
medical_truth = ["low", "high", "low", "high", "low"]
MEDICAL_PROMPT = """Classify the clinical severity of this note.
Categories: high (immediate attention), low (routine)
Respond with ONLY: high or low
Note: {text}
Severity:"""
med_labels = [ai.chat(MEDICAL_PROMPT.format(text=t)).strip().lower()
for t in medical_texts]
# General domain: sentiment
general_texts = [
"Great product!", "Terrible quality.",
"It's okay.", "Love it!", "Waste of money.",
]
general_truth = ["positive", "negative", "neutral", "positive", "negative"]
gen_labels = [annotate_sentiment(t) for t in general_texts]
k_med = cohen_kappa_score(medical_truth, med_labels)
k_gen = cohen_kappa_score(general_truth, gen_labels)
print(f"Medical (domain) kappa: {k_med:.3f}")
print(f"General (sentiment) kappa: {k_gen:.3f}")
print(f"Degradation: {k_gen - k_med:.3f}")
Transition to What Follows
We now have tools for generating embeddings (Section 6.2), preprocessing text (Section 6.3), and annotating data at scale. But how do we know when to trust these LLM outputs? In Section 6.8, we develop systematic methods for assessing reliability and quantifying uncertainty in LLM-assisted workflows.
Key Takeaways
Key Takeaways 📝
LLM annotation can replace or supplement human annotation at dramatically lower cost and faster speed, but it is not universally reliable.
Prompt design is the annotation guideline — clear category definitions, output format constraints, and edge case instructions directly determine annotation quality.
Cohen’s kappa measures agreement while accounting for chance, and bootstrap CIs quantify uncertainty in this agreement.
Consensus annotation (multiple LLM runs with majority voting) improves reliability and flags genuinely ambiguous cases for human review.
LLM annotation degrades with task complexity — simple, well-defined tasks approach human quality; domain-expert tasks often fall short. Always validate against a human-labeled sample before trusting LLM annotations at scale.