Section 6.10 Chapter Summary
This chapter developed the practical skills for integrating large language models into data science workflows. We began with the conceptual foundations of how LLMs work and progressed through the complete toolkit: generating embeddings, preprocessing text, annotating data, building RAG systems, engineering prompts, calling external tools, evaluating reliability, and navigating responsible AI concerns. Throughout, we connected these new techniques to the statistical methods from Chapters 1–5, ensuring that LLMs augment—rather than replace—rigorous quantitative reasoning.
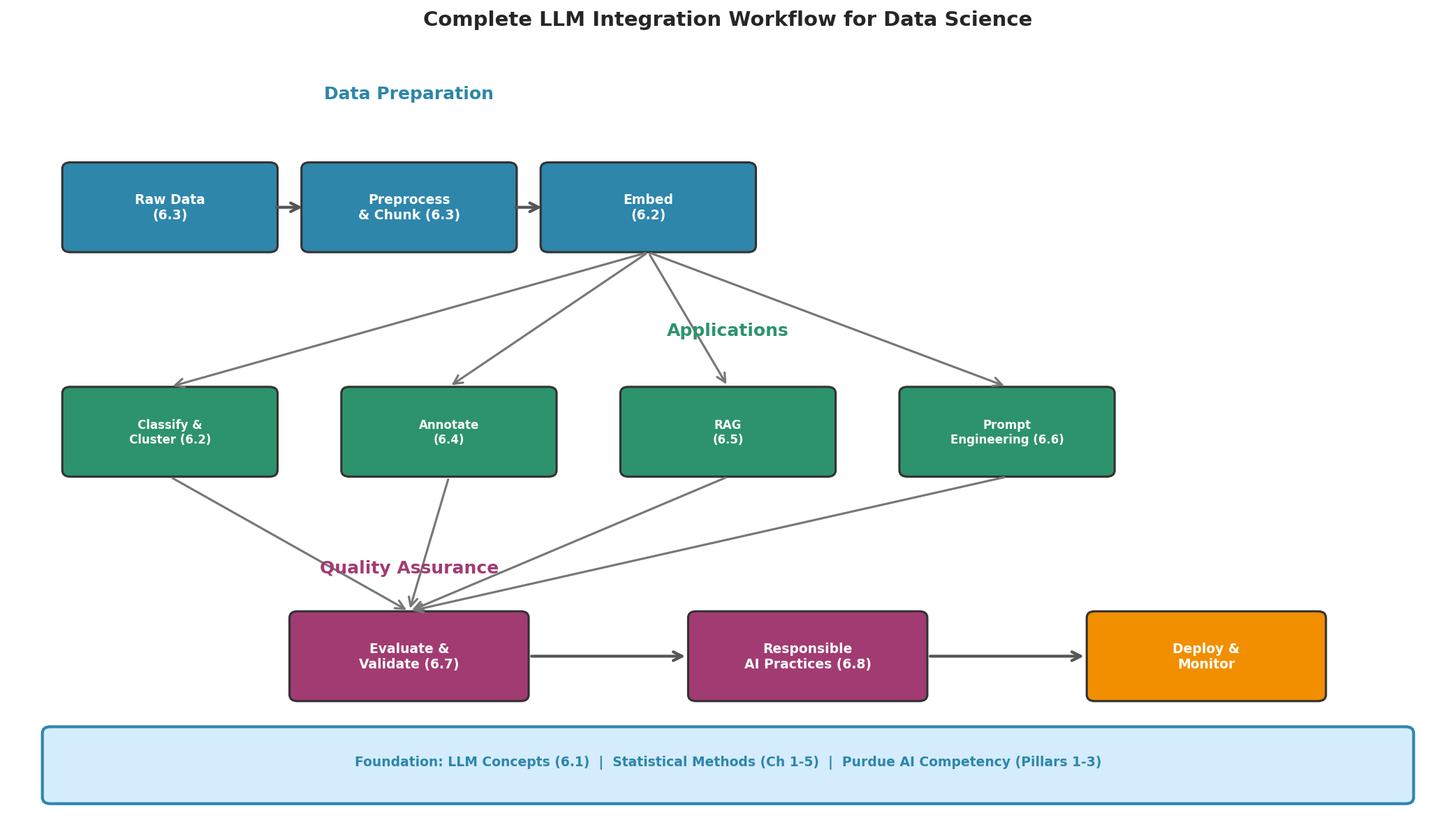
Fig. 251 Figure 6.10.1: The complete LLM integration workflow for data science. Raw data flows through preprocessing and embedding, branches into applications (classification, annotation, RAG, prompt engineering), and passes through evaluation and responsible AI practices before deployment.
Section-by-Section Recap
Section 6.1: LLM Foundations introduced the transformer architecture (attention as weighted voting), the pre-training/fine-tuning/in-context learning paradigm, and the landscape of model families. We set up GenAI Studio and wrote our first API calls.
Section 6.2: Embeddings and Feature Extraction transformed text into dense numerical vectors. We computed cosine similarity, decoded what each principal component encodes (length, sentiment, category), trained classifiers on embedding features, and used bootstrap CIs to quantify uncertainty in embedding-derived regression coefficients.
Section 6.3: Text Preprocessing developed the pipeline between raw data and LLM input: tokenization, context window management, and chunking strategies (fixed-size, overlap, semantic).
Section 6.4: Data Annotation used LLMs to label text at scale. We designed annotation prompts, built batch pipelines, and evaluated quality with Cohen’s kappa and bootstrap confidence intervals.
Section 6.5: Retrieval-Augmented Generation grounded LLM responses in external documents. We built RAG both via GenAI Studio’s knowledge base API and manually from scratch (chunk → embed → retrieve → generate).
Section 6.6: Prompt Engineering treated prompts as code—versioned, tested, and iterated. We developed systematic techniques: structured instructions, few-shot examples, chain-of-thought reasoning, and self-consistency (framed as bootstrap resampling).
Section 6.7: Tool Use connected models to live data and exact computation through function calling: declaring a tool with @tool, letting the model request a call, running it in our own code, and returning the result to ground the answer—together with the safeguards that executing model-chosen actions demands.
Section 6.8: Reliability and Evaluation measured LLM trustworthiness through consistency assessment, LLM-as-judge evaluation, and self-consistency uncertainty quantification.
Section 6.9: Responsible AI Practices addressed privacy (PII detection/redaction), bias (differential treatment testing), transparency (disclosure frameworks), and ethical frameworks (NIST AI RMF).
Putting it all together. These capabilities compose. A realistic workflow engineers a prompt (Section 6.6) to steer the model, grounds it in your own documents with RAG (Section 6.5), lets it call tools (Section 6.7) for computation and live data, then evaluates the result (Section 6.8) and applies responsible-AI safeguards (Section 6.9). Chaining tool calls into an autonomous loop—where the model decides each next action itself—is an agent: a powerful but less predictable frontier that builds directly on the single-tool-use foundation from this chapter.
GenAI Studio Quick Reference
Method |
Description |
|---|---|
|
Initialize client (uses GENAI_STUDIO_API_KEY if not provided) |
|
Set the model for subsequent calls |
|
Simple chat, returns string |
|
Chat with metadata (tokens, model info) |
|
Streaming chat, yields chunks |
|
Multi-turn conversation from message list |
|
Multi-turn conversation from |
|
Generate embedding vector(s) |
|
Embeddings with metadata |
|
Cosine similarity between two texts |
|
Cosine similarity between two vectors (static) |
|
Upload file for RAG |
|
Create a knowledge base |
|
Link file to knowledge base |
|
RAG-augmented chat |
Connections to Earlier Chapters
Chapter |
Concept |
Application in Chapter 6 |
|---|---|---|
Ch 2 |
Monte Carlo simulation |
Self-consistency runs multiple reasoning paths (analogous to Monte Carlo trials) |
Ch 3 |
Linear regression |
Embedding PCA components as covariates in OLS |
Ch 3 |
Hypothesis testing |
Testing annotation quality against thresholds |
Ch 4 |
Bootstrap |
CIs on agreement metrics, embedding coefficients, and self-consistency rates |
Ch 4 |
Cross-validation |
Evaluating embedding-based classifiers |
Ch 4 |
Permutation tests |
A/B testing prompt variants |
Ch 5 |
Posterior uncertainty |
Self-consistency agreement as an uncertainty heuristic (stability, not correctness) |
Purdue AI Working Competency Mapping
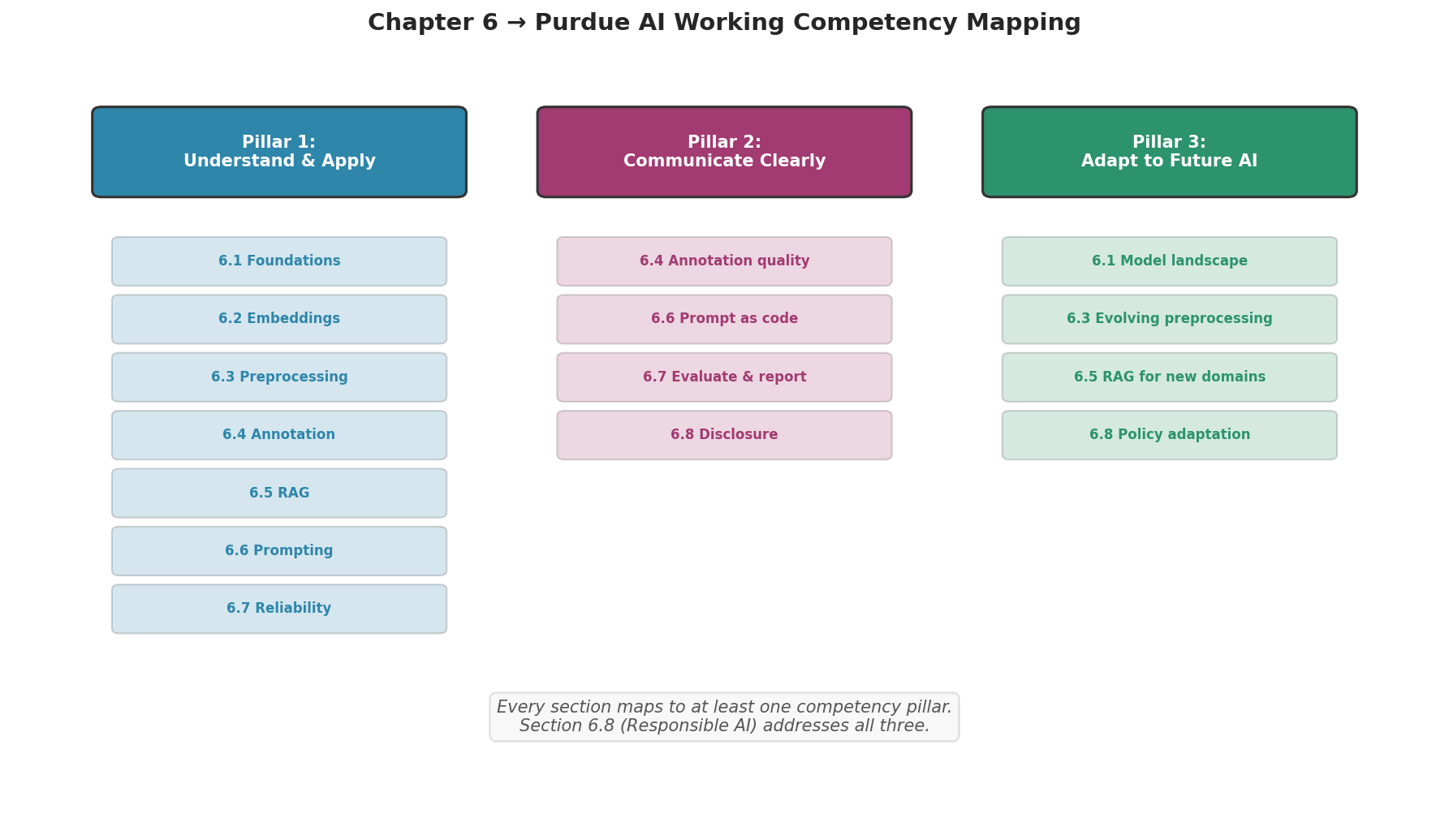
Fig. 252 Figure 6.10.2: Each section of Chapter 6 maps to one or more pillars of Purdue’s AI Working Competency Requirement.
Section |
Pillar 1: Understand & Apply |
Pillar 2: Communicate |
Pillar 3: Adapt |
|---|---|---|---|
6.1 Foundations |
✓ (core) |
||
6.2 Embeddings |
✓ |
||
6.3 Preprocessing |
✓ |
✓ |
|
6.4 Annotation |
✓ |
✓ |
|
6.5 RAG |
✓ |
✓ |
|
6.6 Prompt Engineering |
✓ |
✓ |
|
6.7 Tool Use |
✓ |
✓ |
|
6.8 Reliability |
✓ |
✓ |
|
6.9 Responsible AI |
✓ |
✓ (core) |
✓ |
Common Pitfalls Checklist
Pitfall |
Remedy |
|---|---|
Trusting LLM output without validation |
Always evaluate against ground truth or human labels (Section 6.8) |
Sending PII to external APIs |
Run PII detection/redaction before any API call (Section 6.9) |
Using raw LLM confidence scores |
Validate self-consistency against ground truth—use agreement to triage, not as a probability; LLMs are typically overconfident (Section 6.8) |
Fixed chunk size for all documents |
Experiment with chunk sizes; use semantic chunking when structure matters (Section 6.3) |
Ignoring prompt version control |
Treat prompts as code: version, test, and document (Section 6.6) |
No bias testing before deployment |
Run differential treatment probes across demographic groups (Section 6.9) |
Using LLM annotation for domain-expert tasks |
Validate with Cohen’s kappa; use hybrid human+LLM workflows (Section 6.4) |
Omitting AI disclosure |
Disclose at the level matching AI’s contribution (Section 6.9) |
End-to-End Example
The program below strings together five of the chapter’s techniques—preprocessing (Section 6.3), embeddings (Section 6.2), self-consistent annotation (Sections 6.4 and 6.6), evaluation against ground truth (Section 6.8), and disclosure (Section 6.9)—into one minimal, runnable workflow:
from genai_studio import GenAIStudio
import numpy as np
from collections import Counter
from sklearn.metrics import cohen_kappa_score
ai = GenAIStudio()
ai.select_model("gemma3:12b")
# 1. Preprocess (Section 6.3)
import re
def clean(text):
text = re.sub(r'<[^>]+>', '', text)
return re.sub(r'\s+', ' ', text).strip()
# 2. Embed (Section 6.2)
reviews = ["Great product!", "Terrible quality.", "It works fine.",
"Best purchase ever!", "Waste of money."]
cleaned = [clean(r) for r in reviews]
embeddings = ai.embed(cleaned, model="llama3.2:latest") # gemma3 has no embedding endpoint; use an embed-capable model (3072-d)
print(f"Embedded {len(embeddings)} reviews ({len(embeddings[0])} dims)")
# 3. Annotate with self-consistency (Sections 6.4 + 6.6)
PROMPT = ("Classify as positive, negative, or neutral. "
"Respond with ONLY one word.\nText: {text}\nLabel:")
annotations = []
for text in cleaned:
runs = [ai.chat(PROMPT.format(text=text)).strip().lower()
for _ in range(5)]
majority = Counter(runs).most_common(1)[0][0]
agreement = Counter(runs).most_common(1)[0][1] / 5
annotations.append({"label": majority, "confidence": agreement})
print(f" [{majority:>8}] ({agreement:.0%}) {text}")
# 4. Evaluate (Section 6.8)
ground_truth = ["positive", "negative", "neutral", "positive", "negative"]
predicted = [a["label"] for a in annotations]
kappa = cohen_kappa_score(ground_truth, predicted)
print(f"\nCohen's kappa: {kappa:.3f}")
# 5. Disclose (Section 6.9)
print("\nDisclosure: Labels generated by gemma3:12b via Purdue GenAI Studio "
f"with 5-run self-consistency. Agreement with ground truth: "
f"kappa = {kappa:.3f}.")
Embedded 5 reviews (3072 dims)
[positive] (100%) Great product!
[negative] (100%) Terrible quality.
[ neutral] (80%) It works fine.
[positive] (100%) Best purchase ever!
[negative] (100%) Waste of money.
Cohen's kappa: 1.000
Disclosure: Labels generated by gemma3:12b via Purdue GenAI Studio with 5-run self-consistency. Agreement with ground truth: kappa = 1.000.
Learning Outcomes Checklist
Upon completing this chapter, verify that you can:
✓ |
Outcome |
Key Section |
|---|---|---|
☐ |
Explain transformer architecture at a conceptual level |
6.1 |
☐ |
Generate embeddings and compute cosine similarity |
6.2 |
☐ |
Build preprocessing pipelines with appropriate chunking strategies |
6.3 |
☐ |
Design annotation prompts and evaluate quality with Cohen’s kappa |
6.4 |
☐ |
Implement RAG pipelines (SDK and manual) |
6.5 |
☐ |
Apply systematic prompt design: few-shot, CoT, self-consistency |
6.6 |
☐ |
Use tool calling: declare a tool, judge when it is warranted, apply safeguards |
6.7 |
☐ |
Assess reliability through consistency, self-consistency uncertainty, and LLM-as-judge |
6.8 |
☐ |
Navigate privacy, bias, and disclosure concerns |
6.9 |
☐ |
Integrate LLM techniques with statistical methods from Chapters 1–5 |
All |
Further Reading
LLM Foundations and Architecture
Raschka, Build a Large Language Model (From Scratch) — for those who want deeper architectural understanding
Alammar, The Illustrated Transformer (blog) — visual explanations of attention
Bommasani et al., “On the Opportunities and Risks of Foundation Models” (2021)
Embeddings and Applications
Alammar & Grootendorst, Hands-On Large Language Models — practical embedding techniques
Jurafsky & Martin, Speech and Language Processing (3rd ed.) — comprehensive NLP reference
How Concepts Are Encoded (Interpretability)
Elhage et al., “Toy Models of Superposition” (Anthropic, 2022) — concepts share overlapping, non-orthogonal directions (“superposition”), which is why naive vector arithmetic on embeddings is noisy
Templeton et al., “Scaling Monosemanticity” (Anthropic, 2024) — sparse autoencoders extract interpretable feature directions from Claude that can be added or clamped to steer behavior
Anthropic, “Persona Vectors” (2025) — high-level traits encoded as linear directions you can add or subtract to control a model
RAG and Production Systems
Chip Huyen, AI Engineering — production LLM systems
Peters & Bouchard, Building LLMs for Production — RAG chapters
Gao et al., “Retrieval-Augmented Generation for Large Language Models: A Survey” (2024)
Prompt Engineering
Schulhoff et al., “The Prompt Report” (2024) — comprehensive survey
Wei et al., “Chain-of-Thought Prompting” (2022)
Wang et al., “Self-Consistency Improves Chain of Thought Reasoning” (2022)
Reliability and Evaluation
Liang et al., “Holistic Evaluation of Language Models (HELM)” (2022)
Farquhar et al., “Detecting Hallucinations in Large Language Models” (2024)
Responsible AI
Narayanan & Kapoor, AI Snake Oil — critical perspective on AI capabilities and limitations
NIST AI Risk Management Framework (AI RMF 1.0)
Final Perspective
Large language models are the most versatile tools to enter the data scientist’s toolkit in a generation. They transform unstructured text into analyzable features, annotate data at unprecedented speed, retrieve information from domain-specific knowledge bases, and assist with analytical reasoning. But they are tools, not oracles. They hallucinate, they encode biases, they require careful evaluation, and they demand transparent disclosure.
The data scientist’s job is not to use LLMs uncritically—it is to use them well. This means applying the statistical thinking from earlier chapters: validating outputs, quantifying uncertainty, testing for bias, and communicating limitations honestly. The bootstrap confidence interval you compute on LLM-annotated data is only as meaningful as the annotation quality you verified. The regression model you train on embedding features is only as trustworthy as the evaluation protocol you designed.
Throughout this chapter, we have treated LLMs not as black boxes but as components in analytical workflows subject to the same rigor as any other tool. This is the perspective that will serve you as models evolve, APIs change, and new capabilities emerge. The specific models and APIs will change; the discipline of careful, skeptical, statistically-grounded integration will not.
That change will not be uniform. Expect the frontier/open-weight boundary itself to keep moving: capabilities that today exist only behind proprietary APIs will keep migrating into open-weight models through distillation and open releases, while frontier systems push further into the long-horizon agentic work that only centrally served scale supports. Neither trend invalidates anything in this chapter. The workflows you built—embedding, annotating, retrieving, evaluating—were chosen because they rest on deployment constraints you control (privacy, cost, reproducibility) rather than on any particular model’s position on a leaderboard. When the landscape shifts again, and it will, re-run the same decision you learned in Section 6.1: constraints first, capability second.
Key Takeaways
Key Takeaways 📝
LLMs are powerful additions to the data science toolkit, not replacements for statistical thinking. Embeddings, annotation, RAG, and prompt engineering each solve specific problems.
All LLM outputs must be evaluated — consistency, accuracy, and uncertainty checks are prerequisites for responsible use, not optional extras.
Embeddings bridge NLP and statistics — once text is embedded, every technique from Chapters 1–5 applies: regression, bootstrap, cross-validation, hypothesis testing.
Responsible AI is not optional — privacy, bias, and disclosure concerns are integral to any LLM deployment. Purdue’s AI Working Competency Requirement makes this a graduation standard.
The discipline matters more than the model — specific LLMs will evolve, but the practice of careful evaluation, uncertainty quantification, and transparent reporting will remain essential.